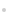Р»БЦСаЈ¬БхјНО°Ј¬ХЕ УсЈ¬ХЕ ·е
ЈЁ№ъјТјЖЛг»ъНшВзУҰјұјјКхҙҰАнРӯөчЦРРДәУұұ·ЦЦРРДЈ¬әУұұ КҜјТЧҜ 050021Ј©
0 ТэСФ
»ҘБӘНшјјКхСёЛЩ·ўХ№Ј¬»ҘБӘНшҪрИЪЧчОӘТ»ЦЦРВЙъөДҪрИЪРОКҪЦрҪҘ·ўХ№ЖрАҙЎЈ»ҘБӘНшҪрИЪНшТіөДТөМ¬К¶ұрКЗ»ҘБӘНшҪрИЪјаІвФӨҫҜУл·зПХ·А·¶өДәЛРД»щҙЎЎЈИ»¶шФЪКөјКЦРЖө·ұіцПЦРВРЛҪрИЪТөМ¬Ј¬Па№ШНшТіКэБҝҪПЙЩЈ¬ЖдЦРЦ»УРЙЩБҝөДНшТіҫӯ№эИЛ№ӨұкЧўЎЈГж¶ФөұЗ°РВРЛ»ҘБӘНшҪрИЪТөМ¬НшТіСөБ·Сщұҫ№эЙЩөДЗйҝцЈ¬ИзәОКөПЦ¶Ф»ҘБӘНшҪрИЪНшТіөДёЯР§ТөМ¬ЕР¶ЁіЙОӘ№ШЧўИИөгЎЈ
НшТі·ЦАаЦчТӘБўЧгУЪОДұҫ·ЦАаЈ¬»ъЖчС§П°КЗНшТі·ЦАаөДТ»ЦЦіЈјы·Ҫ·ЁЈ¬јҜЦРМеПЦФЪНшТіөДМШХчСЎИЎЎўКэҫЭөДМШХчұнҙпЙПЎЈОДПЧ[1]МбіцБЛТ»ЦЦ»щУЪЖУЛШұҙТ¶Л№Рӯөч·ЦАаЖчЧЫәПНшТіҪб№№РЕПўј°ДЪИЭОДұҫөД·ЦАа·Ҫ·ЁЈ¬НЁ№эЧйәП·ЦАаЖчөД·Ҫ·ЁЈ¬К№·ЦАаРФДЬөГөҪБЛТ»¶ЁіМ¶ИөДМбёЯЎЈОДПЧ[2]ЦчТӘІЙУГҫн»эЙсҫӯНшВзЈЁConvolutional Neural NetworksЈ¬CNNЈ©ҪшРРОДұҫ·ЦАаЈ¬МбіцУГУЪҫдЧУ·ЦАаөДөҘҫн»эІгөДҫн»эЙсҫӯНшВзЈЁText CNNЈ©Ј¬АыУГ¶аёцҙуРЎІ»Н¬өДҫн»эәЛАҙІўРРөШМбИЎІ»Н¬өД n-gram РЕПўЈ¬И»әу¶ФЖдҪшРРЧоҙуіШ»ҜЈЁMax PoolingЈ©ІЩЧчМбИЎЦШТӘөДМШХчЈ¬ҙУ¶шНкіЙ·ЦАаЎЈОДПЧ[3]МбіцБЛСӯ»·ҫн»эЙсҫӯНшВзЈЁRecurrent Convolutional Neural NetworkЈ¬RCNNЈ©ДЈРНЈ¬УРР§ҪвҫцБЛ№М¶Ёҙ°ҝЪөДҫн»эІЩЧчК№өГГҝТ»ёцҙКПтБҝөДЙППВОДКЬПЮөДОКМвЈ¬КөСйЦӨГчёГДЈРНФЪОДұҫ·ЦАаЦРЖХұйУЕУЪөҘ¶АөДСӯ»·ЙсҫӯНшВзЈЁRecurrent Neural NetworkЈ¬RNNЈ©»тCNN ДЈРНЎЈОДПЧ[4]ЙијЖБЛ»щУЪЙо¶ИС§П°өДёЯР§НшТі·ЦАаЛг·ЁҝтјЬЈ¬АыУГЙо¶ИЙсҫӯНшВзЈ¬ҙоҪЁБЛТ»ЦЦ¶аНЁөАКдИлЎўёҙәПМШХчійИЎҪб№№өД·ЦАаДЈРНЈ¬УРР§өШМбёЯБЛНшТі·ЦАаөДЧјИ·ВКЎЈ
