НфГчҙпЈ¬БхКАоЪЈ¬ДфҙуіЙЈ¬Со »ЫЈ¬ХЕ ПиЈ¬ЗсәиҪЬ
ЈЁЦР№ъөзЧУҝЖјјјҜНЕ№«ЛҫөЪИэК®СРҫҝЛщЈ¬ЛДҙЁ іЙ¶ј 610041Ј©
0 ТэСФ
ЛжЧЕИ«ЗтКэЧЦ»ҜЎўРЕПў»ҜҪшіМөДЙо¶ИНЖҪшЈ¬»ҘБӘНшЦрҪҘіЙОӘИЛАаЧоЦШТӘөД»щҙЎЙиК©Ц®Т»Ј¬іРФШБЛЙжј°ИЛАаЙъ»о№ӨЧч·Ҫ·ҪГжГжөДәЈБҝРЕПўЎЈУлҙЛН¬КұЈ¬»ҘБӘНшөДЖХј°ј«ҙујт»ҜБЛҙУГЕ»§НшХҫЎўЙзҪ»ГҪМеЎўІ©ҝНөИ№«ҝӘРЕПўФҙ»сИЎРЕПўКэҫЭөД№эіМЈ¬ХвР©ҝӘФҙРЕПўКэҫЭҝЙОӘИЛГЗМṩУРјЫЦөөДҫцІЯЦ§іЕРЕПўЈ¬°пЦъИЛГЗёьәГөШИПЦӘЎўАнҪвЙхЦБФӨІвМШ¶ЁКөМе»тёЕДо¶ФПуөДКфРФәНРРОӘЈ¬Ҫш¶шХЖОХКВјюөД№жДЈЎўИИ¶ИЎў·ўХ№ЗчКЖөИЎЈОӘҙЛЈ¬»ҘБӘНшҝӘФҙРЕПўҙҰАнЦрҪҘіЙОӘКАҪзёч№ъХщПаСРҫҝөДИИөгЎЈ
»ҘБӘНшҝӘФҙРЕПўҙҰАнЈЁТФПВјтіЖЎ°ҝӘФҙРЕПўҙҰАнЎұЈ©КЗЦёҙУ»ҘБӘНшЙПөД№«ҝӘРЕПўФҙ»сИЎКэҫЭІў·ЦОцҙҰАнЈ¬Ҫш¶ш»сөГУРјЫЦөөДҝӘФҙРЕПўөД№эіМЎЈҝӘФҙРЕПўҙҰАнЦРЙжј°өДРЕПў·¶О§К®·Ц№г·әЈ¬әӯёЗБЛХюЦОЎўҫьКВЎўЙМТөЎўЙз»бөИЦЪ¶аБмУтЎЈФЪХюЦОБмУтЈ¬ҝӘФҙРЕПўҙҰАнҝЙТФУГУЪ·ЦОцЖдЛы№ъјТөДХюІЯәНҫцІЯЈ¬°пЦъҫцІЯХЯФӨІвДҝұк№ъјТөДРРОӘЗчКЖЎЈФЪЙМТөБмУтЈ¬ҝӘФҙРЕПўҙҰАнҝЙТФУГУЪ·ЦОцҫәХщ¶ФКЦөДХҪВФәНКРіЎЗчКЖЈ¬°пЦъЖуТөЦЖ¶ЁёьәГөДКРіЎУӘПъІЯВФЎЈФЪЙз»бБмУтЈ¬ҝӘФҙРЕПўҙҰАнҝЙУГУЪ·ЦОц·ёЧп»о¶ҜәНЙз»бЗчКЖЈ¬°пЦъЦҙ·ЁІҝГЕәНХюё®»ъ№№ЦЖ¶ЁёьәГөДХюІЯәНҙлК©ЎЈ
ұҫОДҪ«¶Ф№ъНвҝӘФҙРЕПўҙҰАнөДУР№ШСРҫҝҪшРРЧЫКцЈ¬°ьАЁҝӘФҙРЕПўҙҰАнөД¶ЁТеЎўјјКхКЦ¶ОЎўУҰУГПөНіөИЈ¬ЧЬҪбПЦУРСРҫҝҙжФЪөДОКМвЈ¬МбіцОҙАҙҝЙДЬөДСРҫҝ·ҪПтЈ¬ЦјФЪОӘУР№ШБмУтөДҙУТөИЛФұМṩһёцҝЙІОҝјөДПөНіРФЦӘК¶ҝтјЬЈ¬ЦъБҰҝӘФҙРЕПўҙҰАнјјКх·ўХ№ЎЈ
1 јјКхБчіМ
ҝӘФҙРЕПўҙҰАнөДЦчТӘјјКхБчіМ°ьАЁ4 ёцІҝ·ЦЈ¬·ЦұрКЗКэҫЭІЙјҜЎўКэҫЭФӨҙҰАнЎўРЕПў·ЦОцәНҫцІЯЦ§іЕЈ¬ИзНј1 ЛщКҫЎЈ
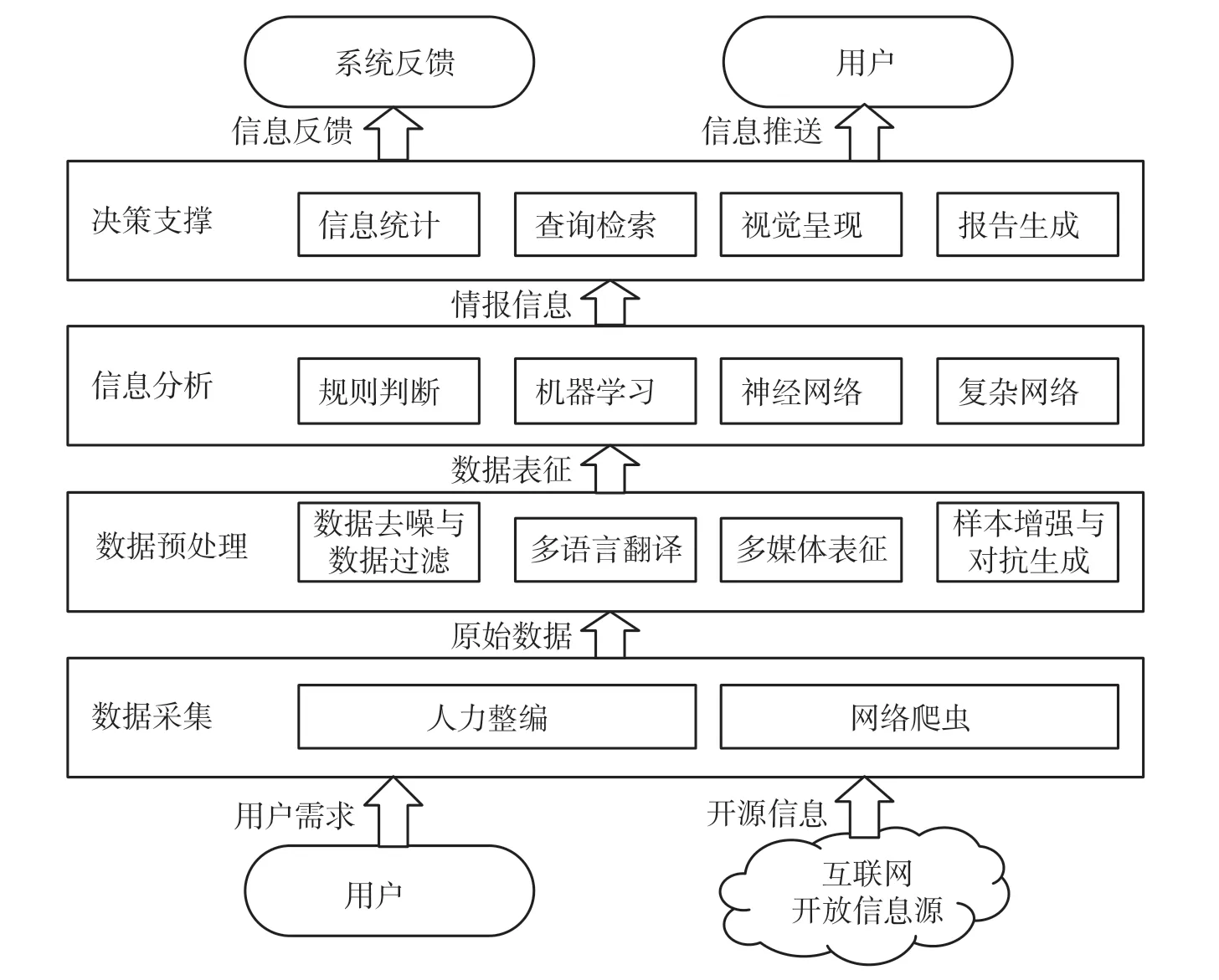
Нј1 ҝӘФҙРЕПўҙҰАнЦчТӘјјКхБчіМ
Т»КЗКэҫЭІЙјҜЈ¬КЗЦёҙУ»ҘБӘНш№«ҝӘКэҫЭФҙІЙјҜРЕПўКэҫЭЈ¬ОӘҝӘФҙРЕПўҙҰАн·ЦОцМṩ»щҙЎКэҫЭЦ§іЕЎЈІЙјҜөДРЕПўРиТӘҫӯ№эіхІҪЙёСЎәН№эВЛЈ¬ТФұЈЦӨ»щұҫөДКэҫЭЧјИ·РФәНУРР§РФЈ¬ұЬГвІЙјҜЧКФҙАЛ·СЎЈКэҫЭФӨҙҰАнКЗЦё¶ФІЙјҜөҪөДҝӘФҙКэҫЭҪшРР·ЦОцЗ°өДФӨПИҙҰАнЎЈ¶юКЗКэҫЭФӨҙҰАнЈ¬ЖдДҝөДКЗФЪУЪМбёЯКэҫЭөДЦКБҝәНҝЙУГРФЈ¬ТФұгәуРш·ЦОцДЬ№»ёьјУУРР§өШАыУГЈ¬іЈјыөДФӨҙҰАн°ьАЁКэҫЭЗеПҙЎўёсКҪЧӘ»»ЎўКэҫЭЦШ№№әНҙжҙў№ЬАнөИЈ¬ДЬ№»К№КэҫЭёьјУ№ж·¶»ҜЈ¬ҪөөНКэҫЭИЯУаәНҙнОуЎЈИэКЗРЕПў·ЦОцЈ¬ЦёАыУГ·ЦОцЛг·Ё¶ФФӨҙҰАнКэҫЭҪшРРЙо¶ИөДНіјЖЎў·ЦОцәНЕР¶ПЈ¬ҙУЦРНЪҫтіцУРјЫЦөөДРЕПўәН№жВЙЈ¬ЙъіЙУРјЫЦөөДҫцІЯЦ§іЕРЕПўЈ¬ОӘУГ»§ҫцІЯ№ЬАнМṩРЕПўЦ§іЕЈ¬КЗҝӘФҙРЕПўҙҰАнХыМеБчіМЦРөДәЛРД»·ҪЪЎЈЛДКЗҫцІЯЦ§іЕЈ¬ЦёҪ«·ЦОцөДҪб№ыНЁ№эәПАнөД·ҪКҪҙ«өЭёшУГ»§Ј¬·ҪКҪЦчТӘ°ьАЁРЕПўҝЙКУ»ҜЎўұЁёжЙъіЙәНРЕПў№ІПнЈ¬ТФұгУГ»§ёьәГөШАнҪвәНК№УГҫцІЯЦ§іЕРЕПўЎЈ
2 КэҫЭІЙјҜ
2.1 ИЛБҰХыұа
