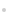ЈЁЦР№ъГсәҪҙуС§јЖЛг»ъҝЖС§УлјјКхС§ФәЈ¬МмҪт 300300Ј©
0 ТэСФ
өГТжУЪҙ«ёРЖчј°јаҝШјјКхөДҪшІҪЈ¬ПЦҙъ№ӨТөЙиұёөДЙъІъФЛРРЧҙМ¬әНФЛРР»·ҫіДЬ№»ұ»КөКұјЗВјәНёРЦӘЈ¬»эАЫІўІъЙъБЛәЈБҝ¶аО¬КұјдРтБРЈЁMTS,multivariate time seriesЈ©КэҫЭ[1]ЎЈАэИзЈ¬ФЖ·юОсЖчөДCPUАыУГВКЎўДЪҙжХјУГВКЎўНшВзБчБҝөИјаІвКэҫЭЈ¬әҪҝХЖчөДЛЩ¶ИЎўёЯ¶ИЎўё©СцҪЗ¶ИөИҙ«ёРЖчКэҫЭЈ¬·ҙУіәҪМмЖчФЛРРЧҙМ¬өДТЈІвРЕәЕЈ¬№Өі§ЙъІъ»ъЖчөДОВ¶ИЎўЧӘЛЩөИјаІвКэҫЭЎЈХвР©MTS КэҫЭөДТміЈИЎЦөЖ¬¶ОНщНщТвО¶ЧЕЙиұё№КХПЎўІЩЧчИЛФұК§ОуөИМШКвЗйҝцөД·ўЙъЈ¬ТІҝЙДЬұнКҫЙъІъ»·ҫіЦРҙжФЪТюРФ°ІИ«Тю»јЎЈХвР©ТміЈИзІ»ДЬұ»УРР§К¶ұрЈ¬әЬҝЙДЬФміЙҫӯјГЛрК§ЎЈ№ӨТөБмУтMTS КэҫЭУРИзПВМШөгЈәМеБҝҙуЎўБ¬РшІЙСщЎўјЫЦөГЬ¶ИөНЎў¶ҜМ¬РФЗҝЈ»MTS ёчО¬¶ИЦ®јдҫЯУРёҙФУөДКұҝХсоәП№ШПөЈ»№ӨТөЙиұёНЁ№эЖдИнјюҝШЦЖВЯјӯНщНщУлЖдФЛРР»·ҫіЎўІЩЧчИЛФұј°Па№ШЙиұёПөНіУРёҙФУҪ»»ҘЈ¬·ҙУіЖдФЛРРЧҙМ¬өДMTS ИЎЦөҫЯУРЛж»ъРФ[2]ЎЈБнНвЈ¬УЙУЪ№ӨТөБмУтMTS ТміЈСщұҫПа¶ФҪПЙЩЎўұкЧўТміЈҙъјЫҪПёЯЈ¬СРҫҝХЯҙу¶а№ШЧў»щУЪОЮја¶ҪөДMTSТміЈјмІв·Ҫ·ЁЎЈҙ«НіөДЦчіЙ·Ц·ЦОцЎўёЯЛ№»мәПДЈРНЎўТ»АаЦ§іЦПтБҝ»ъөИ»ъЖчС§П°·Ҫ·ЁОЮ·ЁәЬәГөШҪЁДЈ№ӨТөБмУтMTS КэҫЭөДёҙФУРФЦКЎЈУЙУЪЙо¶ИС§П°ЗҝҙуөДКэҫЭұнХчДЬБҰЈ¬ҪьДкАҙЈ¬»щУЪЙо¶ИС§П°өДОЮја¶ҪMTS ТміЈјмІвСРҫҝөГөҪБЛ№г·ә№ШЧўЎЈMTS ТміЈјмІв°ьАЁРтБРј¶әНЛІКұј¶ТміЈ·ўПЦЎЈРтБРј¶ТміЈ[3-5]КЗЦёMTS СщұҫХыёцРтБР»тЖдЧУРтБРЗшұрУЪ¶аКэСщұҫЎЈЛІКұј¶ТміЈКЗЦёФЪДіёцКұјдөг»т¶МКұјдҙ°ДЪөДТміЈЎЈұҫОДДЈРНКфУЪЛІКұј¶ТміЈјмІвДЈРНЎЈ
О§ИЖИзәОҪЁДЈ№ӨТөБмУтMTS КұРтТААөРФәНЛж»ъРФЈ¬СРҫҝХЯМбіцБЛТ»Р©Йо¶ИС§П°ДЈРН[2,6-10]ЎЈХвР©ДЈРНөДСөБ·ДҝұкҫщОӘС§П°ХэіЈMTS СщұҫјҜөДКұРт·ЦІјЎЈЖдЦРЈ¬ҙуІҝ·Ц·Ҫ·ЁҫщҪбәПСӯ»·ЙсҫӯНшВзЈЁRNN,recurrent neural networkЈ©әНұд·ЦЧФұаВлЖчЈЁVAE,variational autoencoderЈ©ҪЁДЈMTS КэҫЭөДКұРтТААөРФәНЛж»ъРФЎЈө«ТСУРДЈРНҙжФЪИзПВОКМвЎЈ
1) ІЙУГRNN өДТюПтБҝКөПЦVAE ТюҝХјдЦРЛж»ъұдБҝјдөДКұРтТААөРФЈ¬И»¶шRNN ДСТФІ¶»сРтБРКэҫЭөДіӨКұТААөРФЈ¬ХвҪөөНБЛС§П°РтБРКэҫЭ·ЦІјөДДЬБҰЎЈ
2) јЖЛгЛж»ъұдБҝөДҪьЛЖәуСй·ЦІјәНПИСй·ЦІјөДНшВзҪб№№ПаН¬Ј¬ХвК№2 ЦЦ·ЦІјKL Йў¶ИЈЁKullback-Leibler divergenceЈ©ҫаАлҪПРЎЈ¬ФцјУБЛДЈРНөДСөБ·ДС¶ИЎЈ»щУЪПЯРФёЯЛ№ЧҙМ¬ҝХјдДЈРНЈЁLGSSM,linear Gaussian state space modelЈ©јЖЛгЛж»ъұдБҝөДПИСй·ЦІјОЮ·ЁКөПЦЛж»ъұдБҝјдөД·ЗПЯРФЧӘ»»ЎЈ
