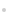Бх ІЁЈ¬НтО¬НюЈ¬ЧЮҙуҫщЈ¬Ао Бў
ЈЁЦР№ъөзЧУҝЖјјјҜНЕ№«ЛҫөЪИэК®СРҫҝЛщЈ¬ЛДҙЁ іЙ¶ј 610041Ј©
0 ТэСФ
ДҝЗ°Ј¬И«ЗтНшВз°ІИ«РОКЖИХТжСПҫюЈ¬Хл¶Ф№ШјьРЕПў»щҙЎЙиК©өД¶сТвНшВз№Ҙ»чЖө·ўЎЈЛжЧЕёәәЙІаЧКФҙІ»¶ПА©ідЈ¬өзБҰјаҝШПөНіөД°ІИ«·А»Ө·¶О§І»¶ПА©ҙуЈ¬ҪУИл°ІИ«ПФөГУИОӘЦШТӘЎЈЛжЧЕ°ІИ«·А»Ө·¶О§өДІ»¶ПНШХ№Ј¬ІъЙъөД°ІИ«КэҫЭИХТжұ¶ФцЈ¬ёжҫҜКэБҝІ»¶ПФцҙуЈ¬ИзәОИ·ұЈёжҫҜј°КұУРР§Ј¬МбЙэёжҫҜөДҫ«Чј¶ИәНКөР§РФЈ¬іЙОӘ°ІИ«·А»Өја№ЬөДТ»ҙуДСМв[1]ЎЈ
ҙуБҝС§ХЯ¶ФЦЗДЬёжҫҜјјКхҝӘХ№БЛЙоИлСРҫҝЎЈЖдЦРЈ¬УРСРҫҝАыУГK-ҪьБЪЛг·ЁЈЁK-Nearest Neighbors algorithmЈ¬KNNЈ©Ўўҫн»эЙсҫӯНшВзЈЁConvolutional Neural NetworkЈ¬CNNЈ©өИ»ъЖчС§П°»тИЛ№ӨЦЗДЬЛг·Ё¶ФөзНшҙуКэҫЭҪшРРЗеПҙЈ¬ІўІЙУГөдРНҪЁДЈ·Ҫ·Ё·ЦОц°ІИ«КВјюЈ¬КөПЦ¶ФөзНшКэҫЭөДЦЗДЬҙҰАн[2-5]Ј¬ө«КЗХвР©Лг·ЁРиТӘХјУГТ»¶ЁөДјЖЛгҝХјдЎЈҙЛНвЈ¬»№УРСРҫҝ»щУЪ№жФтЎўДЈРНөИ»щұҫКэҫЭЈ¬ІЙУГІгҙО·ЦОц·ЁөИ·Ҫ·ЁөГөҪөұЗ°ёжҫҜРЕПўМШХчІўҪшРР·ЦІг·ЦАаЈ¬ОӘёьҫЯјЫЦөөДКэҫЭ·ЦЕдёьёЯИЁЦШ[6]Ј¬ө«ҙЛАа·Ҫ·ЁРиТӘ¶аГыЧЁјТ¶ФКэҫЭөДЦШТӘРФҪшРРЖАјЫЈ¬К№УГЖрАҙҪПОӘ ·іЛцЎЈ
Хл¶ФЙПКцОКМвЈ¬ұҫОДК№УГK-Means[7]әНDBSCAN[8]Лг·ЁЈ¬ТФөзБҰјаҝШПөНіНшВз°ІИ«№ЬАнЖҪМЁөДАъК·ёжҫҜКэҫЭОӘҙҰАнКэҫЭЈ¬МбИЎёжҫҜКэҫЭМШХчРЕПўЈ¬ҪшРР¶аО¬¶ИөДМШХчҫЫАаЈ¬ЧоЦХҪЁБўөзБҰјаҝШПөНіНшВз°ІИ«КВјюёжҫҜКэҫЭЧЫәП·ЦОцДЈРНЈ¬МбёЯТСУР·ЦОцПөНіөДР§ВКЎЈ
1 Лг·ЁГиКц
1.1 K-Means ҫЫАаЛг·Ё
ЧчОӘҫӯөдЗТУҰУГ№г·әөДҫЫАаЛг·ЁЦ®Т»Ј¬K-Means ҫЫАаЛг·ЁҫЯУРөДУЕөгУРАнВЫҝЙҝҝЎўЛг·ЁјтөҘЎўКХБІЛЩ¶ИҝмЎўДЬУРР§ҙҰАнҙуКэҫЭјҜөИЎЈK-MeansЛг·ЁЦРөДK ҙъұнАаҙШёцКэЈ¬Means ҙъұнАаҙШДЪКэҫЭ¶ФПуөДҫщЦөЎЈK-Means Лг·ЁКЗТ»ЦЦ»щУЪ»®·ЦөДҫЫАаЛг·ЁЈ¬ТФҫаАлЧчОӘКэҫЭ¶ФПујдПаЛЖРФ¶ИБҝөДұкЧјЈ¬јҙКэҫЭ¶ФПујдөДҫаАлФҪРЎЈ¬ЛьГЗөДПаЛЖРФФҪёЯЈ¬ФтЛьГЗФҪУРҝЙДЬФЪН¬Т»ёцАаҙШЎЈ