ИЛБҰХыұаТІіЖЦЪ°ьКэҫЭКХјҜЈ¬КЗЦёНЁ№эКэҫЭ№ӨЧчХЯКЦ№ӨКХјҜЎўНкЙЖәНУЕ»ҜҙУ№«ҝӘКэҫЭФҙ»сөГөДКэҫЭөД№эіМЎЈИЛБҰХыұаөДУЕКЖЦчТӘФЪУЪНЁ№эТэИлЧЁјТЦӘК¶Ј¬Т»¶ЁіМ¶ИЙПМбёЯКэҫЭЦКБҝЈ¬¶ФУЪЗбБҝј¶өДКэҫЭІЙјҜ№ӨЧчДЬ№»ұЈЦӨКэҫЭІЙјҜәН№ЬАнөДР§ВКЎЈИ»¶шЈ¬ИЛБҰХыұаГжБЩКэҫЭТюЛҪ°ІИ«ЎўИЛОӘЖ«јыЎўЦЪ°ьЦКБҝІОІоІ»ЖлөИОКМвЎЈ
Chai өИИЛ[1]ФЪЖдЧЫКцСРҫҝЦРМбөҪЈ¬ЦЪ°ьКэҫЭҝвПөНіДЬ№»УРР§ҪвҫцПЦУР№«№ІЦЪ°ьЖҪМЁЈЁИзAmazon Mechanical TurkЎўCrowdFlower өИЈ©Ҫ»»ҘЙијЖ·ЗіЈІ»ұгөДОКМвЎЈёГЧЫКц¶ФЦЪ°ьЖҪМЁУР№ШСРҫҝҪшРРБЛКбАнЈ¬ёЕКцБЛЦЪ°ьөДёЕДоЈ¬ЧЬҪбБЛЙијЖЦЪ°ьКэҫЭҝвөД»щұҫјјКхЈ¬ЖдЦР°ьә¬ИООсЙијЖЎўИООс·ЦЕдЎўҪвҫц·Ҫ°ёНЖАнј°СУіЩјхЙЩөИЈ¬Іў»Ш№ЛБЛЦЪ°ьІЩЧч·ыЙијЖІЯВФЈ¬°ьАЁСЎФсЎўБ¬ҪУЎўЕЕРтЎўЗ°kПоЎўЧоҙу/ЧоРЎЦөЎўјЖКэЎўКХјҜәНМоідөИЎЈ
2.2 НшВзЕАіж
НшВзЕАіжКЗТ»ЦЦУГУЪЧФ¶Ҝ»ҜІЙјҜ№«ҝӘКэҫЭөДіМРтЈ¬КэҫЭАаРНёІёЗ°ьАЁНшТіОДұҫЎўНјЖ¬ЎўТфЖөЎўКУЖөөИФЪДЪөД¶аГҪМеКэҫЭЎЈҫӯ№э¶аДк·ўХ№Ј¬НшВзЕАіжЦрҪҘіЙОӘҙуКэҫЭ·ЦОцЎўЛСЛчТэЗжЎўНЖјцПөНіөИјјКхөДКэҫЭІЙјҜ»щҙЎЎЈ
Khder өИИЛ[2]ФЪЖд2021 Дк·ўұнөДСРҫҝЧЫКцЦРМбөҪЈ¬НшВзЕАіжөДҪьЖЪСРҫҝЦчТӘ№ШЧўУЪЕАіжјјКхөДЦЗДЬ»Ҝј°ЕАИЎР§ВКөДМбёЯЎЈПаҪПУЪИЛ№ӨХыұаЈ¬К№УГНшВзЕАіжІ»ҪцҝЙТФ»сөГёьИ«ГжЎўЧјИ·әНТ»ЦВөДКэҫЭЈ¬»№ҝЙҙУЙо°өНшЦРҙуБҝ»сИЎ»ТәЪІъКэҫЭТФЦ§іЕЦҙ·Ёҙт»чҫцІЯЈ¬УҰУГіЎҫ°ёьОӘ№г·әЎЈН¬КұЈ¬ёГОДЗҝөчБЛЕАіжУҰУГөјЦВөДВЧАнәН·ЁВЙОКМвЈ¬УИЖдКЗёцИЛТюЛҪР№В¶Ўў°жИЁЗЦ·ёЎўІ»ХэөұҫәХщЎўНшВз№Ҙ»чөИЎЈ
Neelakandan өИИЛ[3]МбіцБЛТ»ЦЦУГУЪ¶ЁПтНшВзЕАіжөДЧФ¶ҜІОКэөчХыЙо¶ИС§П°ҙКЗ¶ИлДЈРНЎЈёГДЈРНЙжј°¶аёцІҪЦиЈ¬°ьАЁФӨҙҰАнЎў»щУЪёәІЙСщөДФцБҝКҪМшФҫУп·ЁДЈРНҙКЗ¶ИлЎўЛ«ПтіӨ¶МЖЪјЗТд·ЦАаТФј°»щУЪДсИәУЕ»ҜөДі¬ІОКэөчХыЎЈёГСРҫҝөДКөСйҪб№ыұнГчЈ¬ЛщМбіцөДДЈРНФЪНшТіКХјҜ·ҪГж»сөГБЛёьёЯөДІЙјҜіЙ№ҰВКЈ¬ҙпөҪБЛ85%ЎЈ
3 КэҫЭФӨҙҰАн
ФЪҝӘФҙРЕПўҙҰАнЦРЈ¬КэҫЭФӨҙҰАн°ьАЁәЬ¶а·ҪГжөДДЪИЭЈ¬АэИзКэҫЭөДДҝұкійИЎЎўЗеПҙЎўёсКҪЧӘ»»ЎўИЎЦөұкЧј»ҜЎў¶аФҙКэҫЭјҜіЙЎўРЕПўҫ«Б¶өИЎЈ
Johnsen өИИЛ[4]МбіцБЛТ»ЦЦ»щУЪЦчМвДЈРНөДТюКҪөТАыҝЛАЧ·ЦІјЈЁLatent Dirichlet AllocationЈ¬LDAЈ©өДОДұҫФӨҙҰАн·Ҫ·ЁЎЈёГСРҫҝ»щУЪ¶ФҙуБҝУР№ШСРҫҝОДПЧөДЧЬҪбЈ¬ЙијЖБЛТ»ЧйФӨҙҰАн№жФтЈ¬ІўФЪХжКөөДНшВзВЫМіЦРҪшРРБЛСЭКҫУҰУГЎЈёГСРҫҝөДКөСйҪб№ыұнГчЈ¬Из№ыТӘұЈЦӨЦчМвҪЁДЈөДҪб№ыҝЙТФКөјКФЛУГУЪҝӘФҙРЕПўҙҰАнЈ¬ЖдҪЁДЈ№эіМРиТӘЧсСӯ·ЗіЈСПёсөДБчіМЈ¬ЗТНЁ№эөчХыLDA өДі¬ІОКэәНЦчМвКэҝЙТФІъЙъёьҝЙҝҝөДҪб№ыЎЈёГСРҫҝНЁ№э¶ФЦчМвДЈРНҪшРРөьҙъёДЙЖЈ¬ұЈЦӨБЛЛщМбИЎЦчМвДЪИЭөДБ¬№бРФәНХл¶ФРФЎЈ