Йо¶ИС§П°өДУЕКЖЦчТӘТААөУЪЖдҙуКэҫЭөДМбИЎДЬБҰЈ¬ФЪСщұҫБҝЧг№»өДЗйҝцПВЈ¬Йо¶ИС§П°НщНщҝЙТФИЎөГҪПәГөДР§№ыЎЈИ»¶ш¶ФУЪ»ҘБӘНшҪрИЪНшТіАҙЛөЈ¬КэҫЭБҝІ»Чг»бөјЦВДЈРНіцПЦ№эДвәПөДОКМвЎЈТтҙЛЈ¬Хл¶ФРЎКэҫЭјҜөДРЎСщұҫС§П°јјКхКЗҪвҫц»ҘБӘНшҪрИЪНшТі·ЦАаОКМвөД№ШјьЎЈОДПЧ[5]НЁ№э¶Фҙ«НіЦ§іЦПтБҝ»ъЈЁSupport Vector MachineЈ¬SVMЈ©Лг·ЁДЈРНҪшРРөчХыЈ¬ТэИлРВөДІОКэҝШЦЖДЈРНі¬ЖҪГжөДО»ЦГЈ¬ТФ»әҪвХэёәСщұҫІ»ЖҪәв¶Ф·ЦАаЧјИ·ВКөДУ°ПмЎЈОДПЧ[6]Мбіц»щУЪЦч¶ҜС§П°өД°лја¶ҪЦ§іЦПтБҝ»ъС§П°Лг·ЁЈ¬ТФЙЩБҝөДУРұкјЗКэҫЭАҙСөБ·іхКјС§П°ЖчЈ¬НЁ№эЦч¶ҜС§П°ІЯВФАҙСЎФсЧојССөБ·СщұҫЈ¬ІўНЁ№эЙҫіэ·ЗЦ§іЦПтБҝАҙҪөөНС§П°ҙъјЫЈ¬»сөГҪПәГөДС§П°Р§№ыЎЈОДПЧ[7]МбіцБЛТ»ЦЦ»щУЪЗЁТЖС§П°УлИЁЦШЦ§іЦПтБҝ»ъөДНјПсЧФ¶ҜұкЧў·Ҫ·ЁЈ¬ҪвҫцБЛЛщСЎКэҫЭјҜ№жДЈҪПРЎЈ¬ОЮ·ЁСөБ·іцЧоУЕөДҫн»эЙсҫӯНшВзөДОКМвЎЈОДПЧ[8]»щУЪЗЁТЖС§П°Лг·Ё¶ФSVM ДЈРНҪшРРУЕ»ҜЈЁTransferlearning-Support Vector MachineЈ¬TLSVMЈ©Ј¬НЁ№эК№УГДҝұкУтЙЩБҝТСұкјЗКэҫЭәНҙуБҝПа№ШБмУтөДҫЙКэҫЭАҙОӘДҝұкУт№№ҪЁТ»ёцёЯЦКБҝөД·ЦАаДЈРНЎЈ
№ШУЪРЎСщұҫС§П°Ј¬ДҝЗ°іЈУГөДУР»щУЪКэҫЭФцЗҝәН»щУЪЗЁТЖС§П°өД·Ҫ·ЁЎЈ»щУЪКэҫЭФцЗҝөД·Ҫ·ЁЈ¬ЦчТӘКЗАыУГёЁЦъКэҫЭјҜ»тХЯёЁЦъРЕПўФцЗҝДҝұкКэҫЭјҜЦРСщұҫөДМШХчЈ¬»тХЯА©ідДҝұкКэҫЭјҜЈ¬К№ДЈРНДЬ№»ёьәГөШМбИЎМШХч[9]ЎЈ»щУЪЗЁТЖС§П°өД·Ҫ·ЁЈ¬ЦчТӘКЗФЛУГТСҙжУРөДЦӘК¶¶ФІ»Н¬ө«Па№ШөДБмУтОКМвҪшРРЗуҪвөДТ»ЦЦРВөД»ъЖчС§П°·Ҫ·ЁЎЈЛь·ЕҝнБЛҙ«Ні»ъЖчС§П°ЦРөДБҪёц»щұҫјЩЙиЈ¬ДҝөДКЗЗЁТЖТСУРөДЦӘК¶АҙҪвҫцДҝұкБмУтЦРҪцУРЙЩБҝУРұкЗ©СщұҫКэҫЭЙхЦБГ»УРөДС§П°ОКМв[10]ЎЈ