3) »щУЪRNN өДЙъіЙНшВзҪцТААөУЪЛж»ъұдБҝөДІЙСщЦөЈ¬Г»УРАыУГRNN НЖ¶ПНшВзөДИ·¶ЁРФТюПтБҝЎЈ
Хл¶ФТФЙПОКМвЈ¬ұҫОДМбіцТ»ЦЦГжПт№ӨТөБмУтMTS ТміЈјмІвөДЛж»ъTransformerЈЁST-MTS-AD,stochastic Transformer for MTS anomaly detectionЈ©ДЈРНЎЈёГДЈРНУЙTransformer ұаВлЖчКдіцөДұнКҫёчКұҝМMTS іӨКұТААөМШХчәНЙПТ»КұҝМЛж»ъұдБҝөДІЙСщЦөЙъіЙөұЗ°КұҝМЛж»ъұдБҝөДҪьЛЖәуСй·ЦІјЈ¬К№ST-MTS-AD ҝЙҪиУГTransformer ұаВлЖчКдіцөДіӨКұТААөМШХчФЪТюҝХјдЦРҙ«ІҘЛж»ъұдБҝјдөДіӨКұТААөРФЈ¬ІЙУГГЕҝШЧӘ»»әҜКэЈЁGTF,gated transition functionЈ©ЙъіЙЛж»ъұдБҝөДПИСй·ЦІјІўКөПЦЛж»ъұдБҝјдөД·ЗПЯРФЧӘ»»Ј¬НЁ№эҪ«Transformer ұаВлЖчКдіцөДіӨКұТААөМШХчәНЛж»ъұдБҝІЙСщЦөКдИл¶аІгёРЦӘЖчЈЁMLP,multilayer perceptronЈ©ЦШ№№MTS ёчКұҝМИЎЦө·ЦІјЎЈФЪ4 ёц№ӨТөБмУт№«ҝӘMTS КэҫЭјҜЙПөДКөСйұнГчST-MTS-AD ҫЯУРҪПәГөДТміЈјмІвР§№ыЎЈ
1 Па№ШСРҫҝПЦЧҙ
¶аО¬КұјдРтБРТміЈјмІвКЗКұјдРтБР·ЦОцБмУтЦРөДЦШТӘИООсЦ®Т»Ј¬ЦјФЪС°ХТІ»·ыәП№жФтөД»тіцПЦЖ«ІоөДРтБРЖ¬¶О[11]ЎЈДҝЗ°Ј¬»щУЪЙо¶ИС§П°өДMTSЛІКұј¶ТміЈјмІв·Ҫ·ЁИзПВЎЈ
1) »щУЪФӨІвәНЦШ№№өДИ·¶ЁРФ·Ҫ·ЁЎЈHundmanөИ[12]ЙијЖБЛ»щУЪіӨ¶МКұјЗТдЈЁLSTM,long short-term memoryЈ©НшВзөДәҪМмЖчТЈІвРЕәЕТміЈјмІв·Ҫ·ЁЈ¬НЁ№эФӨІвОуІоИ·¶ЁТміЈЈ¬Жд»№МбіцБЛТ»ЦЦ·ЗІОКэ¶ҜМ¬ТміЈјмІвгРЦөИ·¶Ё·Ҫ·ЁЈ¬ДЬФЪОуұЁВКәНВ©ұЁВКЦ®јдҙпөҪЖҪәвЎЈZhang өИ[13]МбіцБЛГжПт¶аҙ«ёРЖчMTS ТміЈјмІвөДЙо¶Иҫн»эЧФұаВлјЗТдНшВзЈ¬Ҫ«MTS өДКұҝХЗ¶ИлұнКҫәНЦШ№№ОуІоКдИлПЯРФЧФ»Ш№йДЈРНәН»щУЪЧўТвБҰ»ъЦЖөДЛ«ПтLSTM НшВзЈ¬УЙЦШ№№ЛрК§әНФӨІвЛрК§И·¶ЁMTS ТміЈЎЈMalhotra өИ[14]МбіцБЛТ»ЦЦ»щУЪLSTM өДЧФұаВлЖчДЈРНЈ¬ЦјФЪЦШҪЁХэіЈКұјдРтБРЈ¬К№УГЦШ№№ОуІоҪшРРТміЈјмІвЎЈZhangөИ[15]МбіцБЛТ»ЦЦ¶аіЯ¶Иҫн»эСӯ»·ЧФұаВлЖчЈЁMSCREDЈ©Ј¬КЧПИ№№ҪЁДЬұнХчMTS І»Н¬ұдБҝјдПа№ШРФөД¶аіЯ¶ИЗ©ГыҫШХуЈ»И»әуІЙУГҫн»эұаВлЖч¶ФЗ©ГыҫШХуҪшРРұаВлЈ¬К№УГ»щУЪЧўТвБҰөДҫн»эLSTM І¶»сMTS КұРтТААөРФЈ»Чоәу»щУЪҫн»эҪвВлЖчЦШҪЁЗ©ГыҫШХуЈ¬ІўАыУГЗ©ГыҫШХуөДЦШ№№ОуІоХп¶ПТміЈЎЈAudibert өИ[16]ЙијЖБЛ°ьә¬Т»ёцұаВлЖчәН2 ёцҪвВлЖчөДЧФұаВлЖчНшВзҪб№№Ј¬ІЙУГ¶Фҝ№С§П°ІЯВФСөБ·НшВзЈ¬ұЬГвЧФұаВлЖчОЮ·ЁНЁ№эЦШ№№ОуІоЗш·ЦХэіЈСщұҫУлТміЈСщұҫөДПЦПуЈ¬ёГ·Ҫ·ЁГ»УРК№УГСӯ»·ЙсҫӯНшВзҙУ¶ш»сөГБЛҪПҝмөДСөБ·Р§ВКЈ¬ө«ОЮ·ЁҪЁДЈMTS өДКұРтТААө№ШПөЎЈЙПКц·Ҫ·ЁТФФӨІв»тЦШ№№ОӘСөБ·ДҝұкҝМ»ӯХэіЈMTS СщұҫөДМШХчЈ¬УЙЦШ№№ОуІоәНФӨІвОуІојмІвMTS ТміЈЈ¬ОЮ·ЁҪЁДЈMTS өДЛж»ъРФЎЈ