Chandrasekar өИИЛ[5]ОӘМбёЯC4.5 ҫцІЯКчЛг·ЁРЕПўНЪҫтөДЧјИ·РФЈ¬МбіцНЁ№эФЪКэҫЭФӨҙҰАнЦРАыУГја¶Ҫ№эВЛАлЙў»ҜІЩЧчАҙ№№ҪЁҫцІЯКчЈ¬ІўҪ«Ҫб№ыУлОҙҫӯАлЙў»ҜөДC4.5 ҫцІЯКчҪшРРБЛұИҪПЎЈКөСйҪб№ыұнГчЈ¬ҫӯАлЙў»ҜФӨҙҰАнәуөДC4.5 ҫцІЯКчДЬ№»ИЎөГёьёЯөДЧјИ·¶ИЎЈGarcia өИИЛ[6]¶ФҙуКэҫЭ·ЦОціЎҫ°ПВөДКэҫЭФӨҙҰАн·Ҫ·ЁҪшРРБЛЧЫКцЈ¬ГиКцБЛҙуКэҫЭЦРКэҫЭФӨҙҰАн·Ҫ·ЁөД¶ЁТеЎўМШХчәН·ЦАа·ҪКҪЈ¬МҪМЦБЛҙуКэҫЭәНКэҫЭФӨҙҰАнФЪёчЦЦ·Ҫ·ЁәНҙуКэҫЭјјКхЧеИәЦРөДЧчУГЎЈёГЧЫКцЧЬҪбБЛПЦУРСРҫҝГжБЩөДМфХҪЈ¬ЦШөгГиКцБЛІ»Н¬ҙуКэҫЭҝтјЬЈЁИзHadoopЎўSpark әНFlinkЈ©өД·ўХ№ЧҙҝцЈ¬ТФј°Т»Р©КэҫЭФӨҙҰАн·Ҫ·ЁәНРВҙуКэҫЭНЪҫтДЈКҪөДУҰУГЎЈ
4.1 »щУЪ№жФтЕР¶ПөДҝӘФҙРЕПўҙҰАн
»щУЪ№жФтЕР¶ПөДҝӘФҙРЕПўҙҰАнКЗЦёҙУЧЁјТөДПИСйЦӘК¶іц·ўЈ¬КЦ№ӨЙијЖҝӘФҙРЕПўҙҰАн·ЦОцЛщРиөДЕР¶Ё№жФтЈ¬ИзгРЦөЕР¶Ё№жФтЎўАаРНЕР¶Ё№жФтЎў№жФтЖҘЕд·ҪКҪөИЈ¬ІўАыУГХвР©№жФт¶ФҝӘФҙРЕПўКэҫЭҪшРР·ЦОцҙҰАнЈ¬Ҫш¶шҙпөҪРЕПў·ЦОцДҝөДөД·Ҫ·ЁЎЈ
№жФтЕР¶ПФЪҝӘФҙРЕПўҙҰАнЦРөДУҰУГУЕКЖЦчТӘУРБҪөгЎЈТ»КЗУЙУЪ№жФтЕР¶ПДЬ№»ёщҫЭБмУтЧЁјТөДҫӯСйҪшРРҝмЛЩЙијЖЈ¬ТтҙЛПаҪПУЪЖдЛы»щУЪёҙФУЛг·ЁөДҝӘФҙРЕПўҙҰАнЈ¬»щУЪ№жФтЕР¶ПөДҝӘФҙРЕПўҙҰАнДЬ№»ҝмЛЩЎўёЯР§өШВъЧгЗбБҝКэҫЭөД·ЦАаәНЙёСЎРиЗуЎЈ¶юКЗКЦ№Ө№жФтҝЙТФід·ЦАыУГЧЁјТөДЦч№ЫҫӯСйЕР¶ПБҰЈ¬ДЬ№»ФЪДіР©КэҫЭ·ЦОцБмУтЦРЧјИ·ГиКц·ЦОцРиЗ󣬶ЁО»№ШјьОКМвЈ¬АэИз¶ФУЪҫЯМеЧФИ»УпСФөДҪвКНәННЖ¶ПөИЎЈө«УлҙЛН¬КұЈ¬КЦ№Ө№жФт¶ФЧЁјТөДЧЁТөЦӘК¶өДёЯТӘЗуөјЦВ№жФтО¬»ӨЛщРиөДИЛ№ӨҝӘПъҙуЈ¬ИЭТЧұ»ЧЁјТЦӘК¶өДЖ«ПтРФУ°ПмЈ¬ЗТауУЪКэҫЭөДёҙФУРФ¶шДСТФҙҰАнҙуБҝКэҫЭЎЈ
Tariq Soomro өИИЛ[7]·ЦОцБЛКХјҜЧФ2020 Дк3ФВ1 ИХЦБ2020 Дк5 ФВ31 ИХөДі¬№э1 800 НтМхУл№ЪЧҙІЎ¶ҫУР№ШөДTwitter ПыПўЈ¬ІўАыУГ»щУЪ№жФтөДја¶Ҫ»ъЖчС§П°№ӨҫЯVader АҙҪшРРЗйёР·ЦОцЈ¬ТФЖА№А№«ЦЪЗйРчУлРВРН№ЪЧҙІЎ¶ҫ·ОСЧЈЁCorona Virus Disease 2019Ј¬COVID-19Ј©ІЎАэКэЦ®јдөД№ШПөЎЈҙЛНвЈ¬ёГСРҫҝ»№·ЦОцБЛФЪНЖОДЦРМбөҪТ»ёц№ъјТөДКэБҝУлёГ№ъCOVID-19 ГҝИХІЎАэКэөДФцјУЦ®јдөД№ШПөЎЈёГСРҫҝ·ўПЦЈ¬Т»Р©Ҫб№ыұнГчФЪТвҙуАыЎўГА№ъәНУў№ъМбөҪөДНЖОДКэБҝУлХвР©№ъјТГҝИХРВCOVID-19 ІЎАэКэөДФцјУЦ®јдҙжФЪПа№ШРФЎЈ
4.2 »щУЪ»ъЖчС§П°өДҝӘФҙРЕПўҙҰАн
ФЪҝӘФҙРЕПўҙҰАнЦР№г·әУҰУГөДҙ«Ні»ъЖчС§П°Лг·ЁЦчТӘ°ьАЁҫцІЯКчАаЛг·ЁЎўЖУЛШұҙТ¶Л№ЎўЧоҪьБЪҫУЛг·ЁЎўЦ§іЦПтБҝ»ъЎўВЯјӯ»Ш№йөИЎЈҝӘФҙРЕПўҙҰАнЦРУҰУГ»ъЖчС§П°өДУЕКЖЦчТӘФЪУЪДЬ№»УРР§ЖҪәвЧЁјТҫӯСйЦӘК¶әНЛг·ЁЧФ¶Ҝ»ҜөДУ°ПмЈ¬ДЬ№»ҙҰАнҪб№№»ҜәН·ЗҪб№№»ҜөИ¶аЦЦКэҫЭАаРНЈ¬ҫЯУРҪПёЯөДИЭҙнРФЎўҝЙА©Х№РФЎЈИ»¶шЈ¬ҙ«Ні»ъЖчС§П°ИФИ»ҙжФЪ¶ФКэҫЭФӨҙҰАнТӘЗуёЯЎў№э¶ИТААөКЦ№ӨМШХчөИОКМвЈ¬МШХчМбИЎЦРЧЁјТЦӘК¶өДЧЁТөРФәНЖ«ПтРФҪ«¶ФЛг·ЁКдіцІъЙъҪПҙуУ°ПмЎЈ
Balaji өИИЛ[8]¶ФК№УГ»ъЖчС§П°ҪшРРҝӘФҙРЕПўҙҰАн·ЦОцЈ¬УИЖдКЗЙзҪ»ГҪМе·ЦОц·ҪГжөДСРҫҝҪшРРБЛЧЫКцЎЈёГЧЫКцИПОӘЈ¬»ъЖчС§П°ТСҫӯіЙОӘЙзҪ»ГҪМе·ЦОцөД»щҙЎјјКхКЦ¶ОЈ¬ФЪЙзҪ»ГҪМеөДЗйёР·ЦОцЎўУГ»§»ӯПсЎўЙзҪ»НшВз·ЦОцЎўКВјюјмІвәННЖјцПөНіөИ·ҪГж·ў»УЧЕЦШТӘЧчУГЈ¬јјКхАаРН°ьАЁја¶ҪС§П°ЎўОЮја¶ҪС§П°Ўў°лја¶ҪС§П°өИЎЈПЦУРСРҫҝГжБЩөДМфХҪЦчТӘФЪУЪКэҫЭ»сИЎЎўКэҫЭЦКБҝЎўЛг·ЁР§ВКЎўДЈРНҪвКНРФөИ·ҪГжЈ¬ҝЙТФФЪЛг·ЁөДР§ВКәНЧјИ·РФЈ¬ИзМШХчСЎФсЎўЙо¶ИС§П°ЎўЧФККУҰЛг·ЁөИҪЗ¶ИҝӘХ№ҪшТ»ІҪСРҫҝЎЈ