НЁ№эЙПКц·ЦОцЈ¬ОӘБЛЧјИ·ЎўҝмЛЩөШ¶Ф»ҘБӘНшҪрИЪНшТіТөМ¬ҪшРРК¶ұрЈ¬ұҫОДФЪЗЁТЖС§П°әНКэҫЭФцЗҝ·Ҫ·ЁөД»щҙЎЙПЈ¬НЁ№эөчХыі¬ЖҪГжО»ЦГёДҪшSVMЛг·ЁЈ¬КөПЦ¶ФРЎКэҫЭјҜөДСөБ·УлјмІвЎЈКөСйҪб№ыұнГчЈ¬ұҫОДМбіцөД»щУЪі¬ЖҪГжО»ЦГөчУЕSVM өДЗЁТЖС§П°Лг·Ё¶ФУЪ»ҘБӘНшҪрИЪНшТіТөМ¬К¶ұрҫЯУРҪПәГөД·ЦАаР§№ыЈ¬ДЬ№»УРР§јмІвіцТСЦӘТөМ¬өДҪрИЪНшТіЈ¬ҙУ¶шјУЗҝ¶ФёчАаҪрИЪНшТіөД№ШЧўЈ¬Зҝ»Ҝ·зПХ·А·¶Ј¬ҙЩҪш»ҘБӘНшҪрИЪ·ўХ№ЎЈ
1 TL-SVM
SVM КЗCorinna Cortes әНVapnik өИ ИЛ[11]УЪ1995 ДкМбіцөДЈ¬ЦчТӘУГАҙҪвҫцРЎСщұҫЎў·ЗПЯРФј°ёЯО¬ДЈКҪөДК¶ұрЎЈёГ·Ҫ·ЁКЗТФНіјЖС§П°АнВЫЈЁStatistical Learning TheoryЈ¬SLTЈ©[12]өДVC О¬АнВЫәНҪб№№·зПХЧоРЎФӯАнОӘ»щҙЎҪЁБўЖрАҙөДЈ¬ЖдұҫЙнөДУЕ»ҜДҝұкІў·ЗҫӯСй·зПХЧоРЎЈ¬¶шКЗҪб№№»Ҝ·зПХЧоРЎЈ¬ёщҫЭУРПЮөДСщұҫРЕПўФЪДЈРНөДёҙФУРФәНС§П°ДЬБҰЦ®јдС°ЗуЧојСөДХЫЦФ·Ҫ°ёЈ¬ТФЖЪ»сөГЧоәГөДНЖ№г·ә»ҜДЬБҰ[13]ЎЈ
ОДПЧ[8]МбіцөДTL-SVM Лг·ЁөДәЛРДАнВЫКЗЈәИфБҪБмУтПа№ШЈ¬ФтЖдёчЧФ·ЦАаЖчөДҰШЦөУҰПаҪьЈ¬ТтҙЛФЪSVM ДҝұкКҪЦРФцјУЗЁТЖПоҰМ||ҰШt-ҰШs||2ЎЈ
КҪЦРЈәCОӘіН·ЈТтЧУЈ¬ҙъұнЛг·Ё¶ФУЪ·ЦАаҙнОуСщұҫөДИЭИМіМ¶ИЈ»ҙъұнөЪiёцСщұҫөД·ЦАаЛрК§ЎЈ
ёГЛг·ЁФЪДҝұкБмУтСөБ··ЦАаДЈРНКұТэИлБЛФҙБмУтЦӘК¶ҰШsЈ¬ФЪДҝұкәҜКэ№№ҪЁөД№эіМЦРАыУГФҙБмУтәНДҝұкБмУтЦӘК¶ЧоҪУҪьөДЗЁТЖС§П°ПоЈ¬КөПЦУРР§ЗЁТЖС§П°ЎЈИ»¶шЈ¬өұФҙБмУтәНДҝұкБмУтПа№ШРФҪПРЎКұЈ¬Фт»біцПЦёәЗЁТЖПЦПуЈ¬јҙЗЁТЖ№эіМНкіЙәуКөПЦөД·ЦАаР§№ыІоУЪҪцАыУГДҝұкБмУтТСұкјЗКэҫЭөДја¶Ҫ·ЦАаР§№ыЎЈ
2 »щУЪі¬ЖҪГжО»ЦГөчУЕSVM өДЗЁТЖС§П°Лг·Ё
2.1 КэҫЭФцЗҝ
