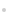ЈЁ1.ДПҫ©УКөзҙуС§НЁРЕУлРЕПў№ӨіМС§ФәЈ¬ҪӯЛХ ДПҫ© 210003Ј»2.ДПҫ©УКөзҙуС§НЁРЕУлНшВзјјКх№ъјТ№ӨіМСРҫҝЦРРДЈ¬ҪӯЛХ ДПҫ© 210003Ј©
0 ТэСФ
ЛжЧЕҝЖјјөД·ўХ№Ј¬ёчЦЦОЮПЯНЁРЕПөНіПајМіцПЦЈ¬ХвК№ТФНЁРЕОӘ»щҙЎөДөјәҪЎў¶ЁО»өИјјКхСёЛЩ·ўХ№ЎЈИ«Зт¶ЁО»ПөНіЈЁGPS,global positioning systemЈ©КЗТ»ёцУЙ24 ҝЕОАРЗЧйіЙІўёІёЗИ«ЗтөДОАРЗПөНі[1]Ј¬ФЪКТНвҝХҝхөШҙш¶ЁО»Р§№ыәЬәГЎЈө«КЗGPS РЕәЕөДҪУКХ№ҰВКәЬРЎЈ¬ІўЗТФЪУРХП°ӯОпХЪөІКұ»біцПЦәЬҙуөДОуІоЈ¬ТтҙЛІўІ»ККУГУЪКТДЪ¶ЁО»ЎЈХл¶ФХвТ»ОКМвЈ¬ёчЦЦКТДЪ¶ЁО»·Ҫ°ёТІПајМіцПЦЈ¬іЈјыөД·Ҫ°ёУРА¶СА¶ЁО»ЎўОЮПЯҫЦУтНш¶ЁО»ЎўәмНвПЯ¶ЁО»Ўўі¬ҝнҙшЈЁUWB,ultra wide bandЈ©¶ЁО»өИЎЈ
А¶СА¶ЁО»јјКх[2]КЗұИҪПЦчБчөД¶ЁО»јјКхЈ¬ФЪЧЫәПіЙұҫЎўҝ№ёЙИЕДЬБҰәНІјҫЦёҙФУ¶ИЙПУРТ»¶ЁУЕКЖЎЈө«КЗЈ¬Жд¶ЁО»ОуІоТ»°гФЪ1Ў«3 mЈ¬І»ККәП¶Ф¶ЁО»ҫ«¶ИТӘЗуҪПёЯөДКТДЪіЎҫ°ЎЈОЮПЯҫЦУтНш¶ЁО»јјКх[3]НЁ№эІЙјҜНшВзҪЪөгО»ЦГРЕПўЈ¬НкіЙ¶ФДҝұкО»ЦГөД¶ЁО»ЎЈДҝЗ°Ј¬КТДЪОЮПЯҫЦУтНшІјЦГ№г·әЎўУҰУГіЎҫ°ҪП¶аЈ¬ХвКЗЖдУЕКЖЛщФЪЎЈө«КЗОЮПЯҫЦУтНшРЕәЕИЭТЧКЬөҪёЙИЕІўЗТДЬәДҪПҙуЈ¬ТтҙЛ¶ЁО»ҫ«¶ИҪПөНЎў¶ЁО»ОИ¶ЁРФҪПІоЎЈәмНвПЯ¶ЁО»јјКх[4]АыУГ№вС§ҙ«ёРЖчҪУКХ¶ЁО»Дҝұк·ўЙдөДәмНвПЯҪшРРІвҫаЈ¬ІўКөПЦ¶ФДҝұк¶ЁО»ЎЈө«КЗәмНвПЯЦ»ДЬСШЦұПЯҙ«ІҘЈ¬І»ДЬҙ©НёХЪұООпЈ¬ЖдФЪКТДЪёҙФУ»·ҫіПВөД¶ЁО»Р§№ыІ»јСЎЈUWB ¶ЁО»јјКх[5]КЗТ»ЦЦОЮПЯФШІЁНЁРЕјјКхЈ¬ЖөВКҙшҝнФЪ1 GHz ТФЙПЈ¬·¶О§ФЪ3.1Ў«10.6 GHzЎЈUWB РЕәЕ·ўЙдІ»РиТӘК№УГҙ«НіНЁРЕМеЦЖЦРөДФШІЁЈ¬¶шКЗНЁ№э·ўЛНДЙГлј¶ј°ТФПВөДј«ХӯВціеАҙҙ«КдКэҫЭ[6]ЎЈUWB ¶ЁО»КЗНЁ№эјЖЛгВціеөҪҙпКұјдНкіЙ¶ФҫаАлөДІвБҝЈ¬ҙУ¶шКөПЦДҝұкөД¶ЁО»ЎЈУлЖдЛыКТДЪ¶ЁО»јјКхПаұИЈ¬UWB РЕәЕҫЯУРәЬёЯөДЖөВКәНКұјд·ЦұжВКЈ¬К№¶аҫ¶РЕәЕФЪКұјдЙПІ»ИЭТЧЦШөюЈ¬·ҪұгҪУКХ»ъ·ЦАл¶аҫ¶РЕәЕ·ЦБҝІўід·ЦАыУГЈ¬МбЙэ¶ЁО»ҫ«¶ИЎЈТтҙЛЈ¬UWB ¶ЁО»ҫ«¶ИҝЙҙпөҪ·ЦГЧј¶Ј¬ЗТҝ№ёЙИЕДЬБҰј°ҝ№¶аҫ¶ЛҘВдДЬБҰЗҝ[7]ЎЈұҫОДФЪёҙФУКТДЪ»·ҫіПВЈ¬СЎИЎЖдЧчОӘ¶ЁО»Лг·ЁөДКөПЦ·Ҫ°ёЎЈ
ОДПЧ[8]МбіцБЛҫЯУРұХКҪҪвөД¶юІҪјУИЁЧоРЎ¶юіЛЛг·ЁЈ¬јҙCHAN Лг·ЁЎЈёГЛг·ЁұҫЦКЙПКЗАыУГЧоҙуЛЖИ»№АјЖЗуіцДҝұкҪЪөгөДО»ЦГРЕПўЈ¬ід·ЦАыУГБЛИЯУаРЕПўЎЈН¬КұЈ¬ёГЛг·Ё¶ЁО»ҫ«¶ИҪПёЯЈ¬өұ»щХҫКэҙуУЪ3 КұҪУҪь¶ЁО»№АјЖөДҝЛАӯГАВЮПВҪзЈЁCRLB,Cramer-Rao lower boundЈ©Ј¬ТІКЗК№УГҪП№г·әөД¶ЁО»Лг·ЁЎЈёГЛг·ЁФЪНЖөј№эіМЦРҙжФЪТ»ёцЗ°МбМхјюЈ¬јҙјЩЙиІвБҝҫаАлОуІоҪПРЎЗТОӘАнПлөДБгҫщЦөёЯЛ№Лж»ъұдБҝЎЈЛщТФФЪТ»Р©ёҙФУ¶ЁО»»·ҫіЦРЈ¬ёГЛг·Ё¶ЁО»ҫ«¶ИҪПөНЎЈ
ОӘБЛҪөөНКТДЪ¶ЁО»ЦР·ЗКУҫаЈЁNLOS,non-line-of-sightЈ©ОуІоҙшАҙөДУ°ПмЈ¬ҝЙТФАыУГРЕәЕ·ҙЙдөДјёәОРФЦКНЖЛгіцРЕәЕөД·ҙЙдВ·ҫ¶ЎЈёГАаЛг·ЁКЧПИНЁ№э·ўЙдҪЗәНИлЙдҪЗҪ«NLOS РЕәЕөД·ҙЙдөг№АЛгіцАҙЈ¬И»әуНЖЛгіцРЕәЕҙ«КдөДКөјКВ·ҫ¶Ј¬ЧоәујЖЛгіцДҝұкУл»щХҫјдөДЦұЙдВ·ҫ¶іӨ¶ИЎЈНЁ№эМбёЯ·ўЙдҪЗЎўИлЙдҪЗөДҫ«¶ИәНөҘ·ҙЙдФІДЈРНөДЧјИ·¶ИЈ¬ҝЙТФКөПЦ¶ФДҝұкөДёЯҫ«¶И¶ЁО»[9-10]ЎЈБнНвЈ¬УЙУЪЦұЙдРЕәЕФЪҙ©НёКТДЪіЈјыХП°ӯОпКұІъЙъөДЛрәДКЗІ»Н¬өДЈ¬ұИИзёЦ°еЎўИЛМеәНДҫ°еөИЗйҝцІъЙъөДҙ©НёЛрәДКЗІ»Т»СщөДЎЈТтҙЛФЪИ·¶ЁҫЯМеХП°ӯОпөДАаРНЎўәс¶ИәНКэБҝөИРЕПўөДЗйҝцПВЈ¬¶ФРЕәЕФЪҙ©НёХП°ӯОпКұФміЙөДДЬБҝЛрәДЦрТ»ҪшРРРЈЧјәН¶ФұИ·ЦОцЈ¬ҝЙТФЧјИ·өШјЖЛгіцРЕәЕЦұЙдҫаАл[11-12]ЎЈ