2) »щУЪЦШ№№өДЛж»ъРФ·Ҫ·ЁЎЈZong өИ[6]МбіцТ»ЦЦУГУЪОЮја¶ҪТміЈјмІвөДЙо¶ИЧФұаВлёЯЛ№»мәПДЈРНЈЁDAGMM,deep autoencoding Gaussian mixture modelЈ©Ј¬НЁ№эЧФұаВлЖч»сөГСөБ·СщұҫөДөНО¬ұнКҫЈ¬Ҫ«өНО¬ұнКҫәНСщұҫЦШ№№ОуІоЖҙҪУРОіЙөДПтБҝКдИлУГАҙСөБ·GMM ІОКэөД№АјЖНшВзЈ¬УЙGMM ДЈРНјЖЛгөДСщұҫДЬБҝЦөИ·¶ЁСщұҫКЗ·сТміЈЎЈDeng өИ[7]ІЙУГНјҫн»эНшВзІ¶»сMTS ұдБҝјдҪ»»ҘМШХчЈ¬УЙЧФЧўТвБҰ»ъЦЖМбИЎMTS іӨКұТААөМШХчЈ¬»щУЪVAE өДЦШ№№ДЬБҰҪшРРMTS ТміЈјмІвЎЈPark өИ[8]МбіцБЛ»щУЪLSTM әНVAE өД¶аДЈМ¬MTS ТміЈјмІв·Ҫ·ЁЈ¬ТФLSTM НшВзҪб№№ЧчОӘVAE ЦРөДЙъіЙНшВзәННЖ¶ПНшВзұнКҫMTS өДЛж»ъРФәНКұРтТААөРФЎЈОДПЧ[7-8]НЁ№эЧФЧўТвБҰ»ъЦЖ»тRNN І¶»сMTS өДКұРтТААөРФЈ¬ІўЗТГҝёцКұјдөгНЁ№эЦШІОКэ»ҜІЙСщөГөҪөДЛж»ъұдБҝҫЯУРЛж»ъРФЈ¬ө«Лж»ъұдБҝЦ®јдГ»УРКұРтТААөРФЎЈ
ОӘҙЛЈ¬СРҫҝХЯМбіцБЛ»щУЪVAE өДРтБРКэҫЭЙъіЙДЈРН[17-19]Ј¬ХвР©·Ҫ·ЁҫщІЙУГұд·ЦНЖ¶ПјјКхС§П°КұРтКэҫЭ·ЦІјЈ¬ІўЗТҝЙТФұнКҫЛж»ъұдБҝјдөДКұРтТААөРФЎЈChung өИ[18]МбіцТ»ЦЦұд·ЦСӯ»·ЙсҫӯНшВзЈЁVRNN,variational recurrent neural networkЈ©ДЈРНЎЈVRNNөДНЖ¶ПНшВзУЙКұРтКэҫЭөұЗ°КұҝМКдИлЦөәНЙПТ»КұҝМRNN ТюПтБҝЙъіЙөұЗ°КұҝМЛж»ъұдБҝөДҪьЛЖәуСй·ЦІјЎЈVRNN НЁ№эRNN ТюПтБҝөДөьҙъёьРВКөПЦЛж»ъұдБҝјдөДКұРтТААөРФЎЈVRNN өДЙъіЙНшВзУЙөұЗ°КұҝМЛж»ъұдБҝІЙСщЦөәНЙПТ»КұҝМRNN ТюПтБҝЙъіЙКұРтКэҫЭИЎЦө·ЦІјЎЈDai өИ[9]МбіцБЛГжПтДЪИЭ·Ц·ўНшВзПөНі¶аФӘ№ШјьРФДЬЦёұкКұРтКэҫЭөДТміЈјмІв·Ҫ·ЁSDFVAEЈЁstatic and dynamic factorized VAEЈ©Ј¬Ҫ«VRNN ЦРөДЛж»ъұдБҝ·ЦҪвОӘ¶ҜМ¬әНҫІМ¬Лж»ъұдБҝЈ¬ЖдЦРЈ¬ҫІМ¬Лж»ъұдБҝҝМ»ӯДЪИЭ·Ц·ўНшВзПөНіРФДЬЦёұкИЎЦөөДКұРтІ»ұдРФЎЈSDFVAE УЙЛ«ПтLSTMНшВзС§П°ҫІМ¬Лж»ъұдБҝөДҪьЛЖәуСй·ЦІјЈ¬¶ҜМ¬Лж»ъұдБҝөДҪьЛЖәуСй·ЦІјЙъіЙ·ҪКҪУлVRNN ПаН¬ЎЈLiөИ[10]МбіцБЛ»щУЪVRNN өДMTS ТміЈјмІв·Ҫ·ЁЈ¬ФЪЛрК§әҜКэЦРТэИлК№ПаБЪКұҝМөгКұРтИЎЦөЙъіЙ·ЦІјПаҪьөДХэФт»ҜПоЈ¬К№ДЈРНҫЯУРёьәГөДҝ№ФлДЬБҰЎЈFraccaro