КэҫЭФцЗҝ[14]ЈЁData AugmentationЈ¬DAЈ©ёДЙЖБЛЙо¶ИС§П°ЦРКэҫЭІ»ЧгөДіЎҫ°Ј¬ФЪІ»КөЦКРФөШФцјУКэҫЭөДЗйҝцПВЈ¬ИГУРПЮөДКэҫЭІъЙъөИјЫУЪёь¶аКэҫЭөДјЫЦөЎЈЖдФӯАнКЗЈ¬НЁ№э¶ФФӯКјКэҫЭИЪИлПИСйЦӘК¶Ј¬јУ№Өіцёь¶аКэҫЭөДұнКҫЈ¬УРЦъУЪДЈРНЕРұрКэҫЭЦРөДНіјЖФлЙщЈ¬јхЙЩДЈРН№эДвәПЎЈЖдЦчТӘөД·ҪПтКЗФцјУСөБ·КэҫЭөД¶аСщРФЈ¬ҙУ¶шМбёЯДЈРН·ә»ҜДЬБҰЎЈРЎСщұҫС§П°өДЦчТӘОКМвКЗСщұҫБҝ№эЙЩЈ¬ҙУ¶шөјЦВСщұҫ¶аСщРФІ»ЧгТФҝМ»ӯНкХыСщұҫ·ЦІјЈ¬ҝЙТФНЁ№эСщұҫФцЗҝАҙМбЙэСщұҫ¶аСщРФЎЈ»щУЪКэҫЭФцЗҝөД·Ҫ·ЁКЗАыУГёЁЦъКэҫЭјҜ»тХЯёЁЦъРЕПў¶ФДҝұкКэҫЭјҜҪшРРКэҫЭА©ід»тМШХчФцЗҝЈ¬К№ДЈРНДЬёьәГДвәПЎЈКэҫЭА©ідҝЙТФКЗОЮұкЗ©»тХЯәПіЙҙшұкЗ©КэҫЭЈ»МШХчФцЗҝКЗФЪФӯСщұҫөДМШХчҝХјдЦРМнјУұгУЪ·ЦАаөДМШХчЈ¬ФцјУМШХч¶аСщРФЈ¬ҙУ¶шҪөөНСщұҫјдөДІ»ҫщәвРФЈ¬МбёЯДЈРНөД·ә»ҜДЬБҰЈ¬К№ДЈРНөДВі°фРФёьёЯЎЈ
ФЪСщұҫЙЩЎў·ЦІјІ»ҫщәвөДЗйҝцПВЈ¬ҝЙТФНЁ№эКэҫЭФцЗҝ[15]А©ідСөБ·КэҫЭөДБҝЈ¬ҪөөНСщұҫјдөДІ»ҫщәвРФЈ¬МбёЯДЈРНөД·ә»ҜДЬБҰЈ¬К№ДЈРНөДВі°фРФёьёЯЎЈКэҫЭФцЗҝјјКх°ьАЁ»ШТлЈЁBack TranslationЈ©ЎўЛж»ъҙКМж»»Ўў·ЗәЛРДҙКМж»»Ўў»щУЪЙППВОДРЕПўөДКэҫЭФцЗҝәН»щУЪУпСФЙъіЙДЈРНөДКэҫЭФцЗҝ5 ЦЦҫӯөд·Ҫ°ёЎЈЖдЦРЈ¬»щУЪЛж»ъҙКМж»»өДКэҫЭФцЗҝ·Ҫ·ЁАаЛЖУЪНјПсФцЗҝјјКхЦРөДЛж»ъІГјфЎўНјПсЛх·ЕЈ¬НЁіЈКЗЛж»ъөШСЎФсОДұҫЦРТ»¶ЁұИАэөДҙКЈ¬¶ФЖдҪшРРН¬ТеҙКМж»»ЎўЙҫіэөИјтөҘІЩЧчЎЈұҫОДІЙУГ»щУЪЛж»ъҙКМж»»өДјтөҘКэҫЭФцЗҝЈЁEasy Data AugmentationЈ¬EDAЈ©[15]ОДұҫФцЗҝ·Ҫ·ЁКөПЦКэҫЭФцЗҝЈ¬ЦчТӘ°ьә¬ТФПВ4 ЦЦІЩЧчЈә
ЈЁ1Ј©Н¬ТеҙКМж»»ЈЁSynonym ReplacementЈ¬SRЈ©ЈәҙУҫдЧУЦРЛж»ъСЎФс·ЗНЈУГҙКЈ¬УГЛж»ъСЎФсөДН¬ТеҙКМж»»ХвР©өҘҙКЎЈ
ЈЁ2Ј©Лж»ъІеИлЈЁRandom InsertionЈ¬RIЈ©ЈәЛж»ъХТіцҫдЧУЦРДіёцІ»КфУЪНЈУГҙКјҜөДҙКЈ¬ІўЗуіцЖдЛж»ъөДН¬ТеҙКЈ¬Ҫ«ёГН¬ТеҙКІеИлҫдЧУөДТ»ёцЛж»ъО»ЦГЈ¬ЦШёҙnҙОЎЈ