ҫЯМеөДҫЫАа№эіМИзПВЈә
Лг·Ё1ЈәK-Means Лг·Ё


1.2 DBSCAN ҫЫАаЛг·Ё
DBSCAN »щУЪТ»ЧйБЪУтАҙГиКцСщұҫјҜөДҪфГЬіМ¶ИЈ¬ІОКэ(ҰЕ,MinPts)УГАҙГиКцБЪУтөДСщұҫ·ЦІјҪфГЬіМ¶ИЎЈЖдЦРЈ¬ҰЕГиКцБЛДіТ»СщұҫөДБЪУтҫаАлгРЦөЈ¬MinPtsГиКцБЛДіТ»СщұҫөДҫаАлОӘҰЕөДБЪУтЦРСщұҫёцКэөДгРЦөЎЈ
DBSCAN Лг·ЁөДҫЯМеҫЫАа№эіМИзПВЈә
Лг·Ё2ЈәDBSCAN Лг·Ё

2 өзНшёжҫҜКэҫЭ·ЦОцУлҙҰАнДЈРН
ұҫОДМбіцөДөзНшёжҫҜКэҫЭ·ЦОцУлҙҰАнДЈРНЈ¬·ЦОӘ»щУЪКұјдөДK-Means ҫЫАаәН»щУЪМШХч№ШјьҙКөДDBSCAN ҫЫАаЎЈөЪ1 ІҪЦчТӘК№УГK-Means ¶ФКдИлөДФӯКјёжҫҜИХЦҫКэҫЭҪшРРС№ЛхЈ¬ТАҫЭөДМхјюОӘИХЦҫКэҫЭЦРөДКұјдРЕПўЈ¬°ьАЁёжҫҜКэҫЭЧоРВ·ўЙъКұјдәНёжҫҜҝӘКјКұјдЎЈөЪ2 ІҪФтМбИЎЗ°Т»ІҪС№ЛхәуКэҫЭөДМШХчЈ¬ёщҫЭМШХч№ШјьЧЦК№УГDBSCAN Лг·ЁҪшРРҪшТ»ІҪС№ЛхЎЈЧоЦХКөПЦ¶ФөзНшФӯКјёжҫҜИХЦҫКэҫЭөДС№ЛхУлҫЫАаЈ¬ҪЁБўөзБҰјаҝШПөНіНшВз°ІИ«КВјюёжҫҜКэҫЭЧЫәП·ЦОцДЈРНЈ¬ІўёщҫЭҫЫАаөДҪб№ы¶ФёжҫҜКэҫЭҪшРР·ЦОцәНСРЕРЈ¬ёшіцГҝТ»АаёжҫҜРЕПўөДҫЯМеГиКцЈ¬МбёЯПЦУРөзНшёжҫҜКэҫЭ·ЦОцПөНіөДР§ВКЎЈДЈРНөДҫЯМеБчіМИзНј1 ЛщКҫЎЈ
2.1 »щУЪКұјдөДK-Means ҫЫАа
·ЦОцФӯКјёжҫҜИХЦҫКэҫЭҝЙТФ·ўПЦЈ¬ПЦУРөДөзНшёжҫҜПөНіёщҫЭёжҫҜКэҫЭөДёчПоКфРФ¶ФФӯКјКэҫЭҪшРРБЛҫЯПу»ҜГиКцЎЈ¶ФУЪИОТвТ»МхёжҫҜКэҫЭsЈ¬ёщҫЭКфРФҝЙТФҪ«Жд»®·ЦОӘёжҫҜј¶ұрЎўёжҫҜДЪИЭЎўёжҫҜЙиұёЎўЙПұЁЙиұёЎўёжҫҜҝӘКјКұјдЎўЧоРВ·ўЙъКұјдЎўёжҫҜҙОКэЎўЙПұЁЧҙМ¬ЎўИХЦҫАаРНЎўИХЦҫЧУАаРНәНёжҫҜЧҙМ¬Ј¬ҫЯМеҝЙТФГиКцОӘsЈЁlevel,content,dev_ale,dev_up,time_beg,time_new,count,status_up,type_main,type_sub,status_aleЈ©ЎЈК№УГK-Means