Khadjeh Nassirtoussi өИИЛ[9]¶ФОДұҫНЪҫтФЪҝӘФҙ№ЙКРФӨІв·ҪГжөДУҰУГСРҫҝҪшРРБЛЧЫКцЎЈОДұҫНЪҫтФЪ№ЙКРФӨІв·ҪГжөДУҰУГТСҫӯөГөҪБЛ№г·әөДСРҫҝЈ¬КэҫЭФҙЦчТӘ°ьАЁРВОЕЎўЙзҪ»ГҪМеЎў№«ЛҫұЁёжЎў№ЙКРЖАВЫөИ·ҪГжөДКэҫЭЎЈФЪ·Ҫ·ЁәНДЈРН·ҪГжЈ¬СРҫҝХЯГЗЦчТӘІЙУГБЛ»ъЖчС§П°ЎўЧФИ»УпСФҙҰАнЎўЗйёР·ЦОцөИјјКхАҙҪшРРОДұҫНЪҫтәНФӨІвЎЈёГВЫОДЦёіцЈ¬ОДұҫНЪҫтФЪ№ЙКРФӨІв·ҪГжөДУҰУГҝЙТФМбёЯФӨІвөДЧјИ·РФәНР§ВКЈ¬ө«КэҫЭАҙФҙІ»И·¶ЁЎўДЈРН№э¶ИДвәПөИОКМвҙшАҙөДФӨІвР§№ыПВҪөөДЗйҝцІ»ИЭәцКУЎЈТтҙЛЈ¬ФЪҪшРРОДұҫНЪҫтөДКұәтРиТӘЧўТвКэҫЭөДЦКБҝІўСЎФсәПККөДДЈРНәН·Ҫ·ЁЈ¬ТФМбёЯФӨІвөДЧјИ·РФәНҝЙҝҝРФЎЈ
Abbass өИИЛ[10]МбіцБЛТ»ёц»щУЪҝӘФҙКэҫЭҪшРРЙзҪ»ГҪМе·ёЧпРРОӘФӨІвөДјјКхҝтјЬЈ¬Йжј°өДНшВз·ёЧпАаРН°ьАЁНшВзёъЧЩЎўНшВзЖЫБиЎўНшВзәЪҝНЎўНшВзЙ§ИЕәННшВзХ©ЖӯЎЈёГҝтјЬУЙИэёцДЈҝйЧйіЙЈ¬°ьАЁКэҫЭЈЁНЖОДЈ©ФӨҙҰАнЎў·ЦАаДЈРН№№ҪЁәНФӨІвЎЈОӘ№№ҪЁФӨІвДЈРНЈ¬ёГСРҫҝК№УГБЛ¶аПоКҪЖУЛШұҙТ¶Л№ЈЁMultinomial Naïve BayesЈ¬MNBЈ©ЎўK Ҫь БЪЈЁK Nearest NeighborsЈ¬KNNЈ©әНЦ§іЦПтБҝ»ъЈЁSupport Vector MachineЈ¬SVMЈ©¶ФКэҫЭҪшРР·ЦАаЈ¬ТФИ·¶ЁІ»Н¬өД·ёЧпАаұрЎЈК№УГХвР©»ъЖчС§П°Лг·ЁөДN-GramУпСФДЈРНАҙК¶ұрnөДЧојСЦөЈ¬ІўІвБҝПөНіФЪІ»Н¬nИЎЦөЈЁАэИзUnigramЎўBigramЎўTrigram әН4-gramЈ©ПВөДЧјИ·РФЎЈКөСйҪб№ыұнГчЈ¬ЛщУРИэёцЛг·ЁөДҫ«И·¶ИЎўХЩ»ШВКәНF Цөҫщі¬№э0.9Ј¬ЖдЦРЦ§іЦПтБҝ»ъұнПЦВФУЕЎЈ
Ghazi өИИЛ[11]МбіцІЙУГУРја¶ҪөД»ъЖчС§П°ҙУІ»№жХыЎўёЯФлЙщЎўәЈБҝөДҝӘФҙ·ЗҪб№№»ҜНюРІРЕПўКэҫЭЦРМбИЎНюРІКэҫЭФҙЈ¬МбИЎҫ«¶ИФјОӘ70%Ј¬ЗТёГ·Ҫ·ЁДЬЙъіЙ·ыәПSTIX өИұкЧјөДИ«ГжөДНюРІұЁёжЈ¬Ҫш¶ш°пЦъЧйЦҜЦч¶Ҝ·АУщТСЦӘәНОҙЦӘөДНюРІЈ¬јхЙЩКЦ¶Ҝ·ЦОцөД·іЛц№ӨЧчЎЈ
4.3 »щУЪЙсҫӯНшВзөДҝӘФҙРЕПўҙҰАн
ЙсҫӯНшВзПөБРЛг·ЁТСҫӯ№г·әУҰУГУЪҝӘФҙРЕПўҙҰАн·ЦОцБмУтЈ¬ЦчТӘ°ьАЁЗ°ПтИ«Б¬ҪУНшВзЎўҫн»эЙсҫӯНшВзЈЁConvolutional Neural NetworkЈ¬CNNЈ©ЎўСӯ»·ЙсҫӯНшВзЎўНјҫн»эЙсҫӯНшВзЎўЧФұаВлЖчЎўЙъіЙ¶Фҝ№НшВзЎўІРІоНшВзөИЈ¬ТФј°Йо¶ИС§П°ЎўЧўТвБҰ»ъЦЖЎўФӨСөБ·ДЈРНЎўФцЗҝС§П°ЎўЗЁТЖС§П°ЎўЙЩСщұҫС§П°өИРВРНС§П°ҝтјЬөДУҰУГЎЈЙсҫӯНшВз·ЦОц·Ҫ·ЁөДУЕКЖФЪУЪДЬ№»ЧФККУҰәНЧФОТС§П°Ј¬ҝЙТФҪшРР¶ЛөҪ¶ЛөДС§П°әНІЩЧчЈ¬¶Ф·ЗПЯРФәНёҙФУКэҫЭҫЯУРБјәГөДДвәПДЬБҰЈ¬ККәПҪшРРФӨІвәН·ЦАаИООсЎЈИ»¶шЈ¬ЙсҫӯНшВзөДДЈРНСөБ·РиТӘҙуБҝөДКэҫЭәНјЖЛгЧКФҙЈ¬ДЈРНөДҝЙҪвКНРФУРҙэМбёЯЈ¬ДСТФЖА№АНшВзөДВі°фРФЈ¬ДЈРНИЭТЧіцПЦ№эДвәПЗйҝцЎЈ