өИ[19]МбіцБЛТ»ЦЦИЪәПЧҙМ¬ҝХјдДЈРНЈЁSSM,state space modelЈ©әНRNN өДЛж»ъСӯ»·ЙсҫӯНшВзЈЁSRNN,stochastic recurrent neural networkЈ©ЎЈSRNNДЈРННЁ№эТААөУЪRNN ТюПтБҝәНSSM Лж»ъұдБҝІЙСщЦөөДЙсҫӯНшВзКөПЦSSM Лж»ъЧҙМ¬Ц®јдөД·ЗПЯРФЧӘ»»Ј¬К№SSM ҝЙТФАыУГRNN ұнКҫКұРтТААө№ШПөөДТюПтБҝФЪТюҝХјдЦРҙ«ІҘЛж»ъРФЎЈSRNN УлVRNN өДЗшұрФЪУЪRNN ТюПтБҝөДёьРВІ»ТААөУЪёчКұҝМөДЛж»ъұдБҝЈ¬ДЬЦұҪУҪЁДЈГҝёцКұҝМЛж»ъұдБҝјдөДКұРтТААөРФЈ¬КөПЦБЛRNN И·¶ЁРФТюұдБҝәНSSM Лж»ъұдБҝөД·ЦАлЎЈОДПЧ[19]ұнГчSRNN ДЬ№»ұИVRNN ёьәГөШС§П°КұРтКэҫЭөД·ЦІјЎЈSu өИ[2]Мбіц»щУЪSRNN өДMTSТміЈјмІвДЈРНЈ¬ёГДЈРНөДНЖ¶ПНшВзҪб№№УлSRNN ПаН¬Ј¬ФЪҙЛ»щҙЎЙПІЙУГЖҪГж№йТ»»ҜБчјјКхС§П°ёчКұҝМ·ЗёЯЛ№·ЦІјөДҪьЛЖәуСй·ЦІјЎЈФЪЙъіЙНшВзЦРЈ¬ёГДЈРНУЙТААөУЪЛж»ъұдБҝІЙСщЦөөДRNN ЙъіЙКұРтКэҫЭИЎЦө·ЦІјЈ¬ІЙУГLGSSM јЖЛгЛж»ъұдБҝөДПИСй·ЦІјІўКөПЦЛж»ъұдБҝјдөДКұРтТААөРФЎЈ
2 ST-MTS-AD ДЈРНЙијЖ
2.1 Па№Ш·ыәЕ¶ЁТеј°ST-MTS-AD НшВзҪб№№
MTS КэҫЭјҜјЗОӘk=[k1,k2,Ўӯ,kN] ЎКRMЎБNЈ¬NОӘkөДіЦРшКұјдіӨ¶ИЈ¬Гҝёц№ЫІвЦөkҰУЎКRMКЗФЪКұјдөгҰУ(ҰУЎЬN)өДMО¬ПтБҝЎЈК№УГҙ°ҝЪҙуРЎОӘwЎў»¬¶ҜІҪ·щОӘlөД»¬¶Ҝҙ°ҝЪ¶ФkҪшРРФӨҙҰАнЈ¬Гҝёц»¬¶Ҝҙ°ҝЪОӘ
ұҫОДЙијЖөДST-MTS-AD ДЈРН»щУЪVAE өДұд·ЦНЖ¶ПјјКхС§П°MTS КұРт·ЦІјЈ¬ЖдЦчТӘУЕКЖФЪУЪК№УГTransformer ұаВлЖчЦРөД¶аН·ЧФЧўТвБҰ»ъЦЖЙъіЙMTSёчёцКұҝМөгөДЛж»ъ·ЦІјЈ¬КөПЦБЛVAE ТюҝХјдЦРЛж»ъұдБҝјдөДіӨКұТААө№ШБӘЎЈ¶шЗТST-MTS-AD өДЙъіЙНшВзОӘMLPЈ¬ҪөөНБЛДЈРНөДёҙФУРФЎЈST-MTS-AD ДЈРНҪб№№ИзНј1 ЛщКҫЎЈФЪНЖ¶ПНшВзЦРЈ¬Transformer ұаВлЖчҪ«№ЫІвРтБРx1:TЎКRPЎБTУіЙдОӘМШХчe1:T=[e1,Ўӯ,et,Ўӯ,eT] ЎКRdЎБTЈ¬dОӘTransformer ұаВлЖчКдіцО¬¶ИЈ¬e1:TІ¶»сx1:TЦР№ЫІвұдБҝxtјдөДіӨКұТААөРФЈ¬et(1 ЎЬtЎЬT)ұнКҫe1:TФЪtКұҝМөДИЎЦөПтБҝЎЈҪ«t-1 КұҝМЛж»ъұдБҝzt-1өДІЙСщЦөәНetҙ®ҪУәуКдИлMLP ЙъіЙtКұҝМЛж»ъұдБҝztөДҪьЛЖәуСй·ЦІјЈ¬КөПЦЛж»ъұдБҝzt-1әНztөД·ЗПЯРФЧӘ»»әНКұРтТААө№ШБӘЎЈјЗTёцЛж»ъұдБҝz1,Ўӯ,zTОӘz1:TЎЈФЪЙъіЙНшВзЦРЈ¬tКұҝМЛж»ъұдБҝztІЙСщЦөәНИЎЦөПтБҝetКдИлMLP ЙъіЙөДИЎЦө·ЦІјЎЈTёцКұҝМ№ЫІвұдБҝxtөДЦШ№№Цө,Ўӯ,ұнКҫОӘЎЈt-1 КұҝМЛж»ъұдБҝzt-1өДІЙСщЦөКдИлGTFЙъіЙtКұҝМЛж»ъұдБҝztөДПИСй·ЦІјЈ¬z0ОӘЛж»ъіхКј»ҜөДПтБҝЎЈST-MTS-AD НЁ№эЧоҙу»ҜЦӨҫЭПВҪзУЕ»ҜНЖ¶ПНшВзәНЙъіЙНшВзІОКэЈ¬УЙёчКұҝМxЎдtөДЦШ№№ёЕВКЛЖИ»И·¶Ёx1:TТміЈЖ¬¶ОЎЈ