ТФЙП2 АаКТДЪ¶ЁО»Лг·ЁЛдИ»ҝЙТФФЪёҙФУКТДЪ»·ҫіПВҪ«¶ЁО»ҫ«¶ИМбёЯөҪ30 cm ЧуУТЈ¬ө«КЗРиТӘМбЗ°ЦӘөАКТДЪХП°ӯОпөДО»ЦГЎўАаұрЎўКэБҝөИРЕПўЈ¬ТтҙЛФЪКөјКіЎҫ°ЦРҪПДСУҰУГЎЈФЪКөјКУҰУГЦРЈ¬Т»°г¶ФNLOS РЕәЕОуІоұҫЙнҪшРРҙҰАнЈ¬ҙУ¶шУЕ»Ҝ¶ЁО»Ҫб№ыЎЈІРІојмСйЛг·ЁФЪ№ЫІв¶ЁО»Н»ұдКэҫЭКұјЖЛгІРІоІўЙиЦГТ»ёцгРЦөЈ¬ИфІъЙъөДІРІоҙуУЪгРЦөЈ¬ФтКУОӘNLOS РЕәЕЈ¬ІўҪшРР¶ӘЖъЈ»·сФтЈ¬КУОӘКУПЯПЯВ·ЈЁLOS,line of sightЈ©РЕәЕЈ¬ҝЙТФјУТФАыУГІўКөПЦДҝұк¶ЁО»ЎЈө«КЗёГЛг·ЁФЪҙжФЪҙуБҝNLOS РЕәЕКұОЮ·Ё¶ФДҝұкҪшРР¶ЁО»ҙҰАн[13]ЎЈЦРЦөВЛІЁЛг·Ё¶ФNLOS№ЫІвЦөҪшРРФӨҙҰАнЈ¬Ҫ«ДіТ»ҫаАлБҝҪшРР¶аҙО№ЫІвБҝЈ¬јУИЁИҘіэЖдЦРөДЧоҙуЦөәНЧоРЎЦөЈ¬Ҫ«КЈУаөДІвБҝЦөҪшРРҫщЦөВЛІЁЧчОӘёГҙҰҫаАлөД№ЫІвБҝЎЈФЪКөјКіЎҫ°ЦРЈ¬Т»ёцО»ЦГҙҰУЪNLOS өДЗйҝцәЬҝЙДЬТ»ЦұҙжФЪЈ¬¶ФДіТ»ёцөгөД¶аҙО№ЫІвБҝ»бТ»ЦұҙжФЪҪПҙуОуІоЈ¬ХвТІКЗёГЛг·ЁРиТӘУЕ»ҜҪвҫцөДОКМв[14]ЎЈОДПЧ[15]јЩЙиФЪГҝҙОҪшРР№ЫІвКұЈ¬өұЗ°ұкЗ©ЈЁTagЈ©өДО»ЦГАлЗ°Т»КұҝМұкЗ©өДО»ЦГУҰёГұЈіЦөНУЪгРЦөЎЈ»щУЪТФЙПјЩЙиЈ¬ФЪ¶а»щХҫ¶ЁО»ЗйҝцПВҝЙТФ¶Ф¶ЁО»»щХҫҪшРР·ЦЧйЈ¬ИЎИОТв3 ёц»щХҫОӘТ»ЧйЈ¬Ҫ«ГҝЧйјЖЛгҪб№ыУлЙПТ»КұҝМұкЗ©О»ЦГЦ®ІоФЪёш¶ЁгРЦөДЪөДЛщУРҪб№ыҪшРРјУИЁЖҪҫщҙҰАнЈ¬јЖЛгіцөұЗ°КұҝМөДұкЗ©О»ЦГЎЈёГЛг·ЁҝјВЗ¶ЁО»Ҫб№ыөДКұјд№ШБӘРФЈ¬өұҙжФЪЦБЙЩТ»Чй»щХҫУлұкЗ©Ц®јдОӘИ«LOSөДЗйҝцКұЈ¬ёГЛг·ЁРФДЬҝЙҙпөҪ30 cm ЧуУТөД¶ЁО»ҫ«¶ИЎЈө«КЗФЪКөјК»·ҫіЦРЈ¬әЬДСұЈЦӨ»щХҫәНұкЗ©Ц®јдөДРЕәЕҙ«КдЗйҝцЈ¬ЛщТФФЪёҙФУКТДЪМхјюПВЈ¬Жд¶ЁО»РФДЬјұҫзПВҪөЎЈ
ОДПЧ[16]АыУГҝЁ¶ыВьВЛІЁАҙРЮХэCHAN Лг·ЁФЪNLOS ПВІъЙъөДҫаАлОуІоЦөЎЈЖдәЛРДЛјПл°ьАЁ¶ЁО»Ҫб№ыөДФӨІвәНРЈХэ2 ёцҪЧ¶ОЈ¬ЖдЦРЈ¬ФӨІвҪЧ¶ОКЗёщҫЭЗ°Т»КұҝМПөНіЧҙМ¬өД№АјЖЦөЈ¬јЖЛгөұЗ°КұҝМПөНіЧҙМ¬өДФӨІвЦөЈ»РЈХэҪЧ¶ОКЗ»сИЎөұЗ°ҪЧ¶ОөД№ЫІвЦөЈ¬¶ФФӨІвЦөҪшРРРЮХэЈ¬ҙУ¶шёшіцөұЗ°КұҝМПөНіЧҙМ¬өДЧоУЕ№АјЖЎЈН¬КұЈ¬ёГЛг·ЁЛжЧЕ¶ЁО»КұјдөДНЖТЖЈ¬»бІ»¶ПёДЙЖҝЁ¶ыВьВЛІЁФцТжПөКэKАҙҙпөҪҫ«Чј¶ЁО»өДР§№ыЎЈө«КЗФЪіхКј¶ЁО»ҪЧ¶ОЈ¬УЙУЪФцТжПөКэKөчҪЪҪПВэЈ¬»бК№ЖдФЪіхКјКұҝМ¶ЁО»ҫ«¶ИІ»ёЯЈ¬ІўЗТФцТжПөКэKКЗёщҫЭЙПТ»КұҝМЧҙМ¬¶шІ»¶ПёДұдөДЈ¬ТтҙЛөұіЎҫ°ұд»ҜҪПҙуКұЈ¬·ҙ¶ш»бТэИлРВөДОуІоЎЈ
ЧЫЙПЛщКцЈ¬ұҫОДМбіцБЛТ»ЦЦ»щУЪCHAN өДёДҪшҝЁ¶ыВьВЛІЁЛг·ЁЎЈёГЛг·ЁФЪІ»Н¬ЦГРЕЗшУтПВСЎФсІ»Н¬өДФцТжПөКэKЈ¬ұЬГвБЛЙПТ»КұҝМФцТжПөКэөДёәГжУ°ПмЈ¬МбёЯБЛ¶ЁО»ҫ«¶ИЎЈН¬КұЈ¬ФЪЕР¶ПЦГРЕЗшУт·ҪГжЈ¬CHAN Лг·Ё¶ФNLOS іЎҫ°ПВ¶ЁО»ОуІоұИҪПГфёРЈ¬ТтҙЛСЎФсЖд¶ЁО»Ҫб№ыІРІоЧчОӘЕР¶ПТАҫЭЈ¬МбёЯБЛЦГРЕЗшУтЕРұрөДЧјИ·іМ¶ИЎЈ
1 UWB ¶ЁО»»·ҫіј°ДЈРН
1.1 UWB КТДЪ¶ЁО»»·ҫіҪйЙЬ
UWB КТДЪ¶ЁО»ПөНі[17]өДҪЪөгёщҫЭЖдФЪОЮПЯНшВзЦРөДЧчУГәНАаРН·ЦОӘ2 АаЈәөЪТ»АаКЗЧчОӘЧшұкПөІОҝјөДТСЦӘҪЪөгЈ¬іЖЧчГӘҪЪөгЈ¬ТІҝЙТФіЖОӘ»щХҫЈЁBS,base stationЈ©Ј¬ЦчТӘЧчУГКЗҪУКХДҝұкҪЪөг·ўіцөДРЕәЕІўЙПҙ«КэҫЭЈ»өЪ¶юАаКЗЧчОӘДҝұкҪЪөгөДұкЗ©Ј¬ЖдЦчТӘЧчУГКЗЧчОӘҙэІвДҝұкёш»щХҫ·ўЛНРЕәЕЎЈ
UWB КТДЪ¶ЁО»ПөНіЦчТӘКЗТФёчёцҪЪөгЦ®јд·ўЛНРЕәЕөДМШХчЧчОӘІвҫаТАҫЭЈ¬Жд¶ЁО»·ҪіМ№№ҪЁЛг·ЁУР»щУЪРЕәЕөҪҙпҪЗ¶ИЈЁAOA,angel of arrivalЈ©Ўў»щУЪөҪҙпКұјдЈЁTOA,time of arrivalЈ©өИЎЈұҫОДІЙУГ»щУЪөҪҙпКұјдІоЈЁTDOA,time difference of arrivalЈ©[18]¶ЁО»·ҪіМ№№ҪЁЛг·ЁЎЈ
ФЪ№№ҪЁ¶ЁО»ДЈРНЦ®З°Ј¬КЧПИТӘ·ЦОцUWB КТДЪ¶ЁО»ПөНіөДОуІоФҙЈ¬ҝЙТФ·ЦОӘПөНіОуІоЎў»·ҫіОуІоЎўЛг·ЁОуІо3 Аа[19]Ј¬ИзНј1 ЛщКҫЎЈ
Нј1 UWB ¶ЁО»ОуІо