ЈЁ3Ј©Лж»ъҪ»»»ЈЁRandom SwapЈ¬RSЈ©ЈәЛж»ъСЎФсҫдЧУЦРБҪёцөҘҙКІўҪ»»»ЛьГЗөДО»ЦГЈ¬ЦШёҙnҙОЎЈ
ЈЁ4Ј©Лж»ъЙҫіэЈЁRandom DeletionЈ¬RDЈ©ЈәТФёЕВКpЛж»ъЙҫіэҫдЧУЦРДіёцөҘҙКЎЈ
2.2 »щУЪі¬ЖҪГжО»ЦГУЕ»ҜSVM өДЗЁТЖС§П°Лг·Ё
УЙУЪұкјЗСщұҫКэБҝІ»ЧгЈ¬ТтҙЛФЪДЈРНСөБ·№эіМЦРҝЙМṩөДУРР§РЕПўІ»ҫщәвЈ¬Н¬КұЈ¬»щУЪSVM Лг·ЁөД·ЦАаЈ¬ФЪСщұҫКэБҝЙЩЎўОЮ·ЁЧјИ·ФӨ№АёәАаСщұҫҙжФЪҝХјдөДЗйҝцПВЈ¬ТэИлІОКэЦч¶ҜөчХы·ЦАаі¬ЖҪГжөДО»ЦГЈ¬К№ЖдҝҝҪьХэАаСщұҫЈ¬ОӘёәАаСщұҫФӨБфҪПҙуөДҙжФЪҝХјдЈ¬ТФҙЛМбёЯ·ЦАаөДЧјИ·ВКЎЈ»щУЪі¬ЖҪГжО»ЦГУЕ»ҜSVM өДЗЁТЖС§П°Лг·ЁКөПЦБЛБмУтјдІОКэөДЗЁТЖЈ¬ФӯАнИзНј1 ЛщКҫЈ¬ЖдУЕ»ҜДҝұкәҜКэөДұнҙпКҪОӘЈә
Нј1 »щУЪі¬ЖҪГжО»ЦГУЕ»ҜSVM өДЗЁТЖС§П°Лг·ЁјмІвБчіМ
КҪЦРЈәөчХыі¬ЖҪГжөДіМ¶ИНЁ№эІОКэҰЛҪшРРҝШЦЖЈ¬ИфҰЛҪПҙуЈ¬ФтФҙБмУтәНДҝұкБмУтөД·ЦАаі¬ЖҪГж·ЗіЈҪУҪьЈ»ИфҰЛҪПРЎЈ¬ФтФҙБмУтәНДҝұкБмУтөД·ЦАаі¬ЖҪГжПа¶Ф¶АБўЎЈ
¶ФУЪУЕ»ҜДҝұкәҜКэЈ¬БРіцИзПВЛөГчЈә
ЈЁ1Ј©КҪЈЁ2Ј©ЦРЗ°БҪПо·ЦұрұнКҫДҝұкБмУтКэҫЭөДҪб№№·зПХПоәНҫӯСй·зПХПоЎЈ
ЈЁ2Ј©||ҰШt-ҰШs||2ұнКҫДҝұкБмУтУлФҙБмУтөДІоТміМ¶ИЈ¬КэЦөФҪҙуұнКҫ·ЦАаЖчЦ®јдөДІоТмФҪҙуЈ¬·ҙЦ®ұнКҫ¶юХЯПаЛЖЈ¬ҰМОӘРӯөчПөКэЎЈ
КҪЦРЈәҰБ=(ҰБ1,ҰБ2,Ўӯ,ҰБn)TәНҰВ=(ҰВ1,ҰВ2,Ўӯ,ҰВn)TОӘАӯёсАКИХПөКэЎЈ
ТАҫЭKKT[16]ЈЁKarush-Kuhn-TuckerЈ©МхјюЈ¬¶ФҰШtЈ¬әНbtЗуЖ«өјКэЈ¬НЖөјИзПВЈә
Ҫ«КҪЈЁ4Ј©ЎўКҪЈЁ5Ј©ҙъИлКҪЈЁ3Ј©Ј¬»ҜјтәуҝЙөГ¶ФЕјОКМвРОКҪИзПВЈә
2.3 »щУЪі¬ЖҪГжО»ЦГөчУЕSVM өДЗЁТЖС§П°Лг·ЁБчіМ
ЈЁ2Ј©АыУГ¶юҙО№ж»®ФӯАнЗуөГДҝұкУтАӯёсАКИХПөКэҰБt=(ҰБ1,ҰБ2,Ўӯ,ҰБn)TЈ»