Лг·ЁҝЙТФёщҫЭИОТ»КфРФ¶ФФӯКјКэҫЭјҜҪшРРҫЫАаЈ¬ө«КөјКҫЫАаР§№ыУРЛщІ»Н¬Ј¬ЧоЦХҪшРРГиКцКұЛщТАҫЭөДКфРФТІ»бҙжФЪІоТмЎЈұҫДЈРНЦчТӘҙУёжҫҜКэҫЭөДКұјдО¬¶Иіц·ўЈ¬ҝјВЗФӯКјёжҫҜКэҫЭјҜЦРөДёжҫҜЧоРВ·ўЙъКұјдS.time_new әНёжҫҜҝӘКјКұјдS.time_begЈ¬ЧоЦХҫЫАаНкіЙәуҪ«КұјдО¬¶ИЧчОӘРЕПўГиКцөДТ»ёцЦШөгЎЈ»щУЪёжҫҜКэҫЭЦРКұјдКфРФөДK-Means ҫЫАаИзНј2 ЛщКҫЎЈ
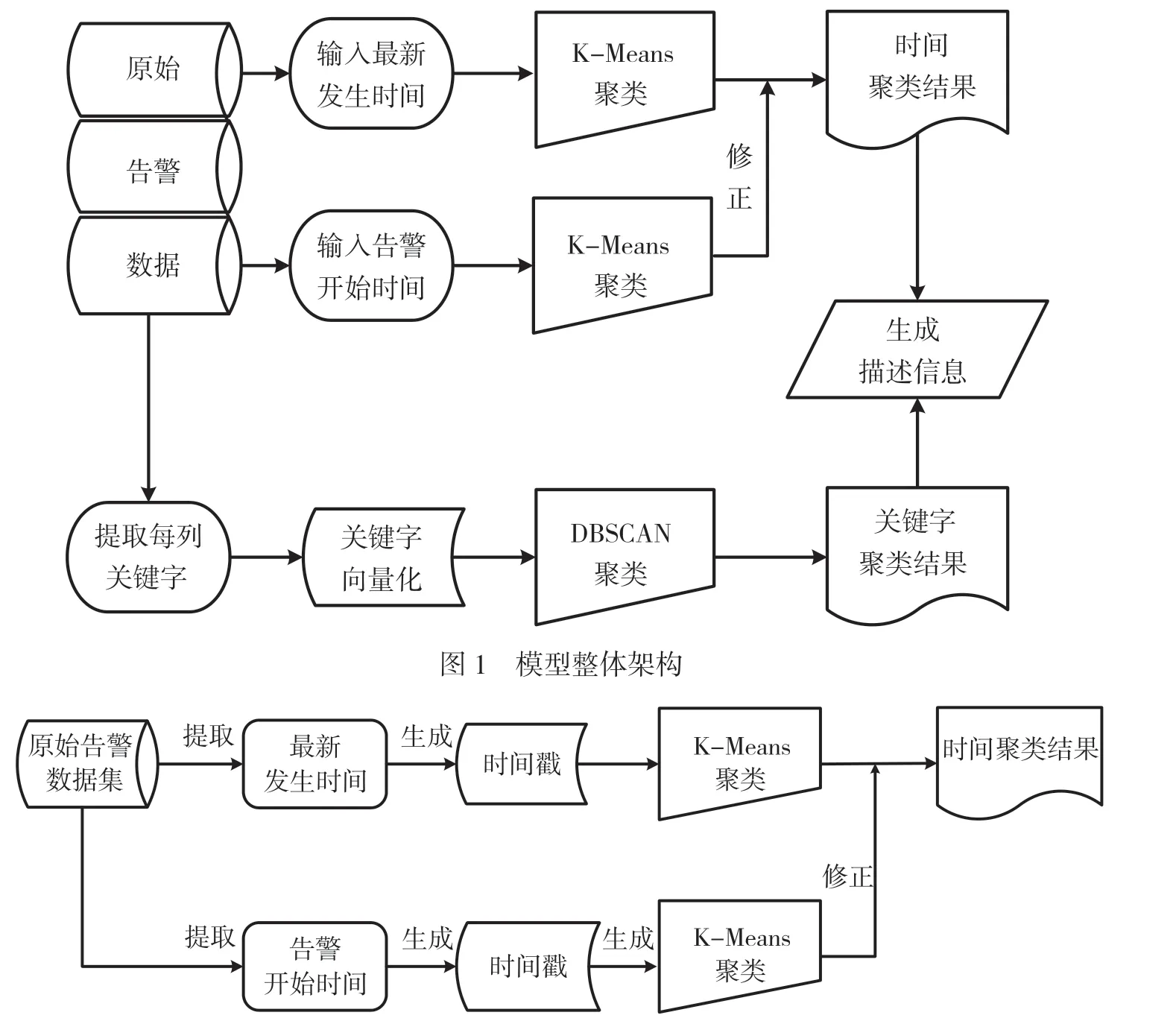
Нј2 »щУЪКұјдКфРФөДK-Means ҫЫАа
ҙЛНвЈ¬ФЪҪшРРБҪҙОK-Means ҫЫАаКұЈ¬»№РиҝјВЗіхКјөДKЦөСЎИЎЎЈKЦөөДІ»Н¬»бј«ҙуөШУ°ПмҫЫАаөДР§№ыЈ¬ҫЯМеKЦөөДСЎИЎРиТӘҝјВЗҫЫАаәуКұјдО¬¶ИөДЧјИ·ВКЎЈҙЛҙҰҪшРРKЦөСЎИЎөД№жФт¶ЁТеЈәФЪ¶ФФӯКјКэҫЭјҜөДКұјдО¬¶ИҪшРР·ЦОцөД»щҙЎЙПЈ¬ёшіцҫЫАаәуёчАаұрөДФӨЖЪКұјдҝз¶ИTkЈ¬јҙөұ°ҙХХДіёцKЦө¶ФФӯКјКэҫЭөДКұјдО¬¶ИҪшРРK-Means ҫЫАаәуЈ¬ГҝёцАаЦРөДКұјдҝз¶И¶јВъЧгtkЎЬTkЈ¬ҙЛКұіЖКұјдО¬¶ИөДK-Means ҫЫАаҙпөҪЧоУЕР§№ыЎЈН¬АнЈ¬¶ФKЦөСЎИЎКұ¶ФУҰөДЧјИ·ВКAcck¶ЁТеИзПВЈә¶ФУЪКұјдО¬¶ИөДK-Means ҫЫАаЈ¬ЧјИ·ВКAcckЦёҫЫАаәуВъЧгtkЎЬTkөДАаұрКэБҝУлЛщУРАаұрКэБҝөДұИЦөЈ¬јҙВъЧгФӨЖЪКұјдҝз¶ИТӘЗуөДАаұрУлЧЬАаұрөДұИЦөЎЈФӯКјКэҫЭјҜөДКұјдҝз¶ИЎўҫЫАаәуёчАаұрөДФӨЖЪКұјдҝз¶ИTkЎўІ»Н¬өДіхКјKЦө¶ј»бУ°ПмҫЫАаәуКұјдО¬¶ИөДЧјИ·ВКЈ¬ТтҙЛРиТӘНЁ№эҫЯМеКөСйАҙИ·¶ЁЧоУЕөДІОКэҪшРРK-Means ҫЫАаЈ¬К№ҫЫАаөДС№ЛхВКәНЧјИ·ВКҙпөҪПа¶ФЧоУЕөДҪб№ыЎЈ
2.2 »щУЪМШХч№ШјьҙКөДDBSCAN ҫЫАа
ФЪҪшРРDBSCAN ҫЫАаЦ®З°Ј¬РиТӘҪ«3.1 ҪЪЦРҫЫАаәуөДҪб№ыҪшРР»щУЪ№ШјьҙКөДПтБҝ»ҜІЩЧчЈ¬ТтҙЛРиТӘ¶ФS.levelЎўS.content өИёжҫҜКэҫЭөДКфРФҪшРР·ЦОцЈ¬ёшіц№ШјьҙКПтБҝ»ҜөД»щұҫ№жФтЎЈУЙУЪёжҫҜЙиұёТФј°ЙПұЁЙиұёІоТмРФҪПРЎЈ¬ІўЗТІў·ЗЧоЦХ№ШБӘРФГиКцКұөДФӘЛШЈ¬ТтҙЛЦұҪУУГ№М¶ЁөДКэЦөҙъМжS.dev_ale әНS.dev_up БҪёцКфРФФӯКјЧЦ·ыҙ®ДЪИЭЈ¬ЖдЛы7 БРКфРФөД№ШјьҙКПтБҝ»Ҝ№жФтИзұн1 ЛщКҫЎЈ