2.2 ST-MTS-AD НЖ¶ПНшВзЙијЖ
Transformer НшВзЦРөДЧФЧўТвБҰ»ъЦЖИЭТЧІ¶»сРтБРКэҫЭЦРіӨКұТААөМШХчЈ¬ОДПЧ[20]»щУЪTransformer ұаВлЖчЙијЖБЛMTS өДёЯЦКБҝұнКҫС§П°ДЈРНЎЈST-MTS-AD ДЈРНҪ«Transformer ұаВлЖчЧчОӘVAE өДНЖ¶ПНшВзЈ¬І¶»с№ЫІвРтБРx1:TЦРёч№ЫІвұдБҝxtјдөДіӨКұТААөРФЎЈОӘБЛКөПЦЛж»ъұдБҝzt-1әНztөД·ЗПЯРФЧӘ»»әНКұРтТААө№ШБӘЈ¬Ҫ«t-1 КұҝМЛж»ъұдБҝzt-1өДІЙСщЦөәНTransformer ұаВлЖчФЪtКұҝМөДКдіцetҙ®ҪУәуЙъіЙtКұҝМЛж»ъұдБҝztЎЈНЖ¶ПНшВзөДДҝұкКЗС§П°Лж»ъұдБҝz1:TөДХжКөәуСй·ЦІјЈ¬ST-MTS-ADНЁ№эНЖ¶ПНшВзөГөҪz1:TөДҪьЛЖәуСй·ЦІјЈ¬ИзКҪ(1)ЛщКҫЎЈ
ST-MTS-AD ДЈРННЖ¶ПНшВзҪб№№ИзНј2 ЛщКҫЈ¬јҙКҪ(1)ЦРtКұҝМҪьЛЖәуСй·ЦІјНшВзҪб№№ЎЈ
Нј2 ST-MTS-AD ДЈРННЖ¶ПНшВзҪб№№
e1:TјЖЛг№эіМИзПВЎЈ°ҙКҪ(2)¶Фx1:TҪшРРО»ЦГұаВлЈ¬ұаВлҪб№ыјЗОӘЎЈ
ЖдЦРЈ¬WxЎКRdЎБPОӘНшВзІОКэЈ»bЎКR1ЎБTОӘЖ«ЦГПоЈ»wpЎКRdЎБTОӘО»ЦГұаВлҫШХуЈ¬УЙХэПТәҜКэФЪЕјКэО»ЦГјЖЛгөГөҪөДО»ЦГРЕПўәНУаПТәҜКэФЪЖжКэО»ЦГјЖЛг»сөГөДО»ЦГРЕПўҪбәПРОіЙЈ¬ҫЯМеРОКҪИзПВ
УЙКҪ(4)Ў«КҪ(10)ЛщКҫөД¶аН·ЧўТвБҰ»ъЦЖјЖЛгx1:TЦР№ЫІвұдБҝјдіӨКұТААөМШХчe1:TЎЈ
2.3 ST-MTS-AD ЙъіЙНшВзЙијЖ
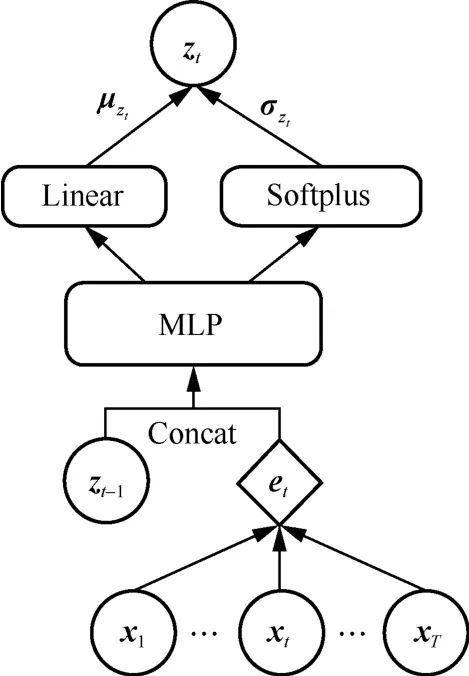
ST-MTS-AD ЙъіЙНшВзУЙMLP №№іЙЈ¬ДҝөДКЗЦШ№№№ЫІвРтБРЎЈЖдУлОДПЧ[2,9]І»Н¬Ц®ҙҰФЪУЪЈ¬УЙЛж»ъұдБҝztІЙСщЦөәННЖ¶ПНшВзЦРTransformer ұаВлЖчФЪtКұҝМөДКдіцetЙъіЙtКұҝМөД№ЫІвұдБҝЈ¬¶шІ»ҪцТААөЛж»ъұдБҝztЎЈХвКЗУЙУЪet°ьә¬БЛАҙЧФКдИл№ЫІвРтБРx1:TөДИ«ҫЦКұРтМШХчЈ¬ДЬ№»ёьәГөШЦШ№№№ЫІвРтБРЎЈН¬КұЈ¬MLP НшВзҪб№№јтөҘЈ¬ҪөөНБЛST-MTS-AD НшВзөДёҙФУРФЎЈST-MTS-AD ЙъіЙНшВзөДБӘәПёЕВК·ЦІјОӘ
Нј3 ST-MTS-AD ДЈРНЙъіЙНшВзҪб№№
ЖдЦРЈ¬ҰОЎ«N(0,I)Ј¬ЎСұнКҫПтБҝФӘЛШіЛ»эЈ¬әН·ЦұрұнКҫУЙНј2 НЖ¶ПНшВзЙъіЙөДztҪьЛЖәуСй·ЦІјҫщЦөәНұкЧј·ҪІоЎЈ
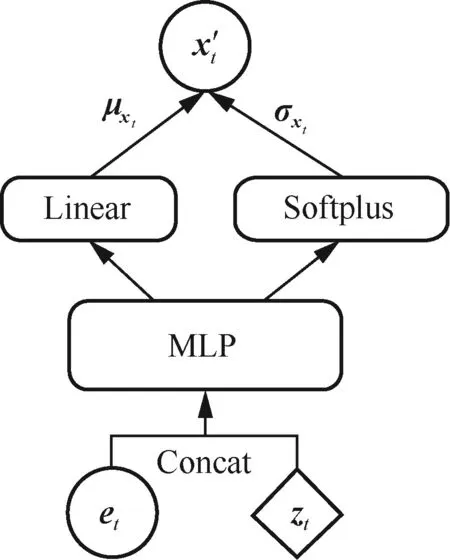
Нј4 GTF НшВзҪб№№
КҪ(16)ұнКҫҫЯУРReLU әНSigmoid јӨ»оәҜКэөДMLPЈ¬КҪ(17)ұнКҫҫЯУРReLU јӨ»оәҜКэөДMLPЈ¬КҪ(18)ұнКҫLinear ІгЈ¬КҪ(20)ұнКҫҫЯУРReLU әНSoftplus јӨ»оәҜКэөДMLPЎЈ
2.4 УЕ»ҜДҝұк
ST-MTS-AD ДЈРНөДУЕ»ҜДҝұкОӘЧоҙу»ҜКҪ(21)ЛщКҫөДЦӨҫЭПВҪзЈЁELBO,evidence lower boundЈ©ЎЈ
Лг·Ё1ST-MTS-AD ДЈРНөДСөБ·Лг·Ё