ЈЁ3Ј©ёщҫЭКҪЈЁ4Ј©ЗуөГҫцІЯі¬ЖҪГж·ЁПтБҝҰШtЈ»
ЈЁ5Ј©№№ҪЁ»®·Ці¬ЖҪГжҰШtxt+bt=0Ј¬Кдіц·ЦАаҫцІЯәҜКэ
ЧЫЙПЈ¬»щУЪі¬ЖҪГжО»ЦГУЕ»ҜSVM өДЗЁТЖС§П°Лг·ЁјмІвБчіМИзНј1 ЛщКҫЎЈ
3 КөСйУл·ЦОц
ОӘЖАјЫСйЦӨ»щУЪі¬ЖҪГжО»ЦГөчУЕSVM өДЗЁТЖС§П°Лг·ЁФЪ»ҘБӘНшҪрИЪНшТіТөМ¬·ЦАаЦРөДР§№ыЈ¬КөСйІЙУГҙУ»ҘБӘНшКХјҜөҪөДҪрИЪНшТіОӘЖАІвКэҫЭјҜЈ¬ёГКэҫЭјҜ°ьә¬451 ёц»ҘБӘНшҪрИЪНшТіЈ¬Йжј°4 ёцҪрИЪТөМ¬ПВөД8 ёцҪрИЪЧУТөМ¬Ј¬ұн1 ОӘҪрИЪТөМ¬УлПа№ШНшТіөДКэБҝЎЈГҝБҪёцҪрИЪТөМ¬·ЦұрЧчОӘХэСщұҫәНёәСщұҫЈ¬»щУЪЧУТөМ¬ҪшРРјмІвЈ¬С§П°ИООсөДҫЯМеЗйҝцИзұн2 ЛщКҫЎЈФЪДҝұкБмУтСЎИЎФҙБмУтСөБ·јҜКэБҝөД20%ЧчОӘДҝұкБмУтөДСөБ·јҜЈ¬№№іЙЗЁТЖС§П°ИООсЎЈКөСйЦчТӘҙУ·ЗЗЁТЖЎўЗЁТЖәН»щУЪі¬ЖҪГжО»ЦГөчУЕSVM өДЗЁТЖ3 ёцҪЗ¶ИАҙҪшРРЈ¬ҙУ¶шХ№ПЦЛщМб·ЦАаЛг·ЁөДУЕКЖЎЈ
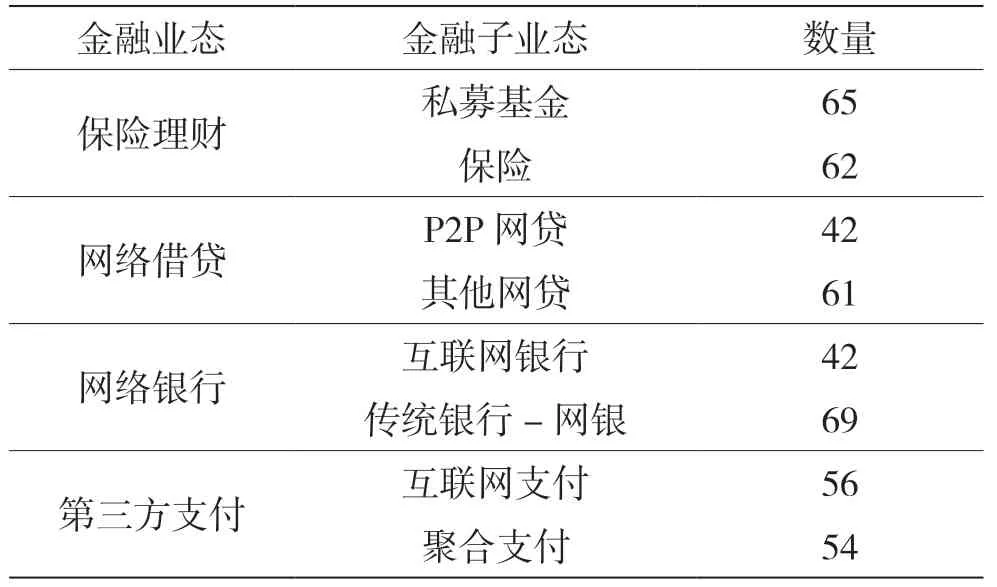
ұн1 ҪрИЪТөМ¬УлПа№ШНшТіКэБҝ

ұн2 С§П°ИООсҫЯМеЗйҝц
3.1 ЖАјЫЦёұк
ұҫОДІЙУГХэИ·ВКЈЁPrecisionЈ©ЎўХЩ»ШВКЈЁRecallЈ©әНЧЫәПЦёұкF1-ЦёКэЈЁF1Ј©АҙЖАІв»ҘБӘНшҪрИЪНшТіјмІвөДРФДЬЎЈЖдЦРЈ¬ХэИ·ВКPұнКҫ·ө»ШҪб№ыЦРХэИ·өДұИАэЈ¬ХЩ»ШВКRұнКҫЛщУРХэИ·Ҫб№ыЦР·ө»ШөДұИАэЎЈФЪјмІвҪб№ыЦРЈ¬Изұн3 ЛщКҫЈ¬јЩЙијмІвөҪөД»ҘБӘНшҪрИЪНшТіЦРЈ¬Па№ШНшТіөДКэБҝОӘaЈ¬І»Па№ШНшТіөДКэБҝОӘbЈ»ФЪОҙјмІвөҪөД»ҘБӘНшҪрИЪНшТіЦРЈ¬Па№ШНшТіөДКэБҝОӘcЈ¬І»Па№ШНшТіөДКэБҝОӘdЎЈ

ұн3 ЖАјЫЦёұк
ЖдЦРЈ¬ІвКФКэҫЭЦРУлҪрИЪТөМ¬Па№ШөД»ҘБӘНшҪрИЪНшТіКэДҝОӘa+cЈ¬І»Па№ШөД»ҘБӘНшҪрИЪНшТіКэДҝОӘb+dЎЈјмІвҪб№ыЦРЈ¬ЕР¶ЁУлҪрИЪТөМ¬Па№ШөД»ҘБӘНшҪрИЪНшТіКэДҝОӘa+bЈ¬І»Па№ШөД»ҘБӘНшҪрИЪНшТіКэДҝОӘc+dЎЈ№ШУЪКөСйЦРөДКэҫЭјҜЈ¬ФҙБмУтәНДҝұкБмУтөДСщұҫҫщОӘТСұкјЗРЕПўЈ¬ө«ДҝұкБмУтСщұҫөДұкјЗРЕПўҪцУГУЪЖАјЫёчЛг·ЁөД·ЦАаРФДЬЎЈХэИ·ВКPЎўХЩ»ШВКRәНЧЫәПЦёұкF1 өДјЖЛг·Ҫ·ЁИзПВЈә