ұн1 №ШјьҙКПтБҝ»Ҝ№жФт
К№УГХэФт»ҜұнҙпКҪ¶ФФӯКјКэҫЭјҜЦРГҝМхИХЦҫКэҫЭҪшРР№ШјьЧЦЛСЛчУлЖҘЕдЈ¬ҪУЧЕёщҫЭЙПКц№жФтҪ«№ШјьҙКЛщФЪБРЧӘ»»ОӘКэС§ПтБҝЈ¬Н¬КұҪ«S.dev_aleЎўS.dev_upЎўS.time_beg әНS.time_new Хв4 БРЦұҪУЧӘ»»ОӘ№М¶ЁөДКэЧЦЈ¬УГУЪұЈЦӨХыМеКэҫЭөД№жёсНіТ»ЎЈ
3 КөСйј°Ҫб№ы·ЦОц
3.1 КөСйКэҫЭјҜУлІОКэЙиЦГ
СЎИЎөзБҰјаҝШПөНіҪьТ»ёцјҫ¶ИөДАъК·ёжҫҜКэҫЭЈ¬·ЦОӘ30 ёцөШКРЈ¬ГҝёцөШКРөДКэҫЭөҘ¶АҙжҙўЈ¬ЧЬМхДҝКэОӘ4 739 МхЎЈКөСйПИ»щУЪЧоРВ·ўЙъКұјдЈ¬К№УГK-Means ¶ФФӯКјКэҫЭјҜҪшРРҫЫАаЎЈТФЖдЦРДіөШКРөДёжҫҜКэҫЭОӘАэЈ¬ёГөШКРҪьТ»јҫ¶ИөДёжҫҜКэҫЭЧЬМхДҝКэnumbОӘ108 МхЈ¬ЧоРВ·ўЙъКұјдөДКұјдҝз¶ИОӘ2021.08.29 05:28:48ЎӘ2021.11.27 18:39:04Ј¬ФтіхКјKЦөөДСЎИЎ·Ҫ·ЁОӘЈә»сИЎЧоРВ·ўЙъКұјдөДКұјдҝз¶ИКұјдҙБРОКҪОӘ1 630 186 128Ў«1 638 009 544Ј¬ТтҙЛКұјдҝз¶ИT=1 638 009 544-1 630 186 128=7 823 416ЎЈёщҫЭТӘЗуЙи¶ЁҫЫАаәуёчАаұрөДФӨЖЪКұјдҝз¶ИTkОӘЈЁ2.5,3Ј©МмЈ¬КұјдҙБРОКҪПВTkОӘ(216 000,259 200)Ј¬Н¬Кұ№ж¶ЁKөД·¶О§ОӘ[10%ЎБnumb,30%ЎБnumb]ЎЈ¶ФУЪёГөШКРЈ¬јҙKКфУЪ[10.8,32.4]Ј¬ІўЗТKОӘХэХыКэЎЈН¬Ан»сИЎёжҫҜҝӘКјКұјдөДКұјдҝз¶ИЈ¬ёшіц¶ФУҰөДKЦө ·¶О§ЎЈ
НЁ№э¶аҙОКөСйСйЦӨKөДИЎЦөУлЧјИ·ВКAcckЦ®јдөД№ШПөЈ¬ҫЯМеКөСйҪб№ыИзНј3 ЛщКҫЎЈ
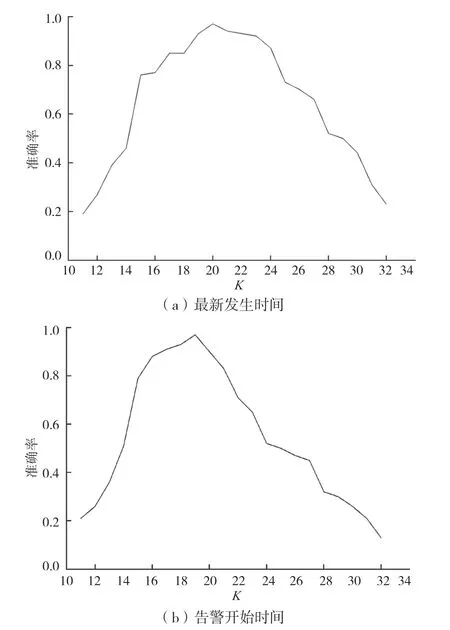
Нј3 ЧоРВ·ўЙъКұјдәНёжҫҜҝӘКјКұјдөДK ЦөУлЧјИ·ВКөД№ШПө