3 КөСй
3.1 КөСйКэҫЭјҜј°»·ҫі
КөСйІЙУГТФПВ4 ёц№«ҝӘөДКэҫЭјҜЈәSMDЈЁserver machine datasetЈ©АҙЧФТ»јТҙуРН»ҘБӘНш№«ЛҫОӘЖЪ5 ЦЬөД·юОсЖчјмІвКэҫЭјҜ[2]Ј»MSLЈЁmars science laboratoryЈ©әНSMAPЈЁsoil moisture active passive satelliteЈ©АҙЧФNASA әҪМмЖчјаІвПөНіұЁёжЦРөДТЈёРКэҫЭ[12]Ј»SWaTЈЁsecure water treatmentЈ©АҙЧФТ»ёцЛ®ҙҰАні§РЕПўОпАнПөНіОӘЖЪ11 МмөДјаҝШКэҫЭјҜ[3]ЎЈёчКэҫЭјҜҫЯМеөДГиКцИзұн1 ЛщКҫЎЈ
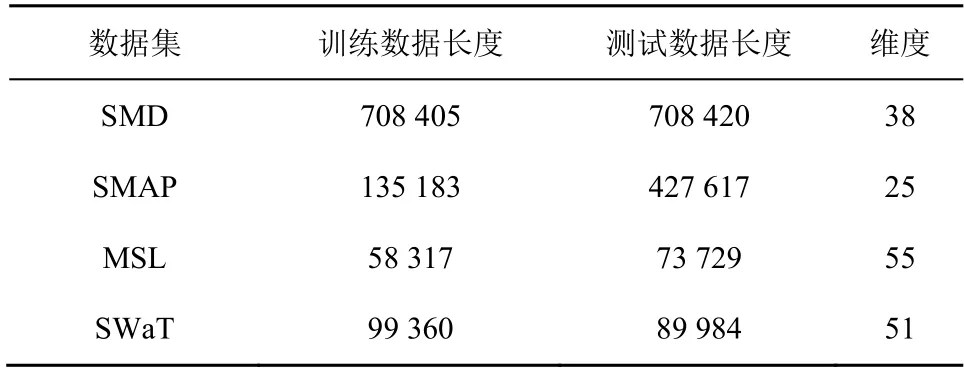
ұн1 ёчКэҫЭјҜҫЯМеөДГиКц
КөСйУІјю»·ҫіИзПВЈәUbuntu16.04 ІЩЧчПөНіЈ¬Inter Xeon Gold 5220R CPUЈ¬NVIDIA Tesla T4 ПФҝЁЎЈИнјю»·ҫіИзПВЈәPython3.6Ј¬Pytorch 1.10.1ЎЈ
3.2 КөСйДЈРНІОКэЙиЦГәНЖАјЫЦёұк
ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSLЎўSWaTКэҫЭјҜЙПөД»¬¶Ҝҙ°ҝЪҙуРЎwЎў»¬¶ҜІҪ·щlЎў№ЫІвРтБРіӨ¶ИTәНЧФЧўТвБҰН·КэH·ЦұрЙиОӘ10Ўў10Ўў200әН8ЎЈёщҫЭКэҫЭјҜөДО¬¶ИҙуРЎЈ¬ДЈРНФЪSMD әНSWaTКэҫЭјҜЙПөДTransformer ұаВлЖчКдіцО¬¶Иd·ЦұрЙиОӘ128 әН256Ј¬ФЪSMAP әНMSL КэҫЭјҜЦРЙиОӘ64ЎЈКөСйК№УГAdam УЕ»ҜЖчЈ¬ЙиЦГС§П°ВКr=0.000 1Ј¬ЕъҙҰАнҙуРЎbatch=64Ј¬СөБ·ЦЬЖЪКэepoch=200ЎЈ
ST-MTS-AD ДҝұкКЗјмІв№ЫІвРтБРx1:TЦР№ЫІвұдБҝxtКЗ·сТміЈЎЈФЪІвКФјҜЦРЈ¬Иф№ЫІвұдБҝxtұнКҫөД»¬¶Ҝҙ°ҝЪЦРДіТ»КұјдөгИЎЦөkҰУЎКRMОӘТміЈөгЈ¬ФтxtұкјЗОӘТміЈЎЈ¶ФУЪІвКФјҜЦРөДГҝёц№ЫІвұдБҝxtЈ¬Из№ыЦШ№№іцөД№ЫІвұдБҝұ»ЕР¶ПОӘТміЈЈ¬ЗТxtХжКөұкЗ©ТІОӘТміЈЈ¬ФтјЗОӘХжСфЈЁTPЈ©ЎЈИз№ыЦШ№№іцөД№ЫІвұдБҝұ»ЕР¶ПОӘТміЈЈ¬ө«xtХжКөұкЗ©ОӘХэіЈЈ¬ФтјЗОӘјЩСфЈЁFPЈ©ЎЈИз№ыЦШ№№іцөД№ЫІвұдБҝұ»ЕР¶ПОӘХэіЈЈ¬ө«xtХжКөұкЗ©ОӘТміЈЈ¬ФтјЗОӘјЩТхЈЁFNЈ©ЎЈИз№ыЦШ№№іцөД№ЫІвұдБҝұ»ЕР¶ПОӘХэіЈЈ¬ЗТxtХжКөұкЗ©ОӘХэіЈЈ¬ФтјЗОӘХжТхЈЁTNЈ©ЎЈұҫОДК№УГ3 ёцЦёұкАҙәвБҝТміЈјмІвДЈРНөДРФДЬЈ¬·ЦұрОӘҫ«И·ВКPrecisionЎўХЩ»ШВКRecallЎўF1 ·ЦКэЈ¬ЖдЦРЈ¬F1 ·ЦКэОӘҫ«И·ВКәНХЩ»ШВКөДөчәНЖҪҫщКэЈ¬F1·ЦКэФҪҙуұнКҫТміЈјмІвДЈРНөДРФДЬФҪәГЎЈ
3.3 КөСйҪб№ыУл·ЦОц
СЎИЎ6 ЦЦУлST-MTS-AD Па№ШөДТміЈјмІвДЈРНҪшРРКөСй¶ФұИЈ¬·ЦұрОӘDAGMM[6]ЎўLSTM-VAE[8]ЎўMSCRED[15]ЎўUSADЈЁunsupervised anomaly detectionЈ©[16]ЎўOmniAnomaly[2]ЎўSDFVAE[9]ЎЈёчДЈРНөДКөСйҫщІЙУГұҫОДөДКэҫЭФӨҙҰАн·ҪКҪЈ¬І»Н¬ДЈРНөДРФДЬ¶ФұИИзұн2 ЛщКҫЎЈ