UWB ¶ЁО»ПөНіөДБҪАаПөНіОуІоОӘКұЦУН¬ІҪОуІоәНКұЦУЖҜТЖ[20]ОуІоЎЈКұЦУН¬ІҪОуІоКЗЦёBS УлTagЙиұёЦ®јдөДКұЦУІўІ»НкИ«Н¬ІҪЈ¬К№BS ҪУКХөҪTag·ўЛНРЕәЕКұјдУлХжКөөДРЕәЕөҪҙпКұјдІ»Т»ЦВЈ¬ҙУ¶шҪөөНБЛ¶ЁО»ҫ«¶ИЎЈКұЦУЖҜТЖОуІоКЗУЙёчёцРҫЖ¬өДҫ§ХсЖөВКІ»Н¬өјЦВөДЎЈФЪКөјКПөНіЦРЈ¬ҝЙНЁ№эКұЦУН¬ІҪҙҰАнј°өчХыРҫЖ¬өДҫ§ХсЖөВКҪөөНТФЙПОуІоЎЈ
»·ҫіОуІоКЗКөјК¶ЁО»ЦРУ°ПмЧоҙуөДТтЛШЈ¬УР¶аҫ¶ёЙИЕОуІо[21]ЎўNLOS ОуІо[22]әНёЯЛ№°ЧФлЙщОуІоөИЎЈ¶аҫ¶ёЙИЕОуІоКЗУЙРЕәЕЖөВКСЎФсРФЛҘВдТэЖрөДЈ¬ө«КЗUWB РЕәЕҫЯУРБјәГөДЖөВК·ЦұжВКЈ¬№КҝЙТФФЭКұәцВФҙЛУ°ПмЎЈNLOS ОуІоөДІъЙъФӯТтКЗФЪёҙФУөДКТДЪ»·ҫіЦРКЬөҪ¶аЦЦХП°ӯОпөДЧиөІЈ¬ФміЙБЛTag ·ўЙдРЕәЕІ»ДЬСШЦұПЯҙ«ІҘөҪBSЈ¬К№ФӯұҫөДІвБҝКұјдСУіӨЈ¬ҪөөНБЛ¶ЁО»ҫ«¶ИЎЈёЯЛ№°ЧФлЙщОуІоКЗРЕәЕФЪҝХјдҙ«ІҘ№эіМЦРЖХұйҙжФЪөДТ»ЦЦОуІоЎЈ
јЩЙи¶ФУЪДіТ»ёцBS ¶шСФЈ¬Tag УлёГBS Ц®јдөДЗйҝцКЗЛжЧЕКұјдФЪLOS УлNLOS ЦРІ»¶ПЧӘ»»өДЎЈИз№ыІ»ДЬј°КұөШ·ЦұжХв2 ЦЦРЕәЕЈ¬Іў¶ФЖдҪшРРККөұҙҰАнЈ¬Фт»бөјЦВ¶ЁО»Ҫб№ыОуІоФцјУЎЈОӘБЛХжКөГиКцКТДЪёҙФУ¶ЁО»»·ҫіЈ¬ұҫОДјЩЙи
ЖдЦРЈ¬PLOSәНPNLOS·ЦұрОӘёҙФУКТДЪ¶ЁО»»·ҫіПВLOSәНNLOS іцПЦөДёЕВКЎЈ
Лг·ЁОуІоКЗ¶ЁО»ҪвЛгЛг·ЁФЪҪв¶ЁО»·ҪіМКұІъЙъөДЈ¬ЖдҙуРЎұнХчБЛІ»Н¬¶ЁО»Лг·ЁөДРФДЬЎЈ
1.2 UWB КТДЪ¶ЁО»ҪЁДЈ
UWB КТДЪ¶ЁО»ПөНіНЁіЈ»щУЪІ»Н¬өДІвБҝІОКэҪЁБўІ»Н¬өДКТДЪ¶ЁО»ДЈРНЎЈДҝЗ°Ј¬іЈУГөДДЈРНУРІҙЛЙДЈРНЎўPOCA-NAZA ДЈРНЎўS-V ДЈРНЎўЛ«ҙШДЈРНәНIEEE802.15.4a ДЈРН[23]өИЎЈЖдЦРЈ¬IEEE802.15.4aДЈРНКЗПЦҪЧ¶ОСРҫҝЧо¶аөДДЈРНЎЈТтҙЛЈ¬ұҫОДёщҫЭҙЛұкЧјҪЁБўКТДЪ¶ЁО»ДЈРНЎЈ
ҝјВЗТ»ёцКТДЪ¶ЁО»ПөНіЦРУРNёцBS әНТ»ёцTagЈ¬ЖдЦРЈ¬BSi= [xi,y i,zi]TКЗөЪiёцBS өДО»ЦГЈ¬Tag УлөЪiёцBS Ц®јдөДІвБҝҫаАлҝЙұнКҫОӘ[24]
ЖдЦРЈ¬c=3ЎБ108m/s ОӘ№вЛЩЈ»ҰУiОӘTag РЕәЕөҪҙпBSiөДКұјдЈ¬өҘО»ОӘsЈ»DiОӘTag РЕәЕөҪҙпBSiөДХжКөҫаАлЈ¬өҘО»ОӘcmЈ»n iОӘВъЧгNЎ« (0,)·ЦІјөДјУРФ°ЧёЯЛ№ФлЙщЎЈ
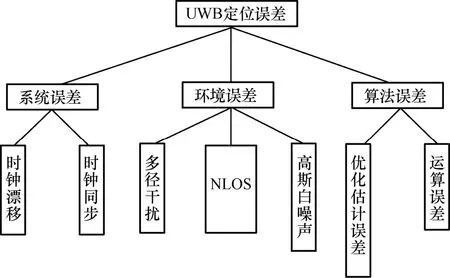
IEEE802.15.4a өДСРҫҝҪб№ыұнГчЈ¬КТДЪЗйҝцПВNLOS ОуІоөД·ЦІјВъЧгNakagami-m ·ЦІјЈ¬Ждҫщ·ҪёщКұСУА©Х№ҰУRMSәНЖҪҫщі¬БҝКұСУҰМУРҪьЛЖ1:1 өД№ШПөЎЈТтҙЛЈ¬NLOS ОуІо·юҙУЦёКэ·ЦІјЈ¬ЖдёЕВКГЬ¶ИәҜКэОӘ
ЖдЦРЈ¬ҰУRMSҝЙҝҙЧчВъЧг¶ФКэХэМ¬·ЦІјөДЛж»ъұдБҝЎЈұн1 ёшіцБЛIEEE802.15.4a ЦРКТДЪЧЎХ¬әНКТДڰ칫КТөДҰУRMSЈ¬ЖдЦРЈ¬ҰМNLOSәНҰТNLOS·ЦұрКЗҰУRMSөДҫщЦөәНұкЧјІоЎЈ
ұн1 IEEE802.15.4a ЦРКТДЪЧЎХ¬әНКТДڰ칫КТөД ҰУRMS
ёщҫЭЙПКцЗйҝцЈ¬ФЪёҙФУөДКТДڰ칫КТ»·ҫіЦРЈ¬UWB КТДЪ¶ЁО»өДҫаАлДЈРНҝЙТФҪЁДЈОӘ
ЖдЦРЈ¬ҰУiNLOSОӘTag өҪBSiөДNLOS КұјдЈ¬biОӘTagөҪBSiөДNLOS ҫаАлЎЈУЙУЪҰУiNLOSВъЧг¶ФКэХэМ¬·ЦІјЈ¬ЖдЦөТ»¶ЁОӘХэЈ¬јҙВъЧг
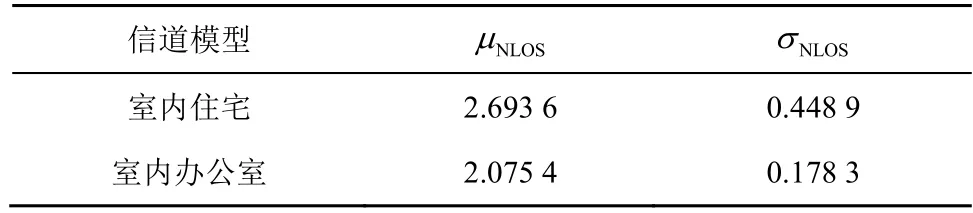
TDOA ЦчТӘТАҫЭЛ«ЗъПЯМШРФКөПЦ¶ЁО»ЎЈёГЛг·ЁЦ»РиТӘҪ«BSiҪшРРКұјдН¬ІҪЈ¬І»РиТӘTag УлBSiЦ®јдҪшРРКұјдН¬ІҪЈ¬ёь·ыәПКөјКЗйҝцЈ¬ҪөөНБЛКұјдН¬ІҪФміЙөДОуІоЎЈёГЛг·ЁКөПЦөДҫЯМеІҪЦиОӘКЧПИҪ«ТСЦӘөДBSiҪшРРКұјдН¬ІҪЈ¬УЙTag ПтBSi·ўЙдРЕәЕЈ¬BSiјЗВјПВРЕәЕЛщөҪҙпөДКұјдҙБЈ¬ІўҪ«ЖдКэҫЭЙПҙ«ёшЙПО»»ъЎЈИ»әуТФBSiОӘ»щөгЈ¬УГBSj(jЎЩi)КХөҪРЕәЕөДКұјдјхИҘBSiКХөҪРЕәЕөДКұјдЈ¬ҫНКЗөҪҙпКұјдІоЎЈёщҫЭЛ«ЗъПЯөД¶ЁТеЈ¬ҪЁБўN-1 ёцЛ«ЗъПЯ·ҪіМЈ¬ҝЙөГөҪTag өДҫЯМеО»ЦГЎЈTDOA ¶ЁО»Лг·ЁИзНј2 ЛщКҫЎЈ
Нј2 TDOA ¶ЁО»Лг·Ё
Нј2 ЦРЈ¬BS1ЎўBS2ЎўBS3ЎўB S4·ЦұрОӘ4 ёцТСЦӘҪЪөгЈ¬ТФBS1ОӘ»щЧј»ӯ3 ёцЛ«ЗъПЯЈ¬ЛьГЗөДҪ»өгјҙTagЎЈјЩЙи4 ёцТСЦӘBS өДЧшұк·ЦұрОӘ (x1,y1,z1)Ўў(x2,y2,z2)Ўў(x3,y3,z3)Ўў(x4,y4,z4)Ј¬Tag ОӘОҙЦӘҪЪөгЈ¬ЖдЧшұкОӘ(x,y,z)Ј¬УЙЙПКц·ЦОцҝЙөГ