УЙНј3ЈЁaЈ©ҝЙЦӘЈ¬өұKЦөСЎИЎ20 КұЈ¬Хл¶ФёГөШКРөДЧоРВ·ўЙъКұјдҪшРРK-Means ҫЫАаЈ¬ҝЙТФҙпөҪЧоёЯөДЧјИ·ВКЈ¬К№өГҫЫАаәуЧјИ·ВКҙпөҪ97%ЎЈУЙ Нј3ЈЁbЈ©ҝЙЦӘЈ¬өұKЦөСЎИЎ19 КұЈ¬Хл¶ФёГөШКРөДёжҫҜҝӘКјКұјдҪшРРK-Means ҫЫАаЈ¬ҝЙТФҙпөҪЧоёЯөДЧјИ·ВКЈ¬К№өГҫЫАаәуКұјдҝз¶ИВъЧгТӘЗуөДАаұрКэУлЧЬАаұрКэөДұИАэҙпөҪ97%ЎЈ
К№УГCalinski-Harabaz ЦёұкЈЁјтіЖCH ЦёұкЈ©¶ФKөДИЎЦөҪшРРСйЦӨЈ¬CH ЦёұкНЁ№эАајд·ҪІоәНАаДЪ·ҪІоЦ®ұИјЖЛгөГ·ЦЈ¬өГ·ЦФҪҙуұнКҫР§№ыФҪәГЎЈ¶ФЧоРВ·ўЙъКВјюөДKЦөҪшРРCH ЦёұкјЖЛгЈ¬УЙНј4ЈЁaЈ©ҝЙЦӘЈ¬KЦөСЎИЎ20 »т30 ЧуУТКұЈ¬CH ЦёұкЦөПаҪПУЪЖдЛыKЦөКэЦөҪПҙуЎЈЧЫәПНј3ЈЁaЈ©әННј4ЈЁaЈ©өДҪб№ыЈ¬СЎИЎK=20 ЧчОӘХл¶ФёГөШКРөДөЪ1 ҙОK-Means ҫЫАаЎЈ
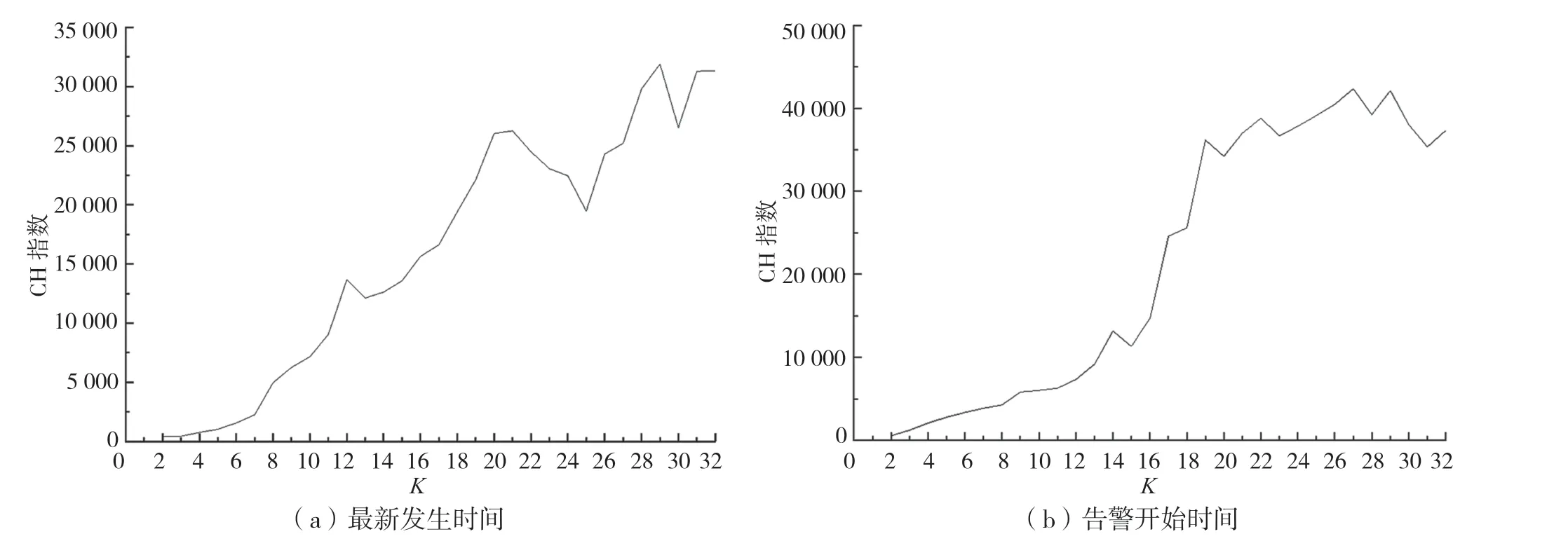
Нј4 ЧоРВ·ўЙъКұјдәНёжҫҜҝӘКјКұјдөДK ЦөУлCH ЦёұкөД№ШПө
УЙНј4ЈЁbЈ©ҝЙЦӘЈ¬өЪ2 ҙО»щУЪёжҫҜҝӘКјКұјдөДҫЫАаЈ¬KҙуУЪ»төИУЪ19 КұҝЙТФҙпөҪЧоёЯөДЧјИ·ВКәНҪПәГөДҫЫАаҪб№ыЎЈЧЫәПНј3ЈЁbЈ©әННј4ЈЁbЈ©өДҪб№ыЈ¬СЎИЎK=19 ЧчОӘХл¶ФёГөШКРөДөЪ2 ҙОK-Means ҫЫАаЎЈ
КөСйөЪ2 ҪЧ¶ОІЙУГDBSCAN Лг·ЁЎЈ¶ФУЪёГөШКРөДКэҫЭЈ¬ҝјВЗБЪУт°лҫ¶ҰЕУлФлЙщВКЦ®јдөД№ШПөЈ¬ҪшРР¶аҙОКөСйЈ¬ЧоЦХөГөҪөД№ШПөИзНј5 ЛщКҫЎЈ
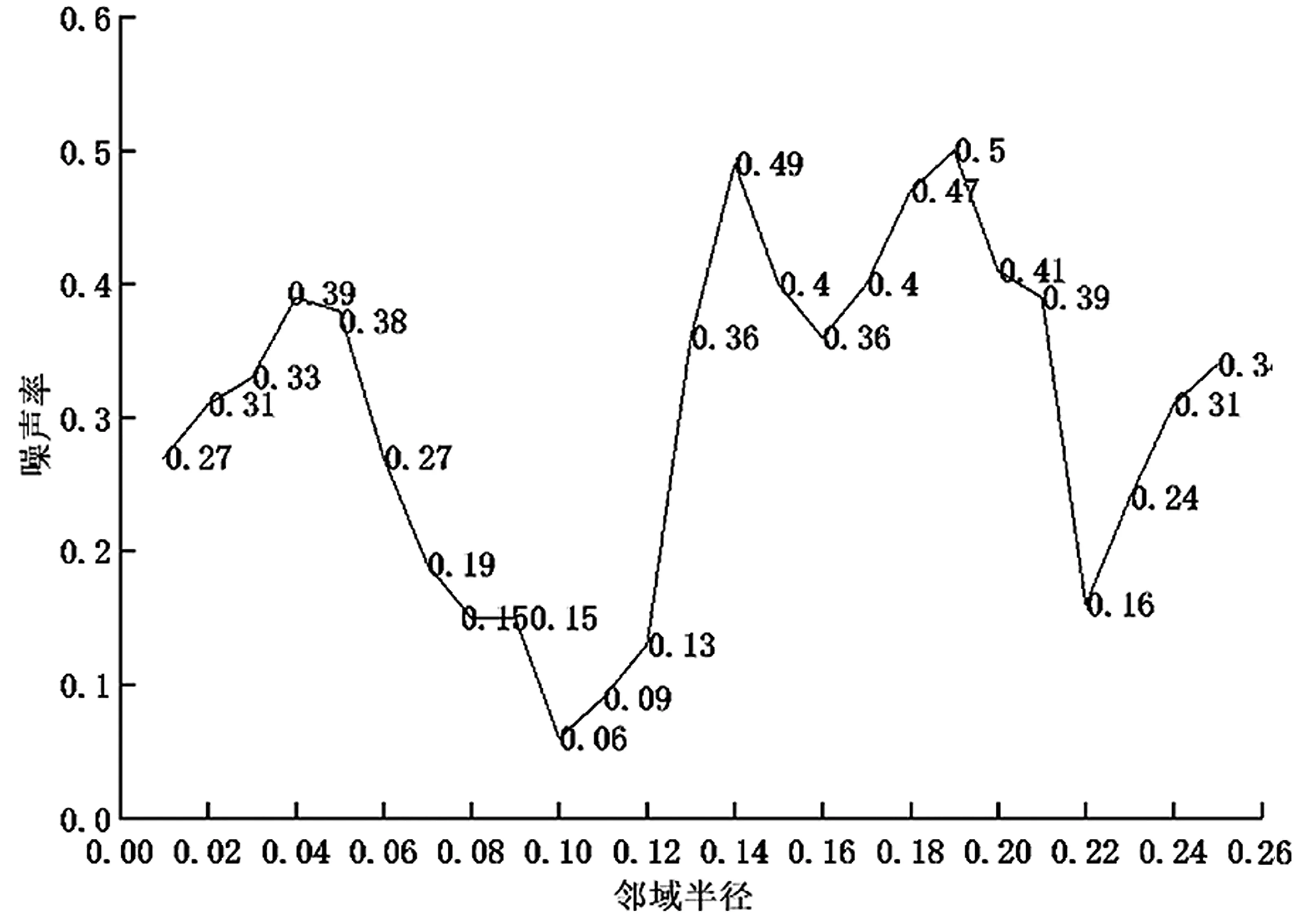
Нј5 БЪУт°лҫ¶УлФлЙщВКөД№ШПө
УЙНј5 ҝЙЦӘЈ¬DBSCAN ҫЫАаСЎИЎ0.1 ЧчОӘЧоУЕөДБЪУт°лҫ¶ҰЕЈ¬¶шБЪУтЦРКэҫЭ¶ФПуКэДҝгРЦөMinPtsФтОӘГҝёцөШКРөҘ¶АОДјюПВИХЦҫЧУАаРНөДЦЦАаКэБҝЈ¬ҙЛКұҪшРРDBSCAN ҫЫАаҝЙТФҙпөҪЧоУЕР§№ыЎЈ
3.2 ЖА№АЦёұк
КөСй¶ФУЪҫЫАаҪб№ыөДЖАјЫЈ¬ЦчТӘІЙУГТФПВ3 ёцЦёұкЎЈ
ЈЁ1Ј©С№ЛхВКЈЁCompression rateЈ©ЎЈС№ЛхВКЦёҫЫАаәуКэҫЭРОіЙөДАаКэБҝУлҫЫАаЗ°ЛщУРМхДҝКэБҝөД ұИЦөЎЈ
ЈЁ2Ј©ФлЙщВКЈЁNoise rateЈ©ЎЈФлЙщөгЦёОҙіЙ№ҰНкіЙҫЫАаөДМхДҝЈ¬ФлЙщВКЦёҫЫАаәуіцПЦөДФлЙщөгКэБҝУлҫЫАаЗ°ЛщУРМхДҝКэБҝөДұИЦөЎЈ