ҙУұн2 ҝЙЦӘЈ¬ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSL әНSWaT КэҫЭјҜЙПөДF1 ·ЦКэ·ЦұрОӘ0.933 2Ўў0.966 4Ўў0.981 9 әН0.834 2Ј¬ПаҪПУЪ5 ЦЦ¶ФұИДЈРНХыМеЙПУРҪПёЯөДМбЙэЎЈФЪSMDЎўSMAPЎўMSL әНSWaTКэҫЭјҜЙПЈ¬ST-MTS-AD ДЈРНөДF1 ·ЦКэұИMSCRED·ЦұрМбёЯБЛ15.6%Ўў10.0%Ўў4.7%әН3.3%Ј¬ST-MTS-ADДЈРНөДF1 ·ЦКэұИUSAD ДЈРН·ЦұрМбёЯБЛ9.6%Ўў6.9%Ўў15.6%әН3.0%Ј¬УлMSCRED ПаұИЈ¬ST-MTS-AD ФЪSMD КэҫЭјҜЙПөДF1 ·ЦКэМбёЯЧо¶аЈ¬ХвКЗТтОӘSMDКэҫЭјҜЦРҙжФЪіЦРшКұјд¶МЎўТміЈЖ«ІоҪПРЎөДИЎЦөЖ¬¶О[9]Ј¬MSCRED ДЈРНЦРөД№№ФмЗ©ГыҫШХуОЮ·ЁІ¶»сХвР©ПёОўөДТміЈМШХчЎЈUSAD ЛдИ»ІЙУГ¶Фҝ№С§П°ІЯВФұЬГвЧФұаВлЖчОЮ·ЁНЁ№эЦШ№№ОуІоЗш·ЦХэіЈСщұҫУлТміЈСщұҫөДОКМвЈ¬ө«ЖдЧФұаВлЖчНшВзГ»УРІ¶»сMTS өДКұРтТААөМШХчЎЈКөСйҪб№ыТІСйЦӨБЛ»щУЪЦШ№№өДЛж»ъРФДЈРНST-MTS-AD өДТміЈјмІвР§№ыәГУЪ»щУЪЦШ№№өДИ·¶ЁРФДЈРНMSCRED әНUSADЎЈ
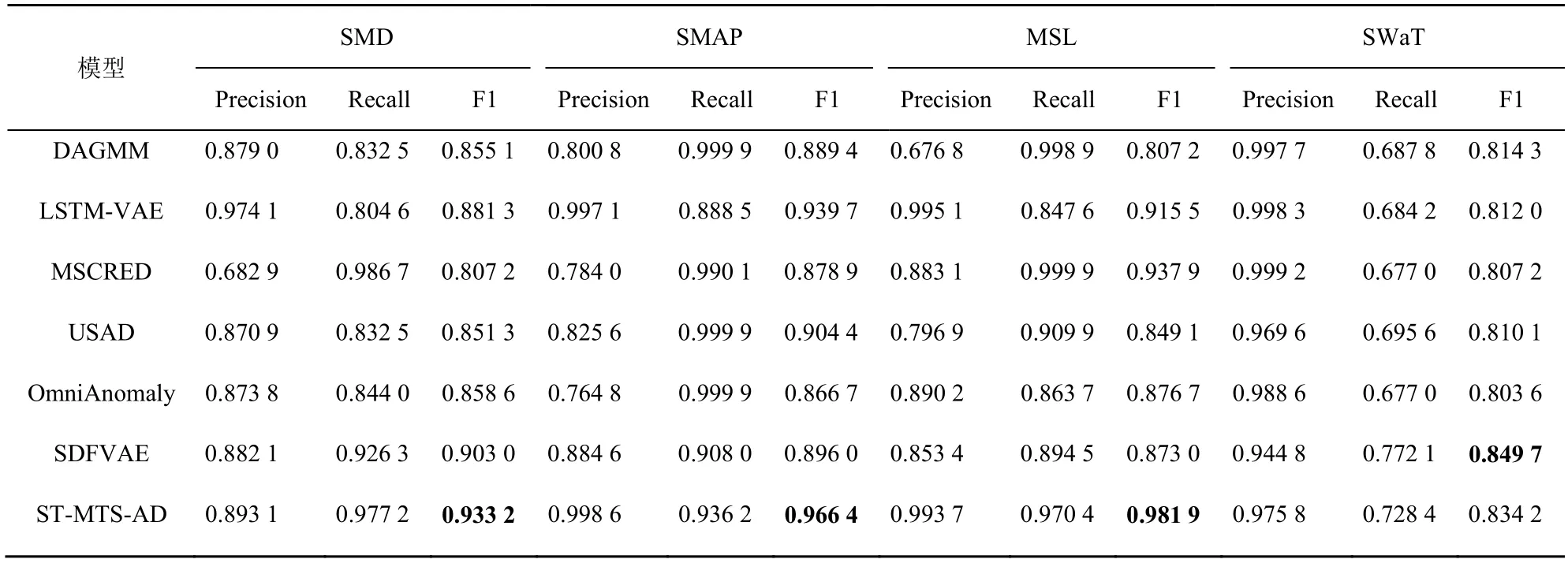
ұн2 ST-MTS-AD ДЈРНУл6 ЦЦДЈРНөДРФДЬ¶ФұИ
DAGMM өДF1 ·ЦКэФЪSMDЎўSMAPЎўMSLәНSWaT КэҫЭјҜЙПұИST-MTS-AD ДЈРН·ЦұрөН8.4%Ўў7.9%Ўў17.7%әН2.3%Ј¬DAGMM ЛдКфУЪ»щУЪЦШ№№өДЛж»ъРФДЈРНЈ¬ө«ЖдЧФұаВлЖчНшВзҪб№№ЙијЖГжПтұнёсКэҫЭЈ¬ОЮ·ЁМбИЎ MTS КұРтМШХчЎЈST-MTS-AD ДЈРНФЪSMDЎўSMAP әНMSL КэҫЭјҜЙПөДF1 ·ЦКэұИSDFVAE ·ЦұрМбёЯБЛ3.3%Ўў7.8%әН12.4%Ј¬ө«ФЪSWaT КэҫЭјҜЙПөДF1 ·ЦКэұИSDFVAE өН 1.8%Ј¬ХвКЗУЙУЪSDFVAE ұИST-MTS-AD ДЈРНУРҪПЗҝөДҝ№ФлДЬБҰЎЈLSTM-VAEәНOmniAnomalyОӘУлST-MTS-ADЧоПа№ШөДДЈРНЈ¬ҫщОӘ»щУЪVAE өДРтБРЙъіЙДЈРНЎЈФЪSMDЎўSMAPЎўMSL әНSWaT КэҫЭјҜЙПЈ¬ST-MTS-AD ДЈРНөДF1·ЦКэұИLSTM-VAE ДЈРНМбёЯБЛ5.9%Ўў2.8%Ўў7.3%әН2.7%Ј¬ұИOmniAnomaly ДЈРНМбёЯБЛ8.6%Ўў11.5%Ўў11.9%әН3.8%ЎЈХвКЗУЙУЪLSTM-VAE ДЈРНОЮ·ЁҪЁДЈТюҝХјдЦРЛж»ъұдБҝЦ®јдөДКұРтТААөРФЎЈOmniAnomaly ДЈРН»щУЪRNN ёчКұҝМөДТюПтБҝКөПЦЛж»ъұдБҝјдКұРтТААөРФЈ¬ХвЦЦ»ъЦЖОЮ·ЁКөПЦЛж»ъұдБҝјдөДіӨКұТААө№ШБӘЈ¬ЖдІЙУГөД»щУЪLGSSM өДЛж»ъұдБҝПИСй·ЦІјЙъіЙ·ҪКҪОЮ·ЁКөПЦЛж»ъұдБҝјдөД·ЗПЯРФЧӘ»»Ј¬ЗТёГДЈРНФЪЙъіЙНшВзЦРҪцТААөёчКұҝМЛж»ъұдБҝөДІЙСщЦөЈ¬Г»УРАыУГНЖ¶ПНшВзRNN өДТюПтБҝРЕПўЎЈ
3.4 ПыИЪКөСй