ЖдЦРЈ¬D iұнКҫBSiөҪTag өДКөјКҫаАлЈ¬DjұнКҫBSjөҪTag өДКөјКҫаАлЈ¬DijұнКҫTag өҪBSiөДҫаАләНTag өҪBSjөДҫаАлөДІоЦөЈ¬ҰУijұнКҫTag ·ўЛНөДРЕПўөҪҙпBSiөДКұјдәНTag ·ўЛНөДРЕПўөҪҙпBSjөДКұјдөДІоЦөЎЈ
Ҫ«КҪ(8)ҙъИлҫЯМеКэҫЭІў»ҜОӘҫШХуРОКҪ
ҝЙҪвіцTag өДҫЯМеО»ЦГОӘ
1.3 »щУЪCHAN өДҝЁ¶ыВьВЛІЁЛг·Ё
CHAN ¶ЁО»ҪвЛгЛг·ЁКЗТ»ЦЦҫЯУРұХКҪҪвөД¶юІҪјУИЁЧоРЎ¶юіЛЛг·Ё[25]Ј¬ФЪФлЙщВъЧгёЯЛ№·ЦІјөДЗйҝцПВҫЯУРҪПәГөДЛг·ЁРФДЬЈ¬№г·әУҰУГУЪёчёціЎҫ°ЎЈёГЛг·Ё·ЦОӘЛД»щХҫ¶ЁО»Ул¶а»щХҫ¶ЁО»Ј¬ұҫОДІЙУГөДКЗәуХЯЎЈ
ЙиZa= [Zp,D1]TОӘ Tag ОҙЦӘөДО»ЦГРЕПўЈ¬Zp=[x,y,z]TОӘTag ФЪЧшұкПөЦРөДҫЯМеО»ЦГЈ¬ёщҫЭКҪ(9)ҝЙөГ
УГҫШХуQҙъМжОуІоКёБҝҰЕөДРӯ·ҪІоҫШХуҰ·Ј¬ІўНЁ№эјУИЁЧоРЎ¶юіЛ·ЁЗуҪвКҪ(15)ҝЙөГ
ЖдЦРЈ¬ZaЦРөДZpјҙTag ҫЯМеЧшұкЎЈЙПКц№эіМЦРУГРӯ·ҪІоҫШХуQҙъМжОуІоКёБҝҰЕөДРӯ·ҪІоҫШХуҰ·Ј¬ФцјУБЛТ»¶ЁОуІоЈ¬ОӘБЛҪөөНХвІҝ·ЦОуІоөДУ°ПмЈ¬ТӘ¶ФЙПКцөД№эіМҪшРРҪшТ»ІҪУЕ»ҜЈ¬јҙҪшРР¶юІҪјУИЁЧоРЎ¶юіЛЛг·ЁөДФЛЛг
өГөҪөД№АјЖҪб№ыОӘ
ҝЁ¶ыВьВЛІЁЖч[26]ТІұ»іЖОӘЧојСПЯРФВЛІЁЖчЈ¬УГУЪҪвҫцЧҙМ¬№АјЖОКМвЦРөДПЯРФПөНіЎЈЖдЦчТӘНЁ№э¶ФКдИлөДФӨІвЦөәН№ЫІвЦөҪшРРВЛІЁҙҰАнЈ¬К№№АјЖҪб№ыёьјУҪУҪьХжКөЦөЎЈҝЁ¶ыВьВЛІЁЛг·ЁөДЧҙМ¬ҝХјдДЈРНОӘ
ЖдЦРЈ¬kОӘАлЙўКұјдЈ¬X(k) ЎКRnОӘПөНіФЪКұҝМkөДЧҙМ¬Ј¬Y(k) ЎКRmОӘ¶ФУҰЧҙМ¬өД№ЫІвРЕәЕЈ»W(k) ЎКRrОӘКдИлөД°ЧФлЙщЈ¬V(k) ЎКRmОӘ№ЫІвФлЙщЈ»ҰөОӘЧҙМ¬ЧӘТЖҫШХуЈ¬ҰЈОӘФлЙщЗэ¶ҜҫШХуЈ¬HОӘ№ЫІвҫШХуЎЈҪ«CHAN Лг·ЁөД¶ЁО»Ҫб№ыЧчОӘҝЁ¶ыВьВЛІЁЖчөДКдИлБҝ
ЧҙМ¬Т»ІҪФӨІвОӘ
ЧҙМ¬ёьРВОӘ
ВЛІЁФцТжҫШХуОӘ
Т»ІҪФӨІвРӯ·ҪІоҫШХуОӘ
Рӯ·ҪІоҫШХуёьРВОӘ
ЖдЦРЈ¬P(k|k)әНP(k+1|k)·ЦұрОӘ¶ФУҰ№АјЖҪб№ыөДРӯ·ҪІоҫШХуЈ»RОӘІвБҝФлЙщҫШХуЈ»KОӘҝЁ¶ыВьВЛІЁФцТжЈ¬КЗёщҫЭРӯ·ҪІоҫШХуәНІвБҝОуІоҫШХуҫц¶ЁөДЦөЈ¬KЦөФҪҙуЈ¬ҙъұнФҪПаРЕ№ЫІвЦөЈ¬KЦөФҪРЎЈ¬ҙъұнФҪПаРЕФӨІвЦөЈ»(k|k)ОӘЙПТ»ёцЧҙМ¬өДЧоУЕ№АјЖҪб№ыЈ¬(k+1|k+1)ОӘөұЗ°Кұјд»щУЪCHAN өДҝЁ¶ыВьВЛІЁөД¶ЁО»Ҫб№ыЎЈ
ХыМе¶шСФЈ¬ҝЁ¶ыВьВЛІЁКЗТ»ёцІ»¶ПөьҙъІўЗТУЕ»ҜЖдІОКэөД№эіМЈ¬ЖдЧоУЕ№АјЖҪб№ыФҪАҙФҪұЖҪьХжКөЦөЎЈёГЛг·ЁУРР§өШҪөөНБЛCHAN Лг·ЁФЪNLOS »·ҫіПВөДОуІоЎЈИ»¶шЈ¬ОӘБЛұЈЦӨҝЁ¶ыВьВЛІЁөьҙъөДЧјИ·РФЈ¬РиТӘФЪіхКјО»ЦГёшТ»ёцЦё¶ЁөДіхЦөЈ¬ХвёціхЦөұШРлВъЧгУлұкЗ©өДКөјКО»ЦГҪУҪь[24]Ј¬·сФт»б¶ФәуРшөДөьҙъ№эіМІъЙъЖ«ТЖЈ¬өјЦВ¶ЁО»Ҫб№ыОуІоФцҙуЎЈЖдҙОЈ¬УЙУЪҝЁ¶ыВьВЛІЁКЗТ»Б¬РшУЕ»ҜөД№эіМЈ¬ЙПТ»КұҝМөДРӯ·ҪІоҫШХуУ°ПмПВТ»КұҝМөДО»ЦГРЕПўЎЈФЪёҙФУөДКТДЪ»·ҫіЦРЈ¬ҙжФЪLOS УлNLOS РЕәЕ№ІҙжІўЗТЖө·ұЧӘ»»өДЗйҝцЈ¬ХвК№Рӯ·ҪІоҫШХуұИҪПДСЕР¶ПёГКұҝМөД¶ЁО»РЕПўКЗ·сЧјИ·Ј¬ҙУ¶шөјЦВПВТ»КұҝМөДРӯ·ҪІоҫШХуКЬөҪУ°ПмЈ¬ЦрҪҘІъЙъАЫјЖОуІоЎЈУлҙЛН¬КұЈ¬¶ФУЪТ»ёц»щХҫ¶шСФЈ¬јЩЙиLOS РЕәЕУлNLOS РЕәЕіцПЦөДёЕВККЗПаөИөДЈ¬»бК№ҝЁ¶ыВьВЛІЁФцТжПөКэKТ»ЦұО¬іЦФЪ0.5 ЧуУТЈ¬ҪөөНБЛҝЁ¶ыВьВЛІЁөДҫ«¶ИЎЈ
2 »щУЪCHAN өДёДҪшҝЁ¶ыВьВЛІЁЛг·Ё
ОӘБЛҪвҫцЙПКцОКМвЈ¬ҝјВЗөҪёҙФУКТДЪіЎҫ°ЦРLOS/NLOS іЎҫ°Жө·ұЗР»»өДМШРФЈ¬¶ФLOS/NLOS »щХҫҙжФЪКэДҝҪшРРЦГРЕЗшУтөД»®·ЦЎЈН¬КұЈ¬ҝјВЗөҪCHAN Лг·ЁФЪNLOS ЗйҝцУлLOS ЗйҝцПВ¶ЁО»ОуІоПаІоҪПҙуЈ¬Ҫ«ЖдЧчОӘЦГРЕЗшУтөДЕРұрТАҫЭЎЈЧоәуЈ¬ёщҫЭ»®·ЦөДІ»Н¬ЗшУтЈ¬СЎФсәПККөДВЛІЁФцТжПөКэKМбёЯ¶ЁО»ҫ«¶ИЎЈ
¶ФУЪ¶а»щХҫөД¶ЁО»¶шСФЈ¬BS1ҪУКХTag ҙ«КдөДРЕәЕКЗФЪLOS іЎҫ°ПВЈ¬ө«КЗBS2ҪУКХTag ҙ«КдөДРЕәЕКЗФЪNLOS іЎҫ°ПВЈ¬ХвҫНөјЦВ¶ЁО»»·ҫіёҙФУ¶ИөДФцјУЎЈ