ЈЁ3Ј©ЧјИ·ВКЈЁAccuracyЈ©ЎЈЧјИ·ВКЦёҫЫАаәуВъЧгtkЎЬTkөДАаұрКэБҝУлЛщУРАаұрКэБҝөДұИЦөЈ¬јҙВъЧгФӨЖЪКұјдҝз¶ИТӘЗуөДАаұрУлЧЬАаұрөДұИЦөЎЈ
УЙЙПГжөД¶ЁТеҝЙЦӘЈ¬С№ЛхВКФҪёЯЎўФлЙщВКФҪөНЎўЧјИ·ВКФҪёЯөДҫЫАаҪб№ыКЗЧоУЕҪб№ыЎЈ
3.3 КөСйУлҪб№ы·ЦОц
°ҙХХЙПКц·Ҫ·ЁЈ¬КЧПИ¶ФКдИлөДДіөШКРҪь°лДкёжҫҜКэҫЭҪшРРҫЫАаЈ¬ІЙУГK-Means ҫЫАаЛг·ЁЈ¬НіјЖёГөШКРёжҫҜКэҫЭОДјюЦРКэҫЭМхДҝКэnumbОӘ108 МхЈ¬јЖЛгіхКјKЦөОӘ20ЎЈҪУЧЕ»щУЪёжҫҜКэҫЭөДЧоРВ·ўЙъКұјдҪшРРK-Means ҫЫАаЈ¬ҫЯМе№эіМОӘЈәМбИЎГҝМхКэҫЭөДЧоРВ·ўЙъКұјдІўЧӘ»ҜіЙұкЧјКұјдРОКҪЈ¬ФЩЙъіЙ¶ФУҰөДКұјдҙБЈ¬ҪУЧЕСЎИЎ20 ёцІ»Н¬өДКұјдҙБЧчОӘіхКјҫЫАаЦРРДЈ¬¶ФИОТвТ»МхКэҫЭЈ¬ЗуЖдКұјдҙБөҪ20 ёцҫЫАаЦРРДөДҫаАлЈ¬Ҫ«Жд№йАаөҪҫаАлЧоРЎөДЦРРДөДҫЫАаЎЈІ»¶ПөьҙъІўФЪГҝҙОөьҙъ№эіМЦРАыУГҫщЦө·ЁёьРВёчҫЫАаөДЦРРДөгЈ¬ЧоЦХҪ«ЛщУР108 МхКэҫЭҪшРРҫЫАаЈ¬·ЦОӘ20 ҙуАаЈ¬ЧчОӘK-Means өЪТ»ҙОҫЫАаөДҪб№ыЎЈҫЫАаҪб№ыИзНј6 ЛщКҫЎЈ
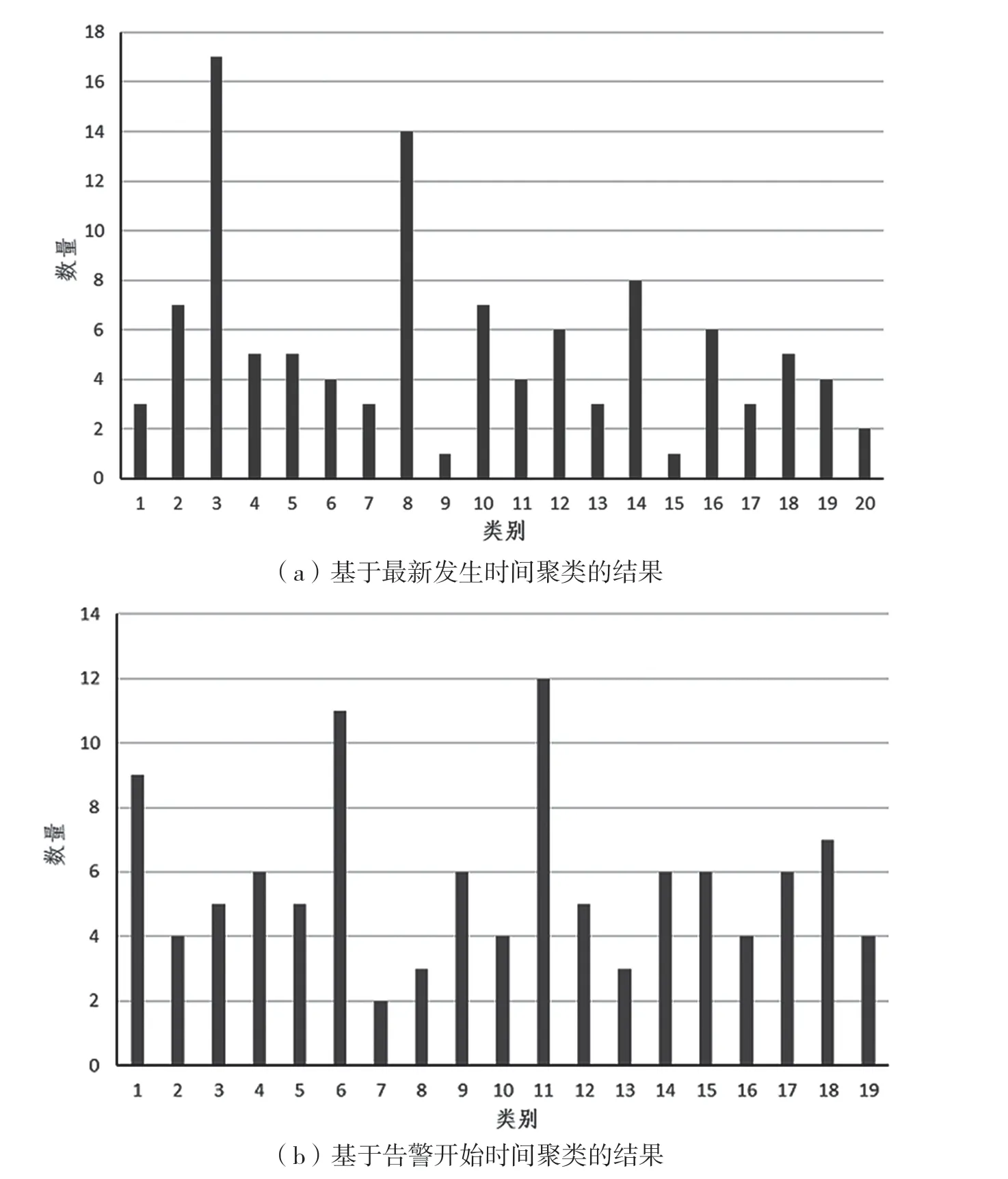
Нј6 »щУЪёжҫҜКэҫЭЧоРВ·ўЙъУлҝӘКјКұјдҪшРРҫЫАаөДҪб№ы
Нј6ЈЁaЈ©ОӘ»щУЪёжҫҜКэҫЭЧоРВ·ўЙъөДҫЫАа·ЦІјЈ¬·ЦОц·ўПЦЈ¬ТАҫЭЧоРВ·ўЙъКұјдҪшРРҫЫАаКұЈ¬ҙжФЪІҝ·ЦКэҫЭёжҫҜҝӘКјКұјдПаН¬ө«ОҙҙҰУЪН¬Т»АаөДЗйҝцЈ¬ЦчТӘФӯТтКЗөЪТ»ҙОҫЫАаЦ»ҝјВЗБЛЧоРВ·ўЙъКұјдХвТ»КфРФЈ¬¶шОҙҝјВЗёжҫҜҝӘКјКұјдЈ¬ТтҙЛФЪКұјдО¬¶ИЙП»№УРУЕ»ҜҝХјдЎЈ»щУЪёжҫҜКэҫЭөДҝӘКјКұјдҪшРРK-Means ¶юҙОҫЫАаЈ¬ҙЛКұКдИлКэҫЭјҜТАҫЙОӘёГөШКР¶ФУҰөДёжҫҜКэҫЭФӯКјОДјюЈ¬KЦөСЎИЎ19ЎЈҫЫАаҪб№ыИзНј6ЈЁbЈ©ЛщКҫЈ¬ҝЙТФ·ўПЦ¶юҙОҫЫАаДЬ№»РЮХэөЪТ»ҙОҫЫАаәуіцПЦөДТміЈЗйҝцЈ¬ІўЗТС№ЛхВКёьёЯЎЈЧоЦХ»гЧЬK-Means БҪҙОҫЫАаөДҪб№ыЈ¬ЧчОӘөЪТ»ҪЧ¶ОK-Means өДКдіцЎЈ