3.2 КөСйЙијЖУлҪб№ы·ЦОц
ұҫОДҪ«ёчАаТөМ¬»ҘБӘНшҪрИЪНшТі°ҙХХtest_size=0.5Ј¬»®·ЦОӘСөБ·јҜәНІвКФјҜЎЈН¬КұЈ¬°ҙХХДҝұкУтСөБ·СщұҫЧЬКэ20%өДұИАэЈ¬СЎИЎДҝұкУтЦРөДКэҫЭјҜЧчОӘДҝұкУтСөБ·јҜЈ¬КЈУаОӘДҝұкБмУтІвКФјҜЈ¬КөПЦЗЁТЖС§П°ЎЈ
ұҫОДКөСйЦРЛщУРЛг·ЁөДЧоУЕІОКэҫщНЁ№эНшёсЛСЛчөД·ҪКҪАҙИ·¶ЁЎЈЖдЦРіН·ЈТтЧУCtЈ¬ҰМөДСЎИЎІОХХОДПЧ[8]өДЙи¶ЁІЯВФЈ¬јҙТтДҝұкУтІОУлСөБ·өДСщұҫКэБҝЙЩЈ¬УҰҫЎБҝұЈЦӨ·ЦАаөДХэИ·РФЈ¬ТтҙЛCtФЪЈЁ0.01,0.05,0.1,0.5,1,5,10,20,50Ј©ЦРСЎЧо УЕЈ»ҰМФЪЈЁ0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1Ј©ЦРСЎЧоУЕЎЈ
НЁ№эі¬ЖҪГжО»ЦГөчХыІОКэҰЛЈ¬КөПЦ¶Фі¬ЖҪГжөДЧоУЕО»ЦГөДСЎ¶ЁЈ¬ҙУ¶шКөПЦ¶Ф»ҘБӘНшҪрИЪНшТіТөМ¬К¶ұрөДЧјИ·¶ИЎЈКөСйІЙУГұҫОДМбіцөД»щУЪі¬ЖҪГжО»ЦГУЕ»ҜSVM өДЗЁТЖС§П°Лг·ЁЈ¬НЁ№эөчХыҰЛөДЦөЈ¬И·¶Ёі¬ЖҪГжО»ЦГ¶Ф»ҘБӘНшҪрИЪНшТіТөМ¬·ЦАаөДУ°ПмЗйҝцЎЈУЙУЪұҫОДЦчТӘХл¶ФРЎКэҫЭјҜөДРЎСщұҫС§П°Ј¬ҝјВЗөҪМбёЯКэҫЭ·ЦАаөДХэИ·ВКұгУЪәуРш·ЦАаДЈРНөДУЕ»ҜЈ¬ИфҰЛҪПҙуЈ¬ФтФҙБмУтәНДҝұкБмУтөД·ЦАаі¬ЖҪГж·ЗіЈҪУҪьЈ¬іцПЦОуұЁөДёЕВКФцҙуЈ»ИфҰЛҪПРЎЈ¬ФтФҙБмУтәНДҝұкБмУтөД·ЦАаі¬ЖҪГжПа¶Ф¶АБўЈ¬ҝЙУРР§ұЈЦӨ·ЦАаөДХэИ·ВКЎЈОӘұЈЦӨі¬ЖҪГжО»ЦГПтХэАаСщұҫҝҝҪьЈ¬ОӘёәАаСщұҫБфіцёьҙуөДҙжФЪҝЙДЬРФҝХјдЈ¬ҰЛөДИЎЦө·¶О§ОӘ(0,1)ЎЈ
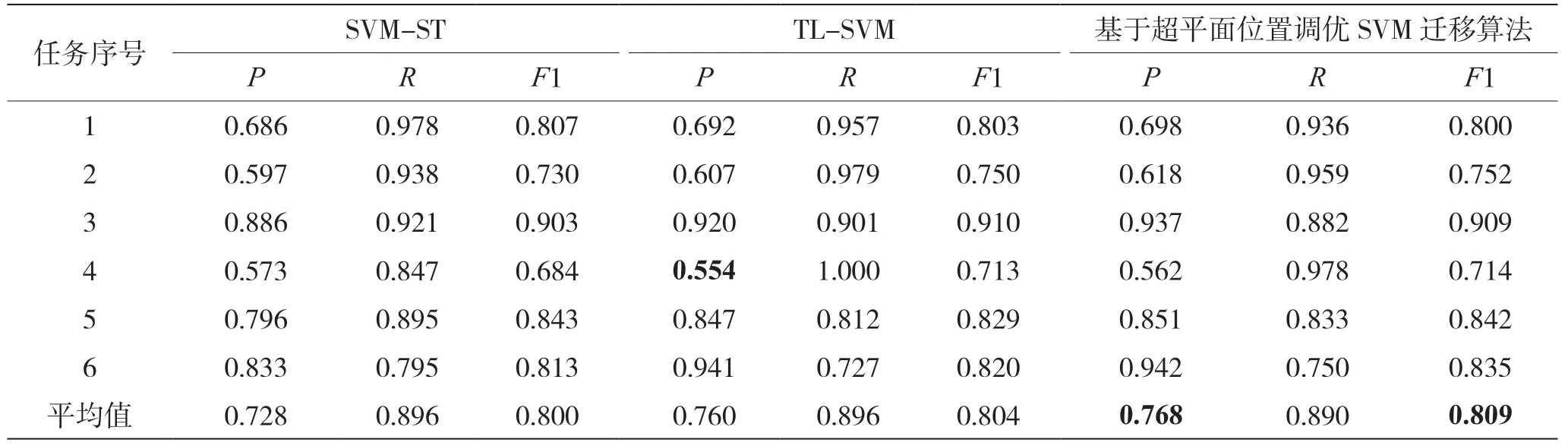
ұҫОДКөСйІЙУГФҙБмУтУлДҝұкБмУтТСұкјЗСщұҫәПјҜЧчОӘSVM өДСөБ·јҜҪшРРСөБ·Ј¬ұкјЗОӘSVM-STЈ¬АыУГҙЛ·Ҫ·ЁУлЗЁТЖС§П°·Ҫ·ЁЧцұИҪПЈ¬Н¬КұЈ¬Ҫ«ұҫОДМбіцөД·Ҫ·ЁУлОДПЧ[8]ЦРМбіцөДTL-SVM ·Ҫ·ЁЧцұИҪПЈ¬УГТФЛөГчұҫОДЛщМб·Ҫ·ЁөДУЕФҪРФЎЈ3 ЦЦ·Ҫ·ЁФЪ6 ёцС§П°ИООсЦРөД·ЦАаРФДЬұИҪПИзұн4 ЛщКҫЎЈ