Martins өИИЛ[12]МбіцБЛТ»ЦЦ»щУЪЙсҫӯНшВзөДБӘәПС§П°ҝтјЬЈ¬Ҫ«ГьГыКөМеК¶ұрЈЁNamed Entity RecognitionЈ¬NERЈ©әНКөМеБҙҪУЈЁEntity LinkingЈ¬ELЈ©БҪёцИООсҪбәПФЪТ»ЖрҪшРРС§П°Ј¬КөПЦРӯН¬УЕ»ҜЎЈёГ·Ҫ·ЁЦчТӘ°ьАЁИэёцЧйјюЎЈТ»КЗ№ІПнұаВлЖчЈ¬УГУЪҪ«КдИлөДОДұҫЧӘ»ҜОӘПтБҝұнКҫЎЈ¶юКЗNER ҪвВлЖчЈ¬УГУЪФӨІвОДұҫЦРөДГьГыКөМеЎЈИэКЗEL ҪвВлЖчЈ¬УГУЪҪ«ФӨІвіцөДГьГыКөМеБҙҪУөҪЦӘК¶ҝвЦРөДКөМеЎЈёГҝтјЬөДЦчТӘМШөгКЗҝЙТФН¬КұҝјВЗОДұҫЦРөДГьГыКөМеәНЦӘК¶ҝвЦРөДКөМеЈ¬ҙУ¶шДЬ№»МбёЯNER әНEL БҪёцИООсөДЧјИ·ВКЎЈҙЛНвЈ¬ёГҝтјЬ»№ҝЙТФНЁ№эБӘәПСөБ·АҙјхЙЩДЈРНөДСөБ·КұјдәНЧКФҙПыәДЈ¬МбёЯДЈРНөДР§ВКЎЈТФCoNLL 2003 әНAIDA CoNLL-YAGO ОӘКэҫЭКдИлөДКөСйҪб№ыұнГчЈ¬УлөҘ¶АСөБ·NER әНEL ДЈРНПаұИЈ¬ёГБӘәПС§П°ҝтјЬҝЙТФПФЦшМбёЯNER әНEL БҪёцИООсөДЧјИ·ВКЈ¬ІўЗТҝЙТФФЪұЈіЦЧјИ·ВКөДН¬КұјхЙЩДЈРНөДСөБ·КұјдәНЧКФҙПыәДЎЈ
Su өИИЛ[13]¶Ф»щУЪЙо¶ИС§П°өДЙзНЕ·ўПЦСРҫҝҪшРРБЛЧЫКцЎЈёГЧЫКцИПОӘҙУЛг·ЁөДҪЗ¶ИАҙЛөЈ¬ПЦУРСРҫҝЦчТӘ·ЦОӘБҪАаЈ¬јҙ»щУЪҪЪөгұнХчС§П°өД·Ҫ·ЁәН»щУЪНјұнХчС§П°өД·Ҫ·ЁЎЈЗ°ХЯЦчТӘНЁ№эС§П°ҪЪөгөДПтБҝұнХчАҙЕР¶ПҪЪөгЦ®јдөДПаЛЖРФЈ¬әуХЯФтКЗНЁ№эС§П°НјөДЗ¶ИлұнХчАҙІ¶ЧҪЙзЗшҪб№№әНҪЪөгјдөД№ШПөЎЈЖдЦРЈ¬»щУЪНјұнХчС§П°өД·Ҫ·ЁПа¶ФУЪ»щУЪҪЪөгұнХчС§П°өД·Ҫ·ЁёьҫЯУЕКЖЈ¬ТтОӘЛьДЬ№»ёьәГөШІ¶ЧҪҪЪөгЦ®јдөДҪб№№әН№ШПөЈ¬ҙУ¶шёьҫ«И·өШҝМ»ӯЙзЗшҪб№№ЎЈПЦУРСРҫҝөДМфХҪЦчТӘФЪУЪИзәОАыУГЙо¶ИС§П°·Ҫ·ЁёьәГөШ·ўПЦЙзЗшҪб№№Ј¬ИзәОУҰ¶ФФлЙщЎўПЎКиРФәНТмЦКРФөИОКМвЈ¬ТФј°ИзәОҙҰАнҙу№жДЈНшВзКэҫЭөДОКМвЎЈ
Garcia өИИЛ[14]Хл¶ФCOVID-19 ІЎАэКэәНЛАНцКэҫщҪПёЯөД°НОчәНГА№ъБҪёц№ъјТҝӘХ№БЛ»щУЪҝӘФҙКэҫЭөДЦчМвК¶ұрәНЗйёР·ЦОцСРҫҝЎЈёГСРҫҝК№УГБЛ№ІјЖБщ°ЩНтМхУўУпНЖОДәНЖПМССАУпНЖОДЈ¬ұИҪПәНМЦВЫБҪЦЦУпСФөДЦчМвК¶ұрәНЗйёР·ЦОцөДР§№ыЈ¬Іў»щУЪМЦВЫИИ¶ИЕЕГыөД10 ёцЦчМвҪшРРБЛ»°МвСЭ»Ҝ·ЦОцЎЈёГСРҫҝМоІ№БЛЖПМССАУпҝӘФҙ·ЦОц·ҪГжөДСРҫҝҝХ°ЧЈ¬Іў¶ФЗйёРЗчКЖөДіӨЖЪ·ЦОцј°ЖдУлРВОЕұЁөАөД№ШПөҪшРРБЛМҪҫҝЈ¬ұИҪПБЛТЯЗйПВБҪёцІ»Н¬өШЗшөДИЛАаРРОӘЎЈ
Hashida өИИЛ[15]МбіцБЛТ»ЦЦ»щУЪЙо¶ИС§П°өД·ЦАа·Ҫ·ЁЈ¬ІЙУГТ»ЦЦРВөД·ЦІјКҪөҘҙКұнКҫ·Ҫ·ЁЎӘЎӘ¶аНЁөА·ЦІјКҪұнКҫ·ЁЈ¬ұнКҫТ»ёцөҘҙКЗұФЪМШХчөДөҘҙКПтБҝЎЈФЪҙЛ»щҙЎЙПЈ¬ОӘБЛҪшТ»ІҪФцЗҝ·ЦІјКҪұнКҫөДДЬБҰЈ¬ёГСРҫҝФЪ¶аНЁөА·ЦІјКҪұнКҫЦРК№ГҝёцПо¶ј°ьә¬¶аёцНЁөАЦөЎЈУлЖдЛыCNN ДЈРНәНіӨ¶МЖЪјЗТдДЈРНЈЁLong Short-Time MemoryЈ¬LSTMЈ©ҪшРРөД¶ФұИКөСйҪб№ыұнГчЈ¬Йо¶ИС§П°ДЈРНөД·ЦАаРФДЬУЕУЪЖУЛШұҙТ¶Л№·ЦАаЖчЈ¬Н¬КұҫЯУР¶аНЁөА·ЦІјКҪұнКҫөДCNNФЪ·ЦАаНЖОД·ҪГжұнПЦёьәГЎЈ
4.4 »щУЪёҙФУНшВзөДҝӘФҙРЕПўҙҰАн
ҝӘФҙРЕПўҙҰАнЦРІЙУГөДёҙФУНшВз·ЦОцЦчТӘГжПтНјҪб№№өДҝӘФҙРЕПўҙҰАнКэҫЭҪшРРҙҰАнЈ¬іЈУГУЪҙ«ІҘ·ЦОцЎўУГ»§№ШБӘ№ШПөНЪҫтөИИООсЎЈёҙФУНшВз·ЦОцНЁ№эДЈДв·ЦОцҙу№жДЈНјҪб№№өДёҙФУПөНіЈ¬°ьАЁНшВзНШЖЛҪб№№әНПөНі¶ҜБҰС§Ј¬ФЪПөНіСЭ»Ҝ·ҪГжҫЯУР·ЦОцУЕКЖЎўҪПёЯөДИЭҙнРФәНВі°фРФЎЈИ»¶шЈ¬ёҙФУНшВз·ЦОц¶ФКэҫЭБҝөДТӘЗуәЬёЯЈ¬јЖЛгёҙФУ¶ИёЯЈ¬ҝЙҪвКНРФәНҝЙҝШЦЖРФҪПИхЎЈ