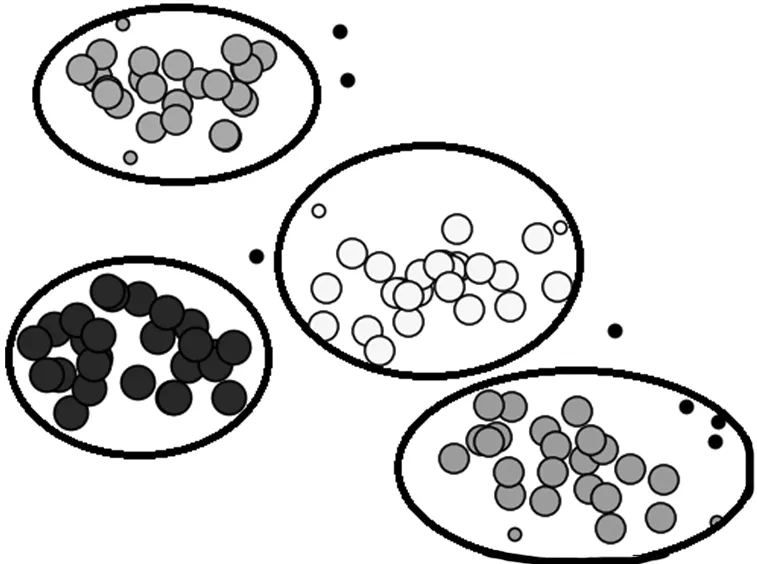
ДЈРНөЪ¶юҪЧ¶ОАыУГDBSCAN Лг·Ё¶ФёжҫҜКэҫЭөД№ШјьЧЦО¬¶ИҪшРРФЩҙОҫЫАаЈ¬КЧПИ°ҙХХ3.2 ҪЪөД№ШјьҙКПтБҝ»Ҝ№жФтЈ¬¶ФёГөШКРЛщУРКэҫЭҪшРРПтБҝ»ҜІЩЧчЈ¬ЖдҙОЙиЦГБЪУт°лҫ¶ҰЕОӘ0.1Ј¬БЪУтЦРКэҫЭ¶ФПуКэДҝгРЦөMinPtsОӘёГөШКРёжҫҜОДјюЦРИХЦҫЧУАаРНөДЦЦАаКэБҝ4ЎЈФЪ¶ФКдИлО¬¶ИҪшРРҪөО¬ІЩЧчЦ®ә󣬶ФҫЫАаҪб№ыҪшРРҝЙКУ»ҜЈ¬Ҫб№ыИзНј7 ЛщКҫЎЈҙУҫЫАаҪб№ыҝЙТФҝҙіцЈ¬ФЪЛщУРөД108 МхКэҫЭЦРЦ»ҙжФЪ7 ёцФлЙщөгЈ¬ТвО¶ЧЕЦ»УР7 МхКэҫЭГ»УРНкіЙ ҫЫАаЎЈ
Нј7 DBSCAN ҫЫАаҪб№ы
ІЙУГН¬СщөД·Ҫ·Ё¶ФёГКЎЖдЛы29 ёцөШКРөДёжҫҜКэҫЭҪшРРҫЫАа·ЦОцЈ¬ЧоЦХөГөҪЛщУРөШКРөДҫЫАаЗйҝцИзНј8 ЛщКҫЎЈ30 ёцөШКРЦРЈ¬УР19 ёцөШКРөДС№ЛхВКҙпөҪ20%ТФПВЈ¬30ёцөШКРөДС№ЛхВК¶јҙпөҪ30%ТФПВЈ¬ЖҪҫщС№ЛхВКОӘ23.62%ЎЈЧјИ·ВК·ҪГжЈ¬27 ёцөШКР¶јҙпөҪ80%ТФЙПЈ¬ЖҪҫщЧјИ·ВКОӘ88.34%ЎЈФлЙщВК·ҪГжЈ¬25 ёцөШКР¶јөНУЪ20%Ј¬ЖҪҫщФлЙщВКОӘ15.06%ЎЈ
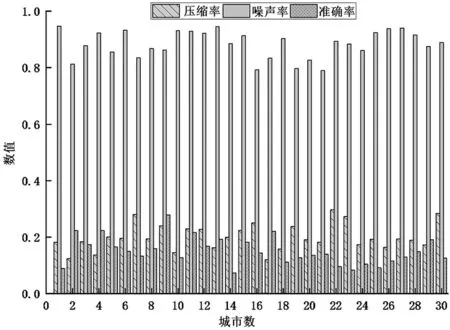
Нј8 30 ёцөШКРөДҫЫАаҪб№ы
Чоәу»щУЪҫЫАаәуөДҪб№ыЈ¬ІЙУГ№ШБӘРФҪб№ыГиКцЈ¬ҫЯМеГиКцөДРЕПўОӘЈәДіөШКРөДөЪЎБЎБМхЦБЎБЎБМхИХЦҫФЪyyyy-mm-dd hh:mm:ss ЦБyyyy-mm-dd hh:mm:ss ЖЪјдДЪ·ўЙъБЛЎБЎБКВјюЈ¬јҙёщҫЭИХЦҫЧоРВ·ўЙъКұјдәНИХЦҫЧУАаРНөДҫЫАаҪб№ыЈ¬·Ц¶ОГиКцёжҫҜКэҫЭөДҫЯМеРЕПўЈ¬ҫЯМеКөАэИзПВОДЛщКҫЎЈ
ЈЁ1Ј©өЪ1 МхИХЦҫФЪ2021-08-29 05:28:48 КұҝМ·ўЙъБЛЦч»ъҝӘ·ЕОЈПХ¶ЛҝЪКВјюЈ»
ЈЁ2Ј©өЪ2 өҪ6 МхИХЦҫФЪ2021-09-01 18:39:04ЦБ2021-09-01 21:18:10 ЖЪјдДЪЈ¬·ўЙъБЛUSB ҙжҙўЙиұёҪУИлЈ»
ЈЁ3Ј©өЪ7 өҪ12 МхИХЦҫФЪ2021-09-04 21:26:10ЦБ2021-09-04 21:31:42 ЖЪјдДЪЈ¬·ўЙъБЛКэҫЭНшОЈПХ¶ЛҝЪ·ГОКЈ»