ОӘБЛСйЦӨST-MTS-AD ДЈРНПа№ШДЈҝйЙијЖөДУРР§РФЈ¬Ҫ«ST-MTS-AD ДЈРНУлЖд3 ёцұдМеҪшРР¶ФұИЈ¬3 ёцұдМе·ЦұрОӘST-MTS-AD-1ЎўST-MTS-AD-2 әНST-MTS-AD-3ЎЈST-MTS-AD-1 ДЈРНұнКҫФЪНј1 өДST-MTS-AD ДЈРН»щҙЎЙПҪ«НЖ¶ПНшВзЦРTransformerұаВлЖчМж»»ОӘГЕҝШСӯ»·өҘФӘЈЁGRU,gate recurrent unitЈ©ЙсҫӯНшВзЎЈST-MTS-AD-2 ДЈРНұнКҫҪ«ST-MTS-AD ДЈРНЦРУГУЪЙъіЙЛж»ъұдБҝПИСй·ЦІјөДGTF Мж»»ОӘLGSSMЎЈST-MTS-AD-3 ДЈРНұнКҫНј1ЙъіЙНшВзИҘіэБЛetЧчОӘКдИлөДЙијЖЈ¬ЙъіЙНшВзөДКдИлҪцАҙЧФЛж»ъұдБҝztөДІЙСщЦөЎЈёчДЈРНФЪ4 ёцКэҫЭјҜЙПөДКөСйҪб№ыИзНј5 ЛщКҫЎЈ
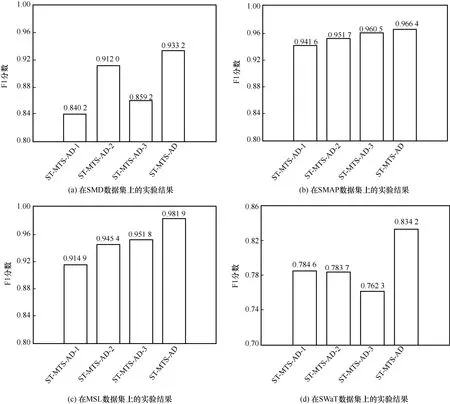
Нј5 І»Н¬КэҫЭјҜЙПөДПыИЪКөСй
ҙУНј5 ҝЙЦӘЈ¬ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSL әНSWaT КэҫЭјҜЙПөДF1 ·ЦКэұИST-MTS-AD-1ДЈРН·ЦұрМбёЯБЛ11.1%Ўў2.6%Ўў7.3%әН6.3%Ј¬ТтҙЛ»щУЪTransformer ұаВлЖчЙъіЙөДКұРтТААөМШХчДЬёьәГөШКөПЦТюҝХјдЦРЛж»ъұдБҝјдөДКұРтТААөРФЎЈST-MTS-AD ДЈРНөДF1 ·ЦКэұИST-MTS-AD-2 ДЈРН·ЦұрМбёЯБЛ2.3%Ўў1.5%Ўў3.9%әН6.4%Ј¬ФӯТтКЗGTFІЙУГGRU өДЛјПл¶ФЛж»ъұдБҝzt-1өҪztөДЧӘ»»әҜКэҪшРРІОКэ»ҜЈ¬НЁ№э·ЗПЯРФЧӘ»»әҜКэҝШЦЖzt-1өҪztөДРЕПўҙ«өЭЈ¬ҝЙТФІ¶»сЛж»ъұдБҝЦ®јдёьёҙФУөДТААөРФЈ¬¶шLGSSM АыУГҝЁ¶ыВьВЛІЁөДЛјПлКөПЦЛж»ъұдБҝјдөДПЯРФЧӘ»»Ј¬Ҫб№ыЦӨГчБЛST-MTS-AD К№УГGTFөДБ¬ҪУ·ҪКҪұИК№УГLGSSM өДБ¬ҪУ·ҪКҪёьјУУРР§ЎЈST-MTS-AD ДЈРНөДF1 ·ЦКэФЪSMDЎўSMAPЎўMSLәНSWaT КэҫЭјҜ·ЦұрұИST-MTS-AD-3 ДЈРНМбёЯБЛ8.6%Ўў0.6%Ўў3.2%әН9.4%Ј¬УЙTransformer ұаВлЖчЙъіЙіӨКұТААөМШХчetәННЖ¶ПНшВзЙъіЙөДЛж»ъұдБҝztөДІЙСщЦөДЬёьәГөШЦШ№№MTS ёчКұҝМxЎдtөД·ЦІјЎЈБнНвЈ¬УлST-MTS-AD-1ЎўST-MTS-AD-2 әНST-MTS-AD-3ПаұИЈ¬ST-MTS-AD ФЪSMAP КэҫЭјҜЙПөДөДF1 ·ЦКэМбёЯІўІ»ГчПФЎЈХвКЗТтОӘSMAP КэҫЭјҜЦРҙжФЪәЬ¶аАлЙўұдБҝЈ¬ЖдТміЈЖ¬¶ОұИҪПИЭТЧұ»јмІвЎЈ
4 ҪбКшУп
ұҫОДМбіцБЛТ»ЦЦИЪәПTransformer ұаВлЖчәНVAE өДЛж»ъTransformer MTS ТміЈјмІвДЈРНЎЈёГДЈРН»щУЪTransformer ұаВлЖчЙъіЙөДКұРтМШХчКөПЦТюҝХјдЦРЛж»ъұдБҝјдөДіӨКұТААөРФЈ¬ІЙУГГЕҝШЧӘ»»әҜКэЙъіЙКұРтЛж»ъұдБҝөДПИСй·ЦІјЈ¬УЙНЖ¶ПНшВзЙъіЙөДёчКұҝМЛж»ъұдБҝҪьЛЖәуСй·ЦІјІЙСщЦөәНTransformer ұаВлЖчКдіцөДКұРтМШХчЦШ№№MTS ёчКұҝМИЎЦөөД·ЦІјЎЈФЪ4 ёц№«ҝӘКэҫЭјҜЙПКөСйҪб№ыұнГчБЛST-MTS-AD ЙијЖөДУРР§РФЎЈПВТ»ІҪұКХЯҪ«СРҫҝИзәО»щУЪTransformer ұаВлЖчКөПЦТюҝХјдЦРЛж»ъұдБҝјдөД·ЗВн¶ыҝЙ·т¶ҜМ¬РФЎЈ