Berahmand өИИЛ[16]МбіцБЛТ»ЦЦёДҪшЕ·јёАпөГЛж»ъУОЧЯУРР§өД·Ҫ·ЁҪшРРБҙВ·ФӨІвЎЈёГ·Ҫ·Ё№ДАшЛж»ъУОЧЯПтҫЯУРёьЗҝУ°ПмБҰөДҪЪөгТЖ¶ҜЈ¬ГҝТ»ІҪ¶јёщҫЭЛщФЪҪЪөгөДУ°ПмБҰСЎФсПВТ»ёцҪЪөгЎЈёГСРҫҝ»щУЪ»ҘРЕПў¶ИБҝЈ¬МбіцБЛҪЪөгЦ®јдөД·З¶ФіЖ»Ҙ»ЭУ°ПмөДёЕДоЎЈКөСйҪб№ыұнГчЈ¬УлЖдЛыБҙВ·ФӨІв·Ҫ·ЁПаұИЈ¬ЛщМбіцөД·Ҫ·ЁУРёьёЯөДФӨІвЧјИ·РФЎЈ
Li өИИЛ[17]МбіцБЛТ»ЦЦ»щУЪЧФТт№ыНЖ¶ПЦРөД»мФУТтЛШ·ЦОцөДОЮЖ«НшВз»мПэјјКхЈ¬ТФҪвҫцНЖјцПөНіЦР·ЗЛж»ъИұК§ЈЁMissing-Not-At-RandomЈ¬MNARЈ©өДОКМвЎЈёГ·Ҫ·ЁНЁ№эҝШЦЖЙзҪ»НшВзөД»мПэұЈБф№ЫІвөҪөДЖШ№вРЕПўЈ¬Н¬КұҝЙТФНЁ№эЖҪәвұнКҫС§П°КөПЦИҘ»мПэЈ¬ТФұЈБфЦчТӘөДУГ»§әНОпЖ·МШХчЈ¬ФЪНЖјцЖАј¶ФӨІв·ҪГжҫЯУРәЬәГөД·ә»ҜДЬБҰЎЈ
Naik өИИЛ[18]ГжПтЙзҪ»НшВзёҙФУЙзНЕ»®·ЦөДІўРРҙҰАнәН№ІПн/·ЦІјКҪјјКхУҰУГЗйҝцҝӘХ№БЛЧЫКцСРҫҝЎЈёГСРҫҝИ«ГжМЦВЫБЛФЪПЦУРөДЙзИәјмІв·Ҫ·ЁЦРУҰУГІўРРјЖЛгЎў№ІПнДЪҙжәН·ЦІјКҪДЪҙжөДЗйҝцЎЈ
5 ҫцІЯЦ§іЕ
5.1 РЕПўҝЙКУ»Ҝ
РЕПўҝЙКУ»ҜНЁ№эҪ«КэҫЭіКПЦОӘҝЙҪ»»ҘөДКөМеЈ¬°пЦъУГ»§ёьҝмҪЭЎўёьЦұ№ЫөШАнҪвРЕПўЈ¬ІўФЪ·ЦОц№эіМЦРёьҝмҪЭөШ¶ЁО»РЕПўЦРөД№ШјьҪб№№әНЦШөгДЪИЭЎЈ
Gonzalez-Granadillo өИИЛ[19]К№УГGephi әНD3.jsБҪЦЦ№ӨҫЯҪшРРҝӘФҙРЕПўҙҰАнөДНшВзҝЙКУ»Ҝј°ҪзГжҪ»»ҘЎЈёГСРҫҝҪ«НшВзЦРөДҪЪөгәНұЯУГНјҪб№№өДРОКҪФЪЖБД»ЙПіКПЦЈ¬·ҪұгУГ»§Цұ№ЫөШБЛҪвОДұҫ»тЖдЛыАаРНКэҫЭЦРөД№ШПөЈ¬ІўМṩёьОӘ·бё»өДҪ»»ҘКҪҝЙКУ»ҜЈ¬ұИИзНЁ№эКуұкНПЧ§ЎўЛх·ЕәНЙёСЎөИКЦ¶ОЈ¬КөПЦ¶ФҝЙКУ»ҜКэҫЭөДЧФ¶ЁТеәН№эВЛЎЈHoppa өИИЛ[20]К№УГ¶аЦЦКэҫЭҝЙКУ»ҜјјКхЈ¬ИзИИБҰНјЎўКұјдПЯЎўұэНјәНМхРОНјөИЈ¬ТФ°пЦъУГ»§ёьәГөШАнҪвәН·ЦОцКХјҜөҪөДTwitter ҝӘФҙРЕПўҙҰАнКэҫЭЎЈ
5.2 ұЁёжЙъіЙј°РЕПў№ІПн
РЕПўұЁёжЙъіЙУРЦъУЪЧЬҪб·ЦОц№эіМәНҪб№ыЈ¬УРАыУЪРЕПўөД№ІПнЎЈРЕПў№ІПнөДјјКхМШөгәНР§№ыНЁ№эМбёЯ°ІИ«РФЎўҝЙіЦРшРФәНҝЙА©Х№РФЈ¬К№өГ°ІИ«ЙъМ¬ПөНіөДІ»Н¬ЧйЦҜәНУҰУГіМРтЦ®јдҝЙТФёьәГөШРӯЧчәН№ІПнРЕПўКэҫЭЈ¬Ц§іЦёьУРР§өД°ІИ«ҫцІЯәН·зПХ№ЬАнЎЈ
Cerutti өИИЛ[21]АыУГУпСФЙъіЙјјКхЙъіЙұЁёжЈ¬Іў¶Ф·ЦОц№эөДКэҫЭҪшРРХыАнәН№йДЙЈ¬ёГұЁёжДЬ№»ЗеОъөШ·ҙУіКВјюөД·ўХ№№эіМЎўПЦЧҙәНОҙАҙФӨІвЎЈёГјјКхөДУЕөгФЪУЪҪ«ТСУРКэҫЭҪшРРИЛАаУпСФЧӘ»ҜөДН¬КұЈ¬ДЬ№»МбёЯұЁёжЙъіЙөДР§ВКәНЧјИ·РФЎЈЙъіЙөДұЁёж»№ҝЙТФМṩҪ»»ҘКҪөД·ҪКҪЈ¬К№УГ»§ДЬ№»ёщҫЭЧФјәөДРиЗуЧФУЙөШСЎФсІўдҜААұЁёжЦРөДРЕПўЎЈ
Schwarz өИИЛ[22]ёщҫЭЧҘИЎөҪөДКэҫЭәН·ЦОцөДҪб№ыЈ¬ЧФ¶Ҝ»ҜөШЙъіЙұЁёжЎЈұЁёжЙъіЙөД№эіМЦРҝЙТФНкіЙұЁёжёсКҪөДЙи¶ЁЈ¬°ьАЁұЁёжСщКҪЎўЧЦМеҙуРЎөИЎЈН¬КұЈ¬ТІҝЙТФёщҫЭУГ»§өДРиЗуҪшРРөчХыЈ¬ІўЗТҝЙТФКдіц¶аЦЦёсКҪөДОДјюЈ¬ИзPDFЎўWORDЎўHTML ёсКҪөДОДөөөИЎЈ