ЈЁ4Ј©өЪ13 өҪ18 МхИХЦҫФЪ2021-09-16 20:47:55 ЦБ2021-09-18 12:11:15 ЖЪјдДЪЈ¬·ўЙъБЛUSB ҙжҙўЙи ұёҪУИлЎўКэҫЭНшОЈПХ¶ЛҝЪ·ГОКЈ»
ЈЁ5Ј©өЪ19 өҪ26 МхИХЦҫФЪ2021-09-23 09:28:47 ЦБ2021-09-24 10:31:09 ЖЪјдДЪЈ¬·ўЙъБЛКэҫЭНшОЈПХ¶ЛҝЪ·ГОКЎўҙ®ҝЪ·ГОКЎЈ
әуРшҪб№ыУлЙПКцГиКцАаРНТ»ЦВЈ¬ҫЯМеДЪИЭІ»ФЩБРіцЎЈ
ҙУҪб№ыҝЙТФҝҙіцЈ¬ЧЫәПK-Means әНDBSCANЛг·ЁөДҪб№ыЈ¬ДЬ№»¶ФФӯКјёжҫҜКэҫЭҪшРРёЯЧѹЛхЈ¬ІўёшіцГҝёцКұјд¶ОДЪҫЯМе·ўЙъөДёжҫҜКВјюАаРНЈ¬ҙуҙуҪөөНБЛФӯКјКэҫЭөДёҙФУ¶ИТФј°ФД¶БДС¶ИЈ¬МбёЯБЛ¶ФУЪёжҫҜКэҫЭ№ШјьРЕПўөДійИЎДЬБҰЎЈ
3.4 Лг·Ё¶ФұИКФСй
ОӘБЛХ№КҫұҫДЈРН¶ФөзНшёжҫҜКэҫЭ·ЦОцҙҰАнөДУЕКЖЈ¬ұҫОДҪшРРБЛK-Means КұјдҫЫАаЕдәПDBSCAN№ШјьЧЦҫЫАаУлҫӯөдDBSCAN ҫЫАаөД¶ФұИКФСйЎЈҙУКэҫЭјҜЦРЛж»ъійИЎБЛТ»ёцөзХҫөДёжҫҜКэҫЭЈ¬№І32 МхЎЈКЧПИФЪСЎИЎәПККөДІОКэә󣬶ԸжҫҜКэҫЭ°ҙХХұҫДЈРНҪшРРK-Means КұјдҫЫАаЕдәПDBSCAN №ШјьЧЦҫЫАаЈ¬КдіцөЪТ»ҙОҫЫАаҪб№ыЈ»ЖдҙОҪ«БҪёцКұјдО¬¶ИјУИлDBSCAN ҫЫАаөДКдИлөұЦРЈ¬СЎИЎУлөЪ1 ҙОҫЫАаПаН¬өДІОКэЈ¬өГөҪөЪ2 ҙОөДҫЫАаҪб№ыЈ¬БҪҙОҫЫАаҪб№ыөДФлЙщВКҪб№ыИзұн2 ЛщКҫЎЈ

ұн2 БҪЦЦЛг·ЁФлЙщВК¶ФұИ
4 ҪбУп
ұҫОДКЧПИҪЁБўБЛөзБҰјаҝШПөНіНшВз°ІИ«КВјюёжҫҜКэҫЭЧЫәП·ЦОцДЈРНЈ»ЖдҙОСЎИЎБЛХжКөөДөзНшёжҫҜКэҫЭҪшРРКөСйЈ»ЧоәуНЁ№э¶ФІ»Н¬АаұрөДёжҫҜКэҫЭҪшРР¶аО¬¶ИҫЫАаҪөО¬Ј¬С°ХТөҪ¶аО¬КэҫЭјдөДНіјЖМШХчЈ¬ЧоЦХНЁ№эС№ЛхВКЎўФлЙщВКј°ЧјИ·ВКөИЦёұк¶ФДЈРНөДҫЫАаР§№ыҪшРРЖАјЫЎЈКөСйҪб№ыұнГчЈ¬ұҫОДЛщҪЁБўөДДЈРНҝЙТФҝмЛЩЧјИ·өШійИЎіцҙуБҝёжҫҜКэҫЭөДНіјЖМШХчЈ¬Іў¶ФКэҫЭҪшРРҪөО¬С№ЛхЈ¬ФЪK-Means өДС№ЛхВКЎўDBSCAN өДФлЙщВКј°БҪХЯҪбәПөДЧјИ·ВКЙП¶јУРҪПәГөДұнПЦЈ¬ҪвҫцБЛПЦУРёжҫҜПөНіКэҫЭФУВТЎў№ШјьРЕПўДСТФМбИЎөИОКМвЈ¬ј«ҙуөШМбёЯБЛөзНшёжҫҜПөНі·ЦОцәНҙҰАнКэҫЭөДДЬБҰЎЈ