ҝјВЗөҪCHAN ·Ҫ·ЁФЪLOS »щХҫҙуУЪ4 ёцКұ¶ЁО»ҫ«¶ИҪПёЯЈ¬Ҫ«Жд¶ЁО»Ҫб№ыәНёчёц»щХҫөДО»ЦГҪшРРІРІоІўЧчОӘЗшУтЕРұрөДЦГРЕТтЧУЎЈ
јЩЙиЧЬ№ІУРNёцBSЈ¬ФЪИэО¬¶ЁО»ЦРұШРлУР4 ёцBS ІЕДЬҪвЛгіцTag ЧшұкЈ¬СЎИЎЖдЦРИОТвЈЁl lЈҫ4Ј©ёц»щХҫОӘТ»ЧйЈ¬ЧЬ№ІУРMЦЦЧйәПЈ¬ЖдЦөОӘ
ЛчТэјҜОӘ{Sr,r= 1,2,Ўӯ,M}ЎЈІРІо¶ЁТеОӘ
НЁ№э¶ФёГІвБҝКұҝМјЖЛгөДMЧйІРІоЦөҪшРР№йТ»»ҜҙҰАнЈ¬өГөҪөұЗ°ІвБҝКұҝМөДЦГРЕТтЧУОӘ
ЖдЦРЈ¬ҰБОӘЦГРЕТтЧУЈ¬КЗЗшУтЕРұрЦёұкЎЈН¬КұЈ¬¶ФГҝТ»ІвБҝКұҝМөДMЧйІРІојУИЁЈ¬өГөҪҙЛІвБҝКұҝМөД¶ЁО»Ҫб№ыОӘ
КҪ(35)КЗёГКұҝМЛщУРЧйәПІРІојУИЁөД№эіМЎЈІРІоЦөФҪҙуЈ¬ЛөГч¶ЁО»Ҫб№ыФҪІоЈ»ІРІоФҪРЎЈ¬ЛөГч¶ЁО»Ҫб№ыФҪәГЎЈТтҙЛЈ¬·ЦДёОӘёГКұҝМЛщУРЧйәПЗйҝцөДІРІоЦөө№КэЦ®әНЈ¬·ЦЧУОӘёГКұҝМөЪrЦЦЧйәПөДTagО»ЦГУлЖдІРІоө№КэЦ®»эЎЈҝјВЗөҪЦГРЕТтЧУҰБұнКҫІ»Н¬ЗшУтДЪ¶ЁО»Ҫб№ыөДҝЙРЕіМ¶ИЎЈҪ«¶ЁО»өДЗшУт»®·ЦОӘ3 ёцЈ¬јҙ
ЖдЦРЈ¬KnewОӘёщҫЭІ»Н¬ЦГРЕЗшУтСЎФсөДҝЁ¶ыВьВЛІЁФцТжЈ¬ҰБОӘЦГРЕТтЧУЈ¬ҰД1әНҰД2ОӘ»®·ЦЦГРЕЗшУтөДгРЦөЎЈАэИзЈ¬ФЪ·ВХжЙиЦГ»·ҫіЦРЈ¬УЙ¶аҙОІвБҝҝЙөГіцЈ¬ҰД1әНҰД2өДИЎЦө·ЦұрОӘ0.3 әН0.5ЎЈФЪЦГРЕЗшУтЦРЈ¬ҰД1ЎўҰД2әНВЛІЁФцТжKnewВъЧгФЪҝЙРЕЗшУтЦРВЛІЁФцТжKnewёьјУПаРЕІвБҝҪб№ыЈ¬ҙЛКұҰБФЪ0 әНҰД1Ц®јдЈ»ФЪДЈәэЗшУтЦРЈ¬ВЛІЁФцТжKnew»бККөұөШөчХыІвБҝҪб№ыәНФӨІвҪб№ыөД№ШПөЈ¬ҙЛКұҰБФЪҰД1әНҰД2Ц®јдЈ»ФЪІ»ҝЙРЕЗшУтЦРЈ¬ВЛІЁФцТжKnewёьјУПаРЕФӨІвҪб№ыЈ¬ҙЛКұҰБФЪҰД2әН1 Ц®јдЎЈ
ёщҫЭІ»Н¬ЗшУтСЎФсІ»Н¬өДҝЁ¶ыВьВЛІЁФцТжKnewЈ¬ІўҪ«өұЗ°ІвБҝКұҝМөД¶ЁО»Ҫб№ыxTagҙъИлІ»Н¬өДЗшУтҪшРРҝЁ¶ыВьВЛІЁЎЈ
Па¶ФУЪ»щҙЎөДҝЁ¶ыВьВЛІЁ№эіМЈ¬ёГ№эіМЦ»ёьёДБЛЧҙМ¬ёьРВәНРӯ·ҪІоёьРВ·ҪіМөДВЛІЁФцТжТтЧУ
»щУЪCHAN өДёДҪшҝЁ¶ыВьВЛІЁЛг·ЁБчіМИзНј3ЛщКҫЎЈ
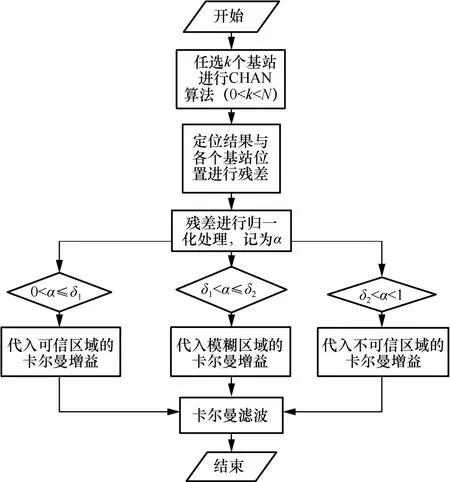
Нј3 »щУЪCHAN өДёДҪшҝЁ¶ыВьВЛІЁЛг·ЁБчіМ
ұҫОДЛг·ЁҪвҫцБЛҝЁ¶ыВьВЛІЁФЪ¶ЁО»іхКјКұ¶ЁО»ҫ«¶ИІ»ёЯәНҝЁ¶ыВьВЛІЁФцТжKФЪёҙФУКТДЪ¶ЁО»іЎҫ°ПВІъЙъРВОуІоөДОКМвЈ¬ҫЯУРІ»ҙнөД¶ЁО»ҫ«¶ИЎЈ
3 КөСйУл·ЦОц
3.1 ·ВХжКөСйКэҫЭ№№ҪЁ
ұҫОДКөСйЦчТӘ·ЦОцФЪёҙФУКТДЪ»·ҫіПВЈ¬ёчЦЦКТДЪ¶ЁО»Лг·ЁөДҫ«¶ИЎЈјЩЙиФЪ1 000 cmЎБ1 000 cmЎБ1 000 cm өДёҙФУКТДЪҝХјдҙжФЪ8 ёцBSЈ¬ЖдLOS РЕәЕәНNLOS РЕәЕөДёЕВК¶јОӘ50%Ј¬ЗТОӘЛж»ъІъЙъЎЈТ»ёцОпМеөДФЛ¶Ҝ№мјЈОӘҙУЈЁ200,200,200Ј©өҪЈЁ700,700,700Ј©өДФИЛЩЦұПЯФЛ¶ҜЈ¬ёГОпМеФЪГҝёц·ҪПтЙПөДјУЛЩ¶И¶јОӘ20 cm/sЈ¬УЙУЪОпМеФЛ¶ҜКұҙжФЪТ»¶ЁОуІоЈ¬ЖдёЕВК·ЦІјВъЧгјУРФ°ЧёЯЛ№ФлЙщЈ¬ҰШөДИЎЦөОӘ10 cmЎЈТтҙЛЖдХжКөФЛ¶Ҝ№мјЈИзНј4 ЛщКҫЎЈ
Нј4 ХжКөФЛ¶Ҝ№мјЈ
ФЪUWB КТДЪ¶ЁО»ЦРЈ¬ёщҫЭIEEE802.15.4aҝЙЦӘЈ¬Йи¶ЁІвБҝОуІоөДұкЧјІо·ыәПёЯЛ№·ЦІјЈ¬ЖдҫщЦөОӘ0Ј¬·ҪІоОӘ10 cmЈ»NLOS өДҫщ·ҪёщКұСУА©Х№ҰУRMSВъЧг¶ФКэХэМ¬·ЦІјЈ¬ҫщЦөОӘ2.075 4 cmЈ¬·ҪІоОӘ0.178 3 cmЎЈёщҫЭ¶аҙОКэҫЭөДІвБҝЈ¬гРЦөҰД1=0.3Ј¬ҰД2=0.5ЎЈҝЙРЕЗшУтҙъұн8 ёцBS ЦРУР5 ёцј°ТФЙПBS өДҪУКХРЕәЕОӘLOS ЗйҝцЈ¬ДЈәэЗшУтҙъұнҙжФЪ3Ў«4 ёцBS өДҪУКХРЕәЕОӘLOS ЗйҝцЈ¬І»ҝЙРЕЗшУтҙъұнөНУЪ2 ёцBS өДҪУКХРЕәЕОӘLOS ЗйҝцЎЈУЙУЪCHAN Лг·ЁФЪ5 ёц»щХҫКұҫНУРәЬёЯҫ«¶ИЈ¬ТтҙЛұҫОДСЎИЎk=5ЎЈ
ЧЫЙПЈ¬ұҫҪЪ№№ҪЁБЛТ»ёцLOS РЕәЕәНNLOS РЕәЕёЕВКПаөИөДёҙФУКТДЪ¶ЁО»іЎҫ°Ј¬ЖдІОКэ»щұҫ·ыәППЦКөЗйҝцЎЈ
3.2 ·ВХжКөСйКэҫЭ·ЦОц
ОӘБЛід·ЦЛөГчұҫОДЛг·ЁөДРФДЬЈ¬·ВХжКөСйСЎИЎ3 ЦЦПа№Ш¶ЁО»Лг·ЁУлұҫОДЛг·ЁҪшРР·ЦОц¶ФұИЈ¬·ЦұрОӘҙ«НіөДCHAN Лг·Ё[8]Ўў»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·Ё[15]әНCHAN+ҝЁ¶ыВьВЛІЁЛг·Ё[16]ЎЈ