Suryotrisongko өИИЛ[23]Ҫ«ҝЙҪвКНИЛ№ӨЦЗДЬЈЁExplainable Artificial IntelligenceЈ¬XAIЈ©ТэИлөҪҝӘФҙРЕПўҙҰАнЦРЈ¬КөПЦБЛНюРІРЕПўөДұЁёжЙъіЙј°№ІПнЎЈёГСРҫҝАыУГXAI јјКхҪвКН»ъЖчС§П°Лг·ЁөДМШХчҫцІЯ№ұПЧЈ¬ҙУ¶шјУЗҝ¶Ф¶сТвУтГыЙъіЙЛг·ЁөДК¶ұрЎўІйХТәН·ЦОцЎЈН¬КұЈ¬XAI јјКхТІҝЙТФИГ·ЦОцИЛФұёьЦұ№ЫөШАнҪвәН·ЦОцЛг·ЁөДҪб№ыЈ¬МбёЯБЛ·ЦОцөДЧјИ·РФәНҝЙҝҝРФЎЈ¶ФУЪұЁёжЙъіЙЈ¬НЁ№эКэҫЭҝвјјКхАҙҙжҙўЛСјҜөҪөДНюРІРЕПўЈ¬ІўАыУГҝЙКУ»ҜјјКхҪ«КэҫЭҪшРР»гЧЬәНЧйЦҜЎЈұЁёжІ»ҪцҝЙТФ·ҙУііцНюРІРЕПўөДЗчКЖәНТміЈөгЈ¬»№ҝЙТФХ№КҫПкПёөДРЕПўДЪИЭәНАъК·КэҫЭЈ¬ИГУГ»§ДЬ№»ёьәГөШАнҪвәНАыУГКэҫЭЎЈ
6 УҰУГПөНі
ФЪ»ҘБӘНшҙуКэҫЭКұҙъЈ¬КАҪзёч№ъІ»¶ПјУҙу¶ФҝӘФҙРЕПўҙҰАнөДСРҫҝІҝКрәНПөНіҝӘ·ўөДН¶ИлЈ¬РОіЙөДУР№ШіЙ№ыПөНіТС·Ч·ЧөГөҪУҰУГЎЈ
ГА№ъЦРСлЗйұЁҫЦЎў№ъјТ°ІИ«ҫЦөИ»ъ№№Ц§іЦСР·ўІўУҰУГБЛУЙPalantir №«ЛҫЙијЖҝӘ·ўөДGotham ҝӘФҙРЕПўҙҰАн·ЦОцПөНі[24]ЎЈёГПөНіөДМШөгКЗДЬ№»ҙҰАнҙуБҝөД¶аФҙТм№№РЕПўКэҫЭЈ¬ҪшРРКэҫЭөДИ«·ҪО»ХыәПУлНЪҫтЈ¬ІўМṩЗҝҙуөДКэҫЭҝЙКУ»ҜЎўДЈДв·ЦОцЎўРЕПўІйСҜәНФӨІвҪЁДЈөИ№ҰДЬЎЈФЪГА№ъХюё®әНҫь¶УІҝГЕ·ҪГжЈ¬Palantir Gotham ПөНіұ»№г·әК№УГЎЈФЪ°ўё»ә№әНТБАӯҝЛХҪХщЖЪјдЈ¬ёГПөНіұ»УГУЪКХјҜЎўХыАнәН·ЦОцЗйұЁРЕПўЈ¬·ўПЦҝЦІАЧйЦҜөДПУТЙИЛІўҪшРР¶ЁО»ЎЈ
I2-AnalystЎҜs NotebookЈЁi2ANЈ©[25]КЗГА№ъIBM№«ЛҫҝӘ·ўөДТ»ҝоГжПтЗйұЁ·ЦОцБмУтөДКэҫЭ·ЦОцИнјюЈ¬ЦчТӘУГУЪ»ҘБӘНшҝӘФҙ·ёЧпЗйұЁ·ЦОцЎў·ҙҝЦөчІйЎўҪрИЪЖЫХ©°ёјю·ЦОцЎўЗйұЁЧЫәП·ЦОцөИЎЈi2AN УөУР¶аЦЦ·ЦОц№ҰДЬЈ¬°ьАЁИЛОпЎўөШөгЎўЧйЦҜ№ШПөөДҝЙКУ»Ҝ·ЦОцЎўКұјдПЯ·ЦОцөИЈ¬ДЬ№»НЪҫтіцТюІШФЪКэҫЭЦРөДЗұФЪПЯЛчЈ¬АнЗеУР№ШКВјюөДВцВзЈ¬°пЦъУГ»§ёьјУҝмЛЩЧјИ·өШЧціцЕР¶ПЈ¬ІўҝЙҪ«ЛщМṩөДРЕПўЎўЦӨҫЭәНҪбВЫЙъ¶ҜХ№КҫёшЙкЗлИЛәНҫцІЯХЯЎЈi2AN өДУГ»§°ьАЁБЛИ«ЗтРн¶а»ъ№№әНІҝГЕЈ¬МШұрКЗФЪГА№ъХюё®әНҫь¶УІҝГЕ·ҪГжЈ¬°ьАЁБӘ°оөчІйҫЦЎўЦРСлЗйұЁҫЦЎў№ъНБ°ІИ«ІҝөИІҝГЕ¶јФЪК№УГёГИнјюЎЈ
Rosette[26]КЗГА№ъBabel Street №«ЛҫөДҝӘФҙРЕПўҙҰАнІъЖ·Ј¬ЦјФЪ°пЦъ·ЦОцИЛФұҙУ¶аЦЦ·ЗҪб№№»ҜКэҫЭФҙЦР»сИЎРЕПўЈ¬ІўҪшРРПа№ШөД·ЦОцәНФӨІвЈ¬°ьАЁЙзҪ»ГҪМеЎўІ©ҝНЎўРВОЕұЁөАЎўНјЖ¬әНТфЖөөИЎЈУлҙ«НіөДРЕПў·ЦОц·Ҫ·ЁІ»Н¬Ј¬Rosette ІЙУГБЛЧФИ»УпСФҙҰАнЎў»ъЖчС§П°әНИЛ№ӨЦЗДЬөИЗ°СШјјКхАҙёЁЦъ·ЦОцИЛФұҪшРРРЕПў·ЦОцЎЈЛьҫЯУР¶аЦЦУпСФЦ§іЦЎўКөКұКэҫЭКХјҜәНҙҰАнЎўҝЙКУ»Ҝ·ЦОцәНУГ»§¶ЁЦЖөИМШөгЎЈBabel XФЪГА№ъәНЖдЛы№ъјТөДҫь¶УәНЗйұЁ»ъ№№ЦРөГөҪБЛ№г·әөДУҰУГЎЈ
ҙЛНвЈ¬ПЦФЪТСУРәЬ¶аҝӘФҙРЕПўҙҰАн·ЦОц№ӨҫЯ№©КАҪз·¶О§ДЪөДСРҫҝХЯК№УГЎЈSpiderFoot[27]КЗТ»ҝоҝӘФҙөДЧФ¶Ҝ»ҜРЕПўКХјҜ№ӨҫЯЈ¬ҝЙ°пЦъУГ»§КХјҜКэҫЭЎў·ЦОцКэҫЭЎўЙъіЙұЁёжј°ҪшРР№ШБӘ·ЦОцЈ¬ҝЙУГУЪЗйұЁ·ЦОцЎўНшВзХмІмЎўЗчКЖ·ЦОцәН·зПХЖА№АөИЎЈtheHarvester[28]КЗТ»ҝоК№УГPython ұаіМУпСФҝӘ·ўөДГьБоРР№ӨҫЯЈ¬ҝЙ°пЦъ°ІИ«СРҫҝИЛФұЎўЙшНёІвКФИЛФұЎўРЕПў°ІИ«ЖуТөЎў№ъјТ°ІИ«»ъ№№өИУГ»§Ј¬ҙУ»ҘБӘНшЙПКХјҜёчЦЦАаРНөДРЕПўЈ¬ИзөзЧУУКјюЎўУтГыЎўРйДвЦч»ъЎўURLЎўIP