ұн4 3 ЦЦ·Ҫ·ЁРФДЬұИҪП
ёщҫЭКөСйҪб№ыЈ¬өГіцТФПВҪбВЫЈә
ЈЁ1Ј©НЁ№э¶ФұИ3 ёцКөСйөДҪб№ы·ўПЦЈ¬ЗЁТЖС§П°·Ҫ·ЁөДТэИл¶Ф·ЦАаР§№ыУРГчПФМбЙэЈ¬¶ФұИSVMST ·ЦАа·Ҫ·ЁЈ¬ХэИ·ВКМбЙэҪПОӘГчПФЈ¬TL-SVM Лг·ЁҪПSVM-ST Лг·ЁөД·ЦАаХэИ·ВКМбЙэБЛ3.2%Ј¬F1 ІвКФЦөМбЙэБЛ0.4%Ј»»щУЪі¬ЖҪГжО»ЦГөчУЕSVM ЗЁТЖЛг·ЁҪПSVM-ST Лг·ЁөД·ЦАаХэИ·ВКМбЙэБЛ4.0%Ј¬F1 ІвКФЦөМбЙэБЛ0.9%Ј¬ЛөГчЗЁТЖС§П°·Ҫ·ЁФЪПаЛЖБмУтөДКэҫЭ·ЦАаЦРЈ¬УЕКЖёьГчПФЎЈ
ЈЁ2Ј©НЁ№э¶ФұИTL-SVM Лг·ЁәНSVM-ST Лг·ЁөДКөСйҪб№ыЈ¬·ўПЦ¶ФУЪФҙБмУтУлДҝұкБмУт№ШБӘРФҪПөНөДКэҫЭјҜЈЁНшВзҪиҙыvs НшВзТшРРЈ©Ј¬TL-SVM өД·ЦАаХэИ·ВК·ҙ¶шҪөөНБЛЈ¬ЛөГчTL-SVM ФЪҙҰАнКэҫЭёәЗЁТЖ·ҪГжУРЛщЗ·ИұЎЈ
ЈЁ3Ј©НЁ№э¶ФұИTL-SVM әН»щУЪі¬ЖҪГжО»ЦГөчУЕSVM ЗЁТЖЛг·ЁөДКөСйҪб№ыЈ¬·ўПЦНЁ№эөчХыі¬ЖҪГжО»ЦГЈ¬К№ЖдПтХэАаСщұҫҝҝҪьЈ¬ұЈЦӨБЛ·ЦАаөДХэИ·ВКЎЈ»щУЪі¬ЖҪГжО»ЦГөчУЕSVM ЗЁТЖЛг·ЁҪПTL-SVMЛг·ЁөД·ЦАаХэИ·ВКМбЙэБЛ0.8%Ј¬F1 ІвКФЦөМбЙэБЛ0.5%Ј¬ЛөГчНЁ№эКэҫЭФцЗҝәН·ЦАаі¬ЖҪГжО»ЦГөчХыЈ¬ФЪСщұҫКэБҝЙЩЎўОЮ·ЁЧјИ·ФӨ№АёәАаСщұҫҙжФЪҝХјдөДЗйҝцПВЈ¬·ЦАаі¬ЖҪГжЦч¶ҜҝҝҪьХэАаСщұҫЈ¬ұЈЦӨБЛ·ЦАаөДХэИ·РФЎЈ
4 ҪбУп
ұҫОДМбіцБЛ»щУЪі¬ЖҪГжО»ЦГөчУЕөДSVM ЗЁТЖЛг·ЁЎЈёГ·Ҫ·ЁНЁ№э·ЦАаөчХыі¬ЖҪГжО»ЦГЈ¬К№Ждід·ЦҝҝҪьХэАаСщұҫЈ¬ҪбәПКэҫЭФцЗҝјјКхЈ¬КөПЦ¶ФРЎКэҫЭјҜөДСөБ·УлјмІвЈ¬¶ФУЪКэҫЭБҝІ»ЧгөД»ҘБӘНшҪрИЪНшТіАҙЛөЈ¬УРР§ҪвҫцБЛДЈРНіцПЦ№эДвәПөДОКМвЎЈКөСйҪб№ыұнГчЈ¬»щУЪі¬ЖҪГжО»ЦГөчУЕөДSVM ЗЁТЖЛг·ЁФЪРЎСщұҫөДЗйҝцПВДЬ№»МбёЯјмІвРФДЬЦёұкЎЈ