Нј5Ў«Нј8 ОӘҙ«НіөДCHAN Лг·ЁЎўРӯН¬¶ЁО»Лг·ЁЎўCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁәНCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөД¶ЁО»КҫТвЈ¬ФЛРРҙОКэОӘ10 000 ҙОАҙұЈЦӨКөСйөДЧјИ·РФЎЈНј5 КЗИэО¬ҝХјдДЪ4 ЦЦЛг·ЁөД¶ЁО»Ҫб№ыЎЈҙУНј5 ҝЙТФГчПФөШҝҙіцЈ¬ҙ«НіөДCHAN Лг·ЁУЙУЪКТДЪ»·ҫіёҙФУЈ¬¶ЁО»Р§№ыәЬІоЈ¬ФЛ¶Ҝ№мјЈЖ«АлХжКө№мјЈҪПҙуЈ¬ЙхЦБіцПЦБЛПИ¶ЁО»өгФЪәу¶ЁО»өгЦ®З°өДЗйҝцЈ»»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·ЁУЙУЪ»щХҫ·ЦЧйөД·ЗАнПл»ҜУ°ПмЈ¬ТАИ»ҙжФЪТ»¶ЁөД¶ЁО»ОуІоЈ»CHAN+ҝЁ¶ыВьВЛІЁЛг·ЁУЙУЪҝЁ¶ыВьВЛІЁөДјУИлЈ¬Т»¶ЁіМ¶ИЙПҪөөНБЛ¶ЁО»өДNLOS ОуІоЈ¬ФЛ¶Ҝ№мјЈёьјУЖҪ»¬Ј¬ҪУҪьХжКөФЛ¶Ҝ№мјЈЎЈө«КЗУЙУЪФЪіхКј¶ЁО»КұФцТжЦөСЎИЎөДОКМвЈ¬ФЪФЛ¶ҜіхКј¶ЁО»өД№эіМЦРЈ¬ІъЙъБЛҪПҙуөД¶ЁО»Ж«ТЖЗйҝцЈ»CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁКЗ4 ЦЦ¶ЁО»Лг·ЁЦР¶ЁО»ОуІоЧоөНөДЛг·ЁЈ¬Жд¶ЁО»№мјЈёьјУҪУҪьХжКө№мјЈЎЈН¬КұЈ¬ФЪіхКј¶ЁО»өД№эіМЦРЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁҙУіхКј¶ЁО»КұҫНҪУҪьХжКөөД¶ЁО»№мјЈЈ¬УРҪПөНөД¶ЁО»ОуІоЈ¬ПаұИЗ°3 ЦЦЛг·ЁөД¶ЁО»№мјЈУРБЛГчПФөДРЈХэЈ¬ҪвҫцБЛҝЁ¶ыВьВЛІЁФЪіхКјО»ЦГ¶ЁО»ҫ«¶ИІ»ёЯөДОКМвЎЈЧЫЙПЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁПаұИБнНв3 ЦЦЛг·ЁФЪ¶ЁО»ҫ«¶ИәН¶ЁО»ОИ¶ЁРФЙП¶јУРҪПҙуМбЙэЎЈ
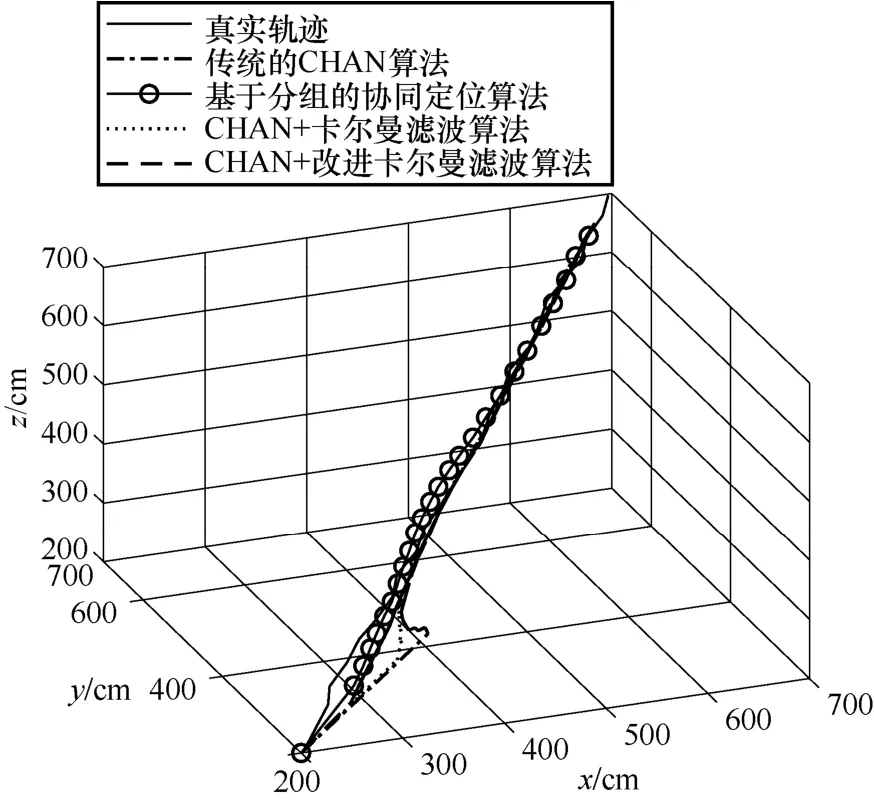
Нј5 ИэО¬ҝХјдДЪ4 ЦЦЛг·ЁөД¶ЁО»Ҫб№ы
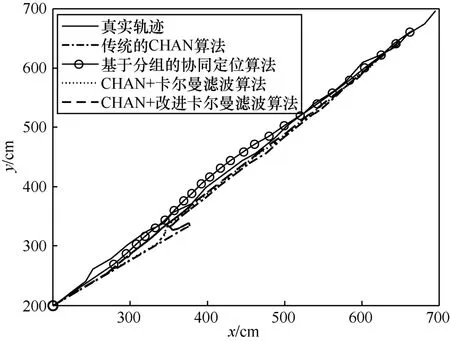
Нј6 x-y ФЛ¶Ҝ№мјЈ
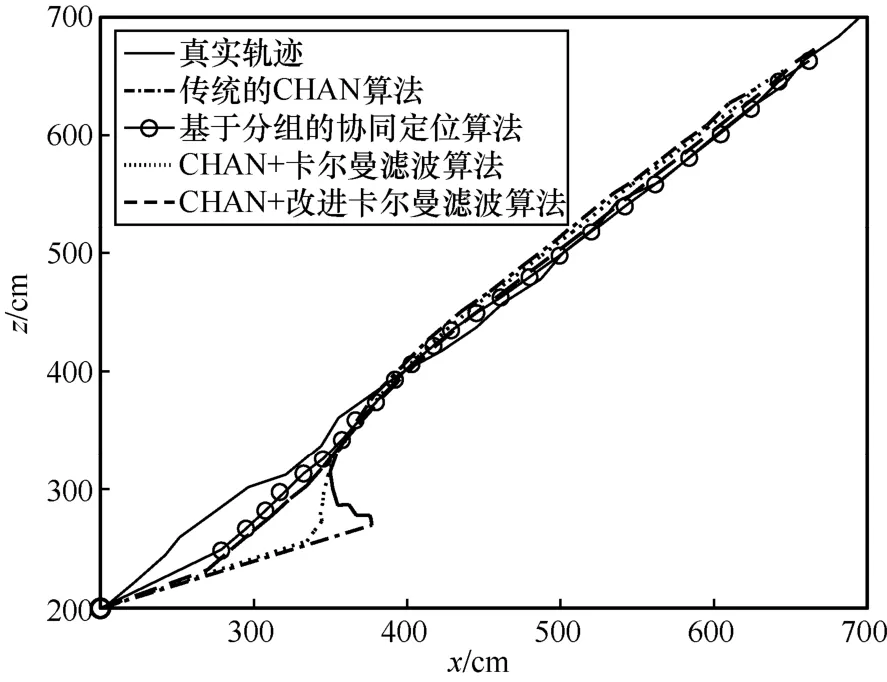
Нј7 x-z ФЛ¶Ҝ№мјЈ
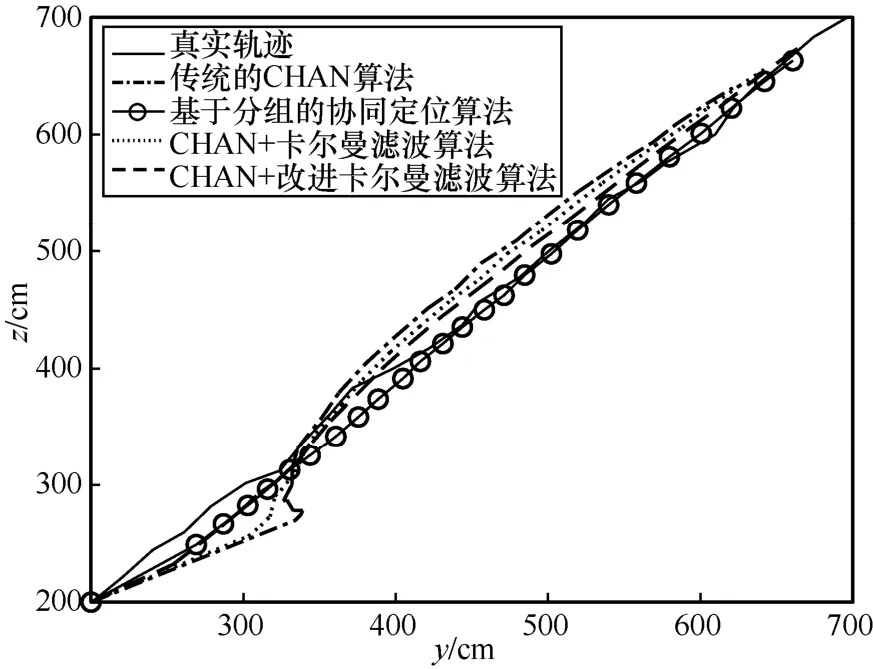
Нј8 y-z ФЛ¶Ҝ№мјЈ
Нј9 ПФКҫБЛ4 ЦЦКТДЪ¶ЁО»Лг·ЁөД¶ЁО»ОуІоЎЈҙУНј9 ҝЙТФҝҙіцЈ¬ҙ«НіөДCHAN Лг·ЁөД¶ЁО»ОуІоОИ¶ЁФЪ2.2 m ЧуУТЎЈ¶ФУЪРиТӘҫ«Чј¶ЁО»өДКТДЪ¶ЁО»АҙЛөЈ¬ҙ«НіөДCHAN Лг·ЁІ»ВъЧгЖдТӘЗуЎЈ»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·ЁКЬLOS УлNLOS Жө·ұЧӘ»»әНгРЦөЙи¶ЁөДУ°ПмЈ¬ОуІоФЪ1.8 m ЧуУТЎЈCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁөД¶ЁО»ОуІоФЪ1.0Ў«1.5 mЈ¬јЩЙиРиТӘ¶ЁО»өДФЛ¶ҜМеКЗИЛЈ¬ФтҙЛОуІоФЪИЛФЛ¶ҜөДәПАн·¶О§Ц®ДЪЈ¬ҝЙТФУГУЪЖХНЁөДКТДЪ¶ЁО»ЗйҝцЎЈҙУНј9 ЦРТІҝЙТФҝҙіцЈ¬CHAN+ҝЁ¶ыВьВЛІЁЛг·ЁФЪ¶ЁО»іхКјөДО»ЦГКұОуІоИФЖ«ҙуЎЈCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөД¶ЁО»ҫ«¶ИФЪ0.5Ў«1.0 mЈ¬·ыәПКТДЪҫ«Чј¶ЁО»өДТӘЗуЈ¬ҙпөҪБЛUWB ФЪГсУГКТДЪ¶ЁО»ЦРөД№ж·¶ЎЈН¬КұЈ¬ФЪ¶ЁО»іхКјөДЗйҝцПВЈ¬ТІВъЧгКТДЪҫ«Чј¶ЁО»өДРиЗуЎЈЧЬМе¶шСФЈ¬4 ЦЦ¶ЁО»Лг·ЁХыМеОуІоЗъПЯЖҪ»¬ЎЈФЪХыёц¶ЁО»№эіМЦРЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөД¶ЁО»ОуІоКјЦХұИЖдЛы3 ЦЦЛг·Ё¶ЁО»ОуІоТӘРЎЈ¬Улҙ«НіөДCHAN Лг·ЁПаұИЈ¬¶ЁО»ОуІоҪөөНБЛ1.5 mЈ»УлCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁПаұИЈ¬¶ЁО»ОуІоҪөөНБЛ0.5 mЎЈ
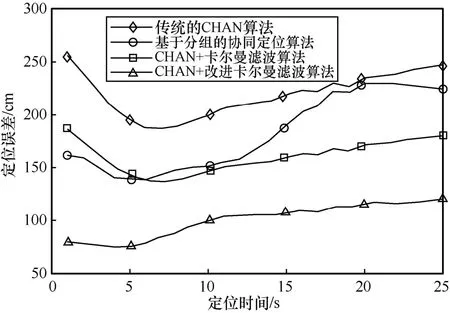
Нј9 4 ЦЦКТДЪ¶ЁО»Лг·ЁөД¶ЁО»ОуІо