өШЦ·өИЎЈMetagoofil[29]КЗТ»ҝоҝӘФҙөДҝЙ¶ЁЦЖЛСЛчТэЗжЈ¬Ц§іЦҙУGoogleЎўBing әНYahoo өИЛСЛчТэЗжЦР»сИЎУР№ШДҝұкөДРЕПўЈ¬ЦјФЪ°пЦъ°ІИ«СРҫҝИЛФұЎўЙшНёІвКФИЛФұәН°ІИ«№ЛОКөИУГ»§Ј¬ҙУ»ҘБӘНшЙПЛСЛчУлДҝұ깫Лҫ»тЧйЦҜПа№ШөДОДјюЈ¬ИзОДөөЎўНјЖ¬ЎўҙъВләНЖдЛыОДјюЎЈMitaka[30]ҝЙТФҪ«¶аФҙКэҫЭҫЫәПЈ¬ЧФ¶ҜјмІвІўЙҫіэОЮУГКэҫЭЈ¬ІўМṩёчЦЦНјұнәНКУНјЈ¬°пЦъУГ»§ёьәГөШАнҪвКэҫЭәНРЕПўЎЈ
7 ПЦУРМфХҪ
ФЪКАҪзёч№ъәНС§КхҪзөД№ІН¬НЖ¶ҜПВЈ¬ҝӘФҙРЕПўҙҰАнјјКхТСИЎөГіӨЧгҪшІҪЈ¬ө«ИФГжБЩТФПВ3 ёц·ҪГжөДМфХҪЎЈ
Т»КЗКэҫЭЦКБҝ·ҪГжөДМфХҪЎЈКэҫЭКЗТ»ЗРҝӘФҙРЕПўҙҰАн·ЦОцөД»щКҜЈ¬¶шҝӘФҙРЕПўҙҰАнНЁіЈГж¶ФҫЮҙуөДКэҫЭБҝЈ¬ЗТІ»Н¬ФҙөДКэҫЭҪб№№І»НіТ»Ј¬РЕПўИұЛрөДЗйҝцЖө·ұ·ўЙъЈ¬КэҫЭҝЙҝҝРФЖА№А№эУЪТААөЧЁТөЦӘК¶Ј¬МбёЯБЛИЛБҰЎўКұјдәНҝХјдҝӘПъЎЈ
¶юКЗ·ЦОцЛг·Ё·ҪГжөДМфХҪЎЈИзҪсЈ¬ҝӘФҙРЕПўҙҰАніЈГжБЩҝзУтДҝұк·ЦОцРиЗуЈ¬ИзәО№№ҪЁәПАнөДДҝұкРРОӘұнХчЈ¬Ҫ«ҝзУт¶аФҙРЕПўУлДҝұкҪшРРУРР§№ШБӘЈ¬КөПЦ¶ФДҝұкөДИ«Гж·ЦОцЈ¬КЗИзҪсҝӘФҙРЕПўҙҰАнСРҫҝГжБЩөД№ШјьјјКхМфХҪЎЈ
ИэКЗ·ЁВЙВЧАн·ҪГжөДМфХҪЎЈҝӘФҙРЕПўҙҰАнК№УГҝӘФҙКэҫЭКұРлЧсКШПаУҰөДВЧАн№ж·¶әН·ЁВЙ·Ё№жЈ¬УИЖдКЗФЪҙҰАнГфёРБмУтј°ёцИЛТюЛҪ·ҪГжөДРЕПўКұЈ¬ИзәОҙУјјКхЙПКөПЦГфёРј°ёцИЛРЕПўұЈ»ӨЈ¬·А·¶»ҜҪвГфёРРЕПўР№В¶·зПХЈ¬КЗИзҪсҝӘФҙРЕПўҙҰАн·ЦОцГжБЩөДМфХҪЦ®Т»ЎЈ
8 ОҙАҙХ№Ны
ОҙАҙҝӘФҙРЕПўҙҰАнөДСРҫҝҙуЦВУРИэёц·ҪПтЎЈТ»КЗПИҪшјјКхФЪҝӘФҙРЕПўҙҰАнЦРөДУҰУГЈ¬УИЖдКЗТФЙо¶ИС§П°ОӘҙъұнөДИЛ№ӨЦЗДЬјјКхЈ¬ЖдФЪҝӘФҙРЕПўҙҰАнБмУтөДУҰУГҪ«»бУРР§Ц§іЕҝӘФҙКэҫЭөДҝмЛЩҙҰАнәНРЕПўөДҫ«Чј·ЦОцЎЈ¶юКЗҝзС§ҝЖСРҫҝЎЈУЙУЪҝӘФҙРЕПўҙҰАнЙжј°әЬ¶аІ»Н¬өДБмУтЈ¬ИзЙМТөЎўХюЦОЎўҫьКВЎў№ъјК№ШПөөИЈ¬ИзәОҪ«БмУтЦӘК¶УлҝӘФҙРЕПўҙҰАнПаҪбәПЈ¬ФЪКөјКБмУтУҰУГЦРҪвҫцКөјКөДРЕПў·ЦОцОКМвЈ¬Ҫ«іЙОӘҝӘФҙРЕПўҙҰАнОҙАҙөДСРҫҝИИөгЎЈИэКЗҫцІЯЦ§іЕәНРЕПўјмЛчУЕ»ҜЎЈИзәОҪ«ҝӘФҙРЕПўҙҰАнКэҫЭНЁ№эРЕПўҝЙКУ»ҜөД·ҪКҪіКПЦіцАҙЈ¬ЙъіЙРЕПў·ЦОцұЁёжІўУРР§өШҙ«өЭөҪУГ»§КЦЦРЈ¬МṩёЯР§өДРЕПўјмЛч·ҪКҪЈ¬Ҫ«КЗОҙАҙҝӘФҙРЕПўҙҰАнөДСРҫҝ·ҪПтЦ®Т»ЎЈ
9 ҪбУп
ҝӘФҙРЕПўҙҰАнҫЯУРКэҫЭ»сИЎјтТЧЎўРЕПўёІёЗГж№гөИУЕКЖЈ¬ПЦТСіЙОӘКАҪзёч№ъСРҫҝөДИИөгЈ¬Па№ШіЙ№ыТСУҰУГУЪЙз»бёчБмУтІў·ў»УЧЕЦШТӘЧчУГЎЈұҫОД¶ФөұЗ°№ъНвҝӘФҙРЕПўҙҰАнСРҫҝөДҪшХ№ҪшРРБЛЧЫКцЎЈФЪјјКх·ҪГжЈ¬ұҫЧЫКцёІёЗБЛКэҫЭІЙјҜЎўКэҫЭФӨҙҰАнЎўРЕПў·ЦОцәНҫцІЯЦ§іЕ4 ёцҝӘФҙРЕПўҙҰАн№ШјьІҪЦиөДУР№ШјјКхЈ¬ЖдЦРИЛ№ӨЦЗДЬјјКхФЪҝӘФҙРЕПўҙҰАнЦРөДУҰУГЧоОӘ№г·әЎЈФЪУҰУГПөНі·ҪГжЈ¬ұҫЧЫКц¶Ф№ъНвБчРРөДҝӘФҙРЕПўҙҰАнПөНіҪшРРБЛҪйЙЬЈ¬°ьАЁЙМТөПөНіәНҝӘФҙПөНіЎЈФЪПЦУРМфХҪ·ҪГжЈ¬КэҫЭЦКБҝЎўЛг·Ё·ЦОцәН·ЁВЙВЧАнКЗПЦУРСРҫҝГжБЩөДЦчТӘМфХҪЈ¬¶шПИҪшјјКхөДУҰУГЎўҝзС§ҝЖСРҫҝЎўҫцІЯЦ§іЕәНРЕПўјмЛчУЕ»ҜҪ«КЗОҙАҙҝӘФҙРЕПўҙҰАнөДСРҫҝИИөгЎЈ