ОӘБЛёьәГөШ¶ФұИ4 ЦЦЛг·ЁөД¶ЁО»ҫ«¶ИЈ¬ұн2 ёшіцБЛФЪ10 000 ҙО¶ЁО»Ҫб№ыПВЈ¬4 ЦЦ¶ЁО»Лг·ЁөДҫщ·ҪёщОуІоЈЁRMSE,root mean squared errorЈ©ЎЈФЪёҙФУөДКТДЪ»·ҫіПВЈ¬ҙ«НіөДCHAN Лг·ЁөДRMSE ФЪ2.2 m ТФЙПЈ¬УРГчПФөД¶ЁО»ОуІоЈ¬І»ДЬУГУЪКТДЪ¶ЁО»Ј»»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·ЁөДRMSE ФЪ2.0 m ЧуУТЈ¬ТІҙжФЪҪПҙуөДОуІоЈ»CHAN+ҝЁ¶ыВьВЛІЁЛг·Ё¶ЁО»ҫ«¶ИФЪ1.0 m ТФЙПЈ¬»щұҫ·ыәПКТДЪ¶ЁО»өДРиЗуЈ»CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөД¶ЁО»ҫ«¶ИФЪ0.8 m ЧуУТЈ¬Улҙ«НіөДCHANЛг·ЁәНCHAN+ҝЁ¶ыВьВЛІЁЛг·Ё¶ФұИЈ¬МбЙэБЛ60%әН34%Ј¬ҪөөНБЛёҙФУКТДЪ»·ҫіөД¶ЁО»ОуІоЎЈ

ұн2 ёч¶ЁО»Лг·ЁөДRMSE
Н¬КұЈ¬ФЪІ»Н¬¶ЁО»ІвБҝФлЙщұкЧјІоөДіЎҫ°ПВЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁИФИ»УөУРҪПәГөД¶ЁО»ҫ«¶ИЎЈИзНј10 ЛщКҫЈ¬ФЪ№М¶ЁБЛLOS/NLOS »щХҫөД·ЦІјЗйҝцПВЈ¬ЛжЧЕ¶ЁО»ІвБҝФлЙщұкЧјІоөДФцҙуЈ¬ёчЦЦ¶ЁО»Лг·ЁөД¶ЁО»ҫ«¶И¶јФЪҪөөНЈ¬·ыәПКөјКЗйҝцЎЈҙ«НіөДCHAN Лг·ЁКЬ¶ЁО»ІвБҝФлЙщұкЧјІоөДУ°ПмҪПҙуЈ¬ІвБҝФлЙщұкЧјІоФцјУөДЗйҝцПВЈ¬¶ЁО»ҫ«¶ИҪөөНөГК®·ЦГчПФЎЈ»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·ЁУЙУЪ¶ФNLOS РЕәЕҪшРРБЛјтөҘөДҙҰАнЈ¬¶шCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁәНCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛгФтКЗФЪҝЁ¶ыВьВЛІЁөьҙъ№эіМЦРЈ¬ёьРВЦКБҝУЕБУТтЧУPЛжЧЕ¶ЁО»өД№эіМЦрҪҘёДЙЖЈ¬ГЦІ№БЛІвБҝФлЙщұкЧјІоөДФцҙуЎЈТтҙЛЈ¬ПаҪПУЪҙ«НіөДCHAN Лг·ЁЈ¬»щУЪ·ЦЧйөДРӯН¬¶ЁО»Лг·ЁЎўCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁәНCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁКЬ¶ЁО»ІвБҝФлЙщұкЧјІоөДУ°ПмҪПРЎЎЈФЪН¬Т»ІвБҝФлЙщұкЧјІоөДЗйҝцПВЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁПаұИЖдЛы3 ЦЦЛг·ЁөДRMSE ёьРЎЈ¬УРёьәГөД¶ЁО»ҫ«¶ИЎЈФЪ¶ЁО»»·ҫіФҪАҙФҪ¶сБУөДЗйҝцПВЈ¬ҙ«НіөДCHAN Лг·ЁөДRMSE ЗчКЖІ»КХБІЈ¬¶ЁО»Р§№ыҪПІоЎЈCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁәНCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөДRMSE ЦрҪҘОИ¶ЁФЪ2.0 m әН1.8 m ЧуУТЈ¬¶ФУЪ¶ЁО»»·ҫіК®·Ц¶сБУөДЗйҝц¶шСФЈ¬ФЪҝЙҪУКЬ·¶О§ДЪЎЈ
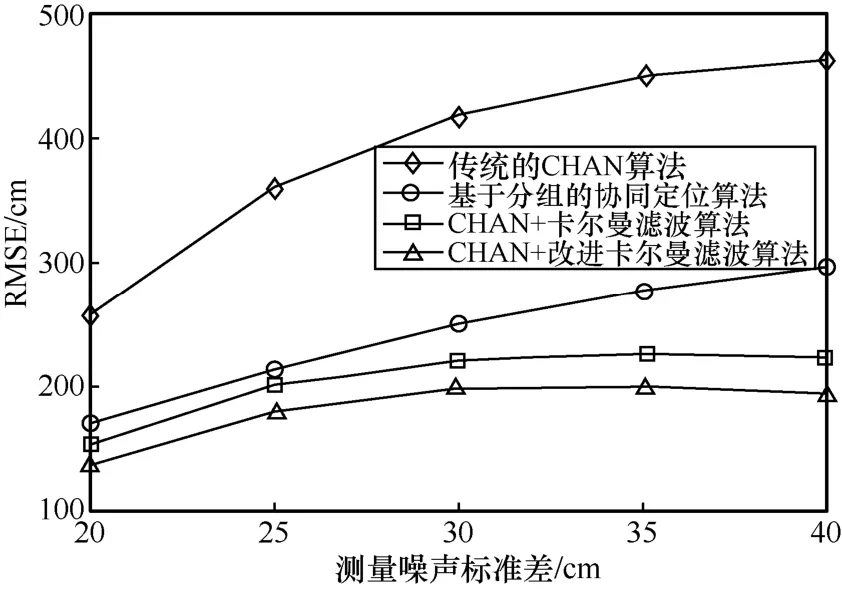
Нј10 RMSE УлІвБҝФлЙщұкЧјІоөД№ШПө
ұҫОДКөСй»№СйЦӨБЛҝЁ¶ыВьВЛІЁФцТжПөКэФЪіхКјЧҙМ¬ёДЙЖөДОКМвЈ¬ЙиҰӨKОӘCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁУлCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁФцТжПөКэөДІоЦөЈ¬ЖдУлКұјдөД№ШПөИзНј11 ЛщКҫЎЈҙУНј11 ҝЙТФҝҙіцЈ¬ҰӨKФЪіхКјЧҙМ¬КұҪУҪь-0.3Ј¬ЛөГчCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁУлCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁөДФцТжПөКэИЎЦөУРГчПФІ»Н¬Ј¬ЖдФӯТтКЗCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁФЪіхКј¶ЁО»КұВЛІЁФцТж»№ОҙёДЙЖЎЈПаұИCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁУЙУЪРиТӘ¶ФЦГРЕЗшУтҪшРРСЎФсЈ¬ёДЙЖБЛФцТжПөКэЈ¬ИГЖдёьҝмөШЗчУЪОИ¶ЁәНҫ«ЧјЎЈЛжЧЕКұјдөДНЖТЖЈ¬2 ЦЦЛг·ЁФцТжПөКэөДІоЦөЦрҪҘЛхРЎЈ¬ПөКэЦрҪҘПаөИЈ¬ХвЛөГчІ»Н¬ЗшУтФӨПИСЎФсөДФцТжЦөМбёЯБЛ¶ЁО»өДҫ«¶ИЎЈЧЫЙПЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁФЪіхКјЧҙМ¬КұҫНТСҫӯёДЙЖБЛФцТжПөКэЈ¬ҪөөНБЛУЙёҙФУКТДЪ»·ҫіІъЙъөДРВОуІоЎЈ

Нј11 ҰӨK УлФЛРРКұјдөД№ШПө
ЧоәуЈ¬ОӘБЛұнХчІ»Н¬¶ЁО»Лг·ЁЦ®јдөДёҙФУ¶ИЗшұрЈ¬јЗВјБЛёчЦЦ¶ЁО»Лг·ЁөДКөјКФЛРРКұјдЈ¬Изұн3ЛщКҫЎЈҙ«НіөДCHAN Лг·ЁөДКөјКФЛРРКұјдЧоҝмЈ¬¶шұҫОДМбіцөДCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁТӘҪшРР¶аҙОCHAN Лг·ЁҪвЛгЈ¬ІўёщҫЭҪвЛгҪб№ыУлёчёц»щХҫҪшРРІРІоЈ¬ЕРұрЦГРЕЗшУтәуФЩҪшРРҝЁ¶ыВьВЛІЁЈ¬ФцјУБЛЛг·ЁёҙФУ¶ИЈ¬ТтҙЛКөјКФЛРРКұјдЧоіӨЎЈө«КЗұҫОДЛг·ЁКөјКФЛРРКұјдИФИ»ВъЧг¶ЁО»КөКұҙҰАнөДТӘЗуЈ¬ҝЙФЪКөјК¶ЁО»ПөНіЦРК№УГЎЈ

ұн3 ёчЦЦ¶ЁО»Лг·ЁөДКөјКФЛРРКұјд
3.3 КөјК¶ЁО»»·ҫі
ёщҫЭЗ°ОДөД·ЦОцУл·ВХжСйЦӨЈ¬ұҫОДІЙУГCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁЧчОӘ¶ЁО»ПөНіөД¶ЁО»·Ҫ°ёЎЈ
ұҫОДКөСйКөјК»·ҫіОӘДі»бТйКТЈ¬ёГ»бТйКТіӨОӘ812 cmЈ¬ҝнОӘ404 cmЈ¬ёЯОӘ216 cmЈ¬ИЛРҜҙшUWB¶ЁО»ұкЗ©ФЪСЎИЎөД·¶О§ДЪ°ҙХХЦё¶ЁөД№мјЈҪшРРТЖ¶ҜЎЈ8 ёц¶ЁО»»щХҫІјЦГИзПВЈәЦч»ъХҫЧшұкОӘ(0,0,25)Ј¬ЖдУа»щХҫЧшұк·ЦұрОӘ(812,0,25)Ўў(812,404,25)Ўў(0,404,25)Ўў(0,0,216)Ўў(812,0,216)Ўў(812,404,216)Ўў(0,404,216)ЎЈФЪ»бТйКТДЪУРГчПФөДЧАТО°Ъ·ЕЈ¬Лж»ъХЪөІБЛІҝ·Ц»щХҫУлұкЗ©Ц®јдөДРЕәЕLOS ҙ«ІҘВ·ҫ¶Ј¬РОіЙБЛёҙФУөДКТДЪ»·ҫіЎЈёщҫЭ»бТйКТДЪ»щХҫөДЧшұк·ЦІјҝЙЦӘЈ¬ЖдЦРО»УЪ·ҝјд¶ҘІҝөД4 ёц»щХҫУлұкЗ©Ц®јдІўОЮХП°ӯОпХЪөІЈ¬ҙЛКұ4 ёц¶ҘІҝ»щХҫУлұкЗ©Ц®јдөДРЕәЕОӘLOS ҙ«КдРЕәЕЈ»¶шО»УЪ»бТйКТөЧІҝөД4 ёц»щХҫУлұкЗ©Ц®јдҙжФЪ»бТйКТЧАТОөДХЪөІЈ¬ёГ4 ёц»щХҫУлұкЗ©Ц®јдөДРЕәЕОӘNLOS ҙ«КдРЕәЕЈ¬КөјКІвКФ»·ҫіВъЧгЗ°ОДјЩЙиөДLOS әНNLOS РЕәЕ·ЦІјёЕВКЎЈ
3.4 ¶ЁО»КэҫЭ·ЦОц
ОӘБЛЦұ№ЫөШұнПЦІвКФөД№мјЈЈ¬ұҫОДКөСйөДұкЗ©ФЛРР№мјЈОӘФЪ»бТйЧАЙПөДТ»МхЦұПЯЈ¬ҫЯМеөДҝХјдЧшұкОӘ[350,215,40]өҪ[750,215,40]өДТ»МхЦұПЯЈ¬ө«КЗУЙУЪКөјКөД№мјЈІўІ»ДЬСПёсҝШЦЖОӘТ»МхЦұПЯЈ¬ТтҙЛНјЦРТФәЪЙ«өДАнПлФӨІв№мјЈЧчОӘІОҝј»щЧјЈ¬ҫЯМе¶ЁО»Ҫб№ыИзНј12Ў«Нј15 ЛщКҫЎЈ
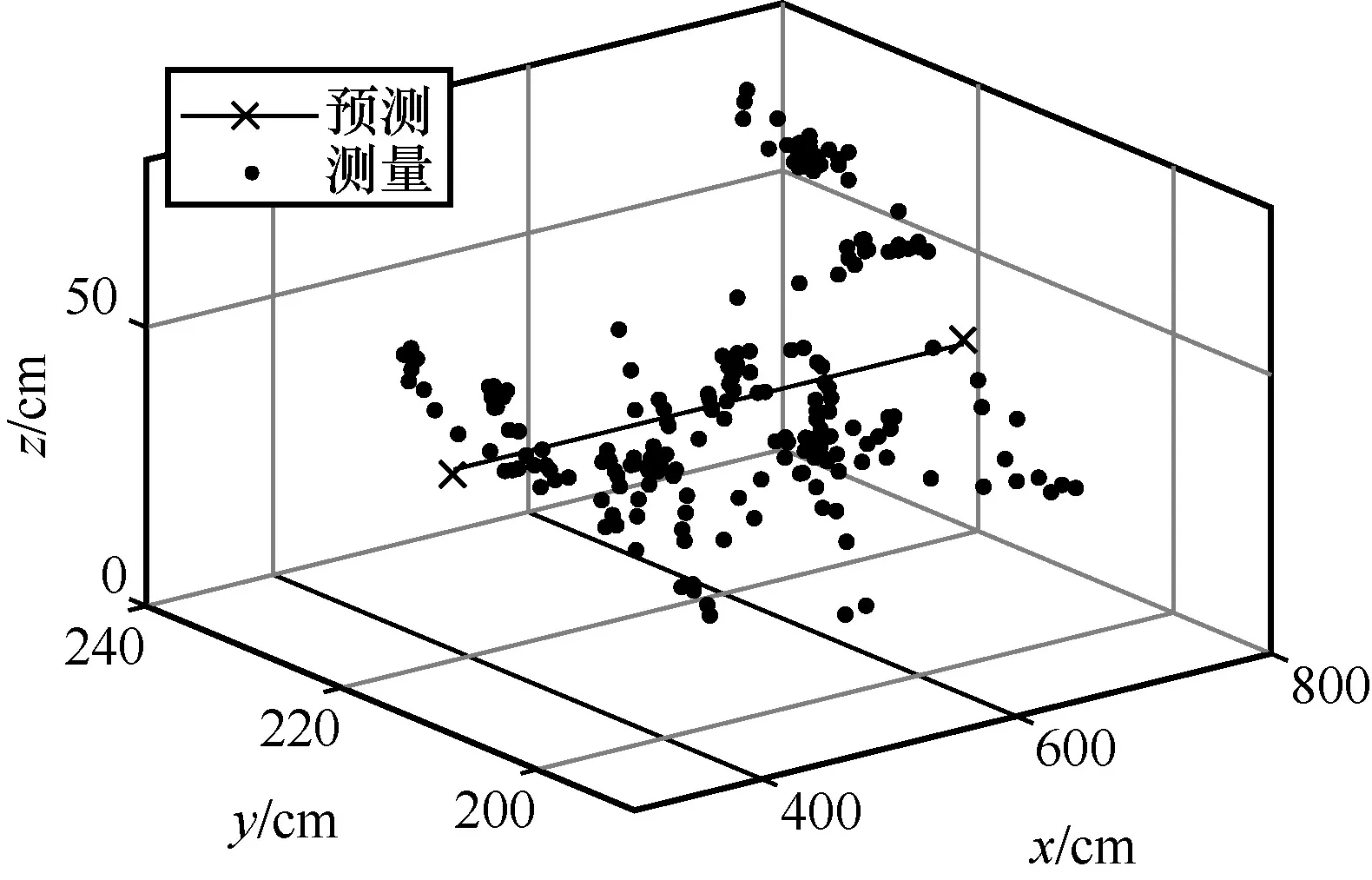
Нј12 КөјК¶ЁО»№мјЈ
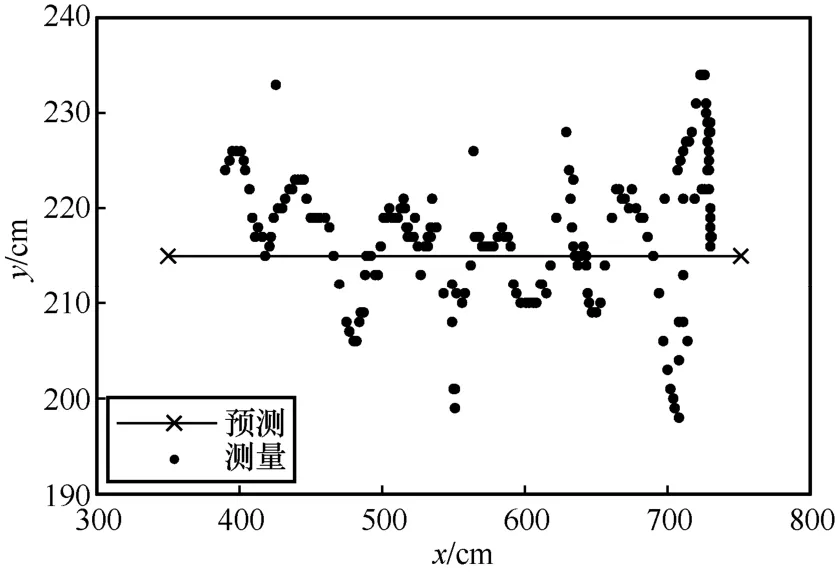
Нј13 x-y КөјК¶ЁО»№мјЈ
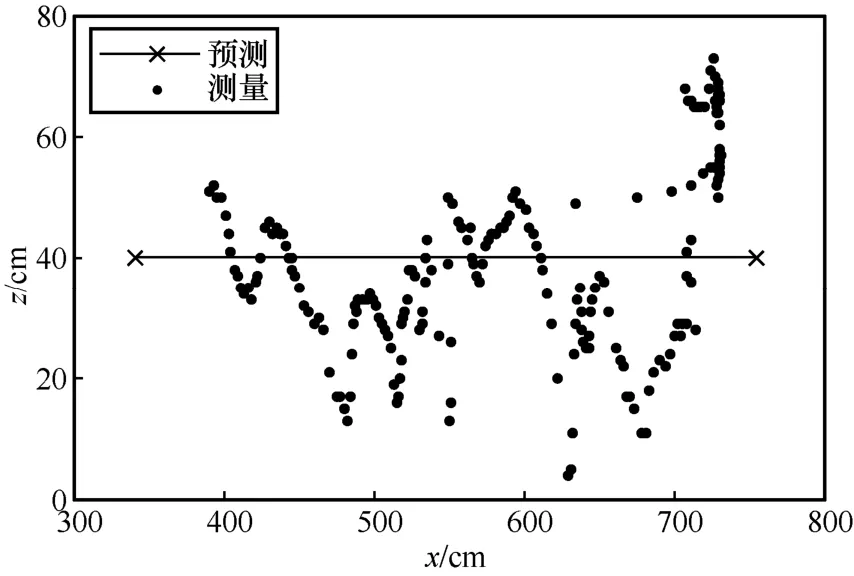
Нј14 x-z КөјК¶ЁО»№мјЈ
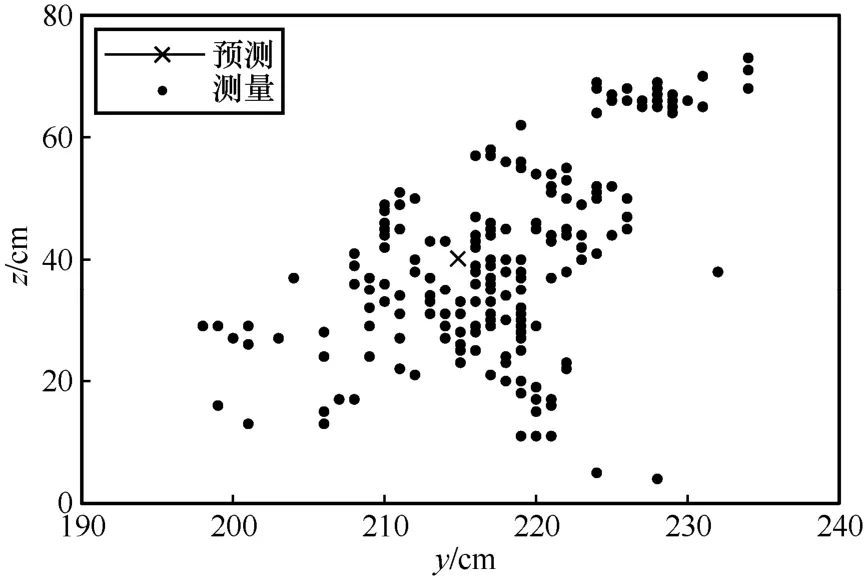
Нј15 z-y КөјК¶ЁО»№мјЈ
ёщҫЭУлАнПл№мјЈөД¶ФұИҝЙөГЈ¬ұҫОДКөСйЛщУГөДCHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·Ё»щұҫ·ыәПФӨІв№мјЈЈ¬ІўЗТФЪФӨІв№мјЈёҪҪьІЁ¶ҜЎЈУЙНј13Ў«Нј15 ҝЙЦӘЈ¬yЦбәНzЦбөД¶ЁО»ОуІоФЪ40 cm ЧуУТЈ¬xЦбөД¶ЁО»ОуІоФЪ20 cm ЧуУТЎЈ
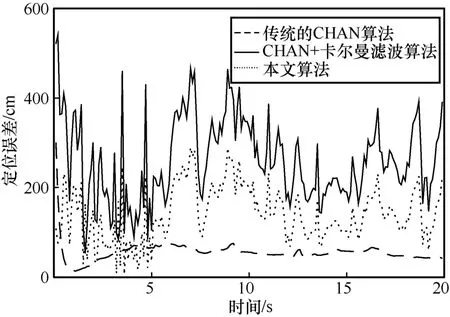
ОӘБЛёьҪшТ»ІҪөШЛөГчұҫОДЛг·ЁПаұИН¬АаЛг·ЁөДРФДЬУЕКЖЈ¬Нј16 ФЪёш¶ЁФӨІв№мјЈөДЗйҝцПВЈ¬АыУГКөјКПөНі¶ФұИұҫОДЛг·ЁЎўҙ«НіөДCHAN Лг·Ё[8]әНCHAN+ҝЁ¶ыВьВЛІЁЛг·Ё[16]өД¶ЁО»Ҫб№ыЎЈҙУНј16 ҝЙЦӘЈ¬ФЪіхКјКұҝМЈ¬УЙУЪұкЗ©Ул»щХҫЦ®јдУРРЕәЕЧФ¶ҜРЈЧјөДКұјдІоЈ¬ТтҙЛіхКј¶ЁО»КұҝМөДЖ«ІоҪПҙуЈ¬ө«КЗЛжЧЕКұјдөДНЖТЖЈ¬¶ЁО»Ҫб№ыЦрҪҘОИ¶ЁЎЈУЙКөјКөДКэҫЭҝЙөГЈ¬CHAN+ёДҪшҝЁ¶ыВьВЛІЁЛг·ЁөДЖҪҫщ¶ЁО»ОуІоЧоРЎЈ¬ФЪ50Ў«60 cmЈ¬ЗТЖд¶ЁО»өДОИ¶ЁРФұИЖдУа2 ЦЦЛг·Ё¶јёЯЎЈCHAN+ҝЁ¶ыВьВЛІЁЛг·ЁөДЖҪҫщ¶ЁО»ОуІоФЪ150 cm ЧуУТЈ¬¶шҙ«НіөДCHAN Лг·ЁөДЖҪҫщ¶ЁО»ОуІоФЪ250 cm ЧуУТЈ¬ІўІ»ККУГУЪКөјКёҙФУ»·ҫіөДКТДЪ¶ЁО»ЎЈЙПКцЛг·ЁФЪКөјККэҫЭЦРөД¶ФұИҪшТ»ІҪСйЦӨБЛұҫОДЛг·ЁөДРФДЬЎЈ
Нј16 КөјК¶ЁО»ОуІо
4 ҪбКшУп
ұҫОДМбіцБЛТ»ЦЦФЪёҙФУКТДЪ¶ЁО»»·ҫіПВ»щУЪCHAN өДёДҪшҝЁ¶ыВьВЛІЁЛг·ЁЎЈёГЛг·ЁМбёЯБЛ»щУЪCHAN өДҝЁ¶ыВьВЛІЁЛг·ЁФЪёҙФУКТДЪ»·ҫіПВөД¶ЁО»ҫ«¶ИЈ¬ІўЗТёДЙЖБЛҝЁ¶ыВьВЛІЁФцТжФЪіхКј¶ЁО»КұөДЧјИ·РФЎЈНЁ№эКөјКІвБҝСйЦӨЈ¬ұҫОДЛг·ЁҫЯУРҪПёЯөД¶ЁО»ҫ«¶ИЈ¬ФЪёҙФУКТДЪ»·ҫіПВҫ«¶ИҙпөҪБЛСЗГЧј¶Ј¬КЗТ»ЦЦУРР§өД¶ЁО»·Ҫ·ЁЎЈ