倪守娟,颜 艳,初元鸽
(1.青岛民航凯亚系统集成有限公司,山东 青岛 266108;2.青岛国际机场集团有限公司,山东 青岛 266308)
0 引 言
电子信息交互系统指通过电子设备、网络和软件等技术手段,实现人与计算机之间、计算机之间信息传递、数据交换和操作互动的系统[1]。这类系统广泛应用于各个领域,包括但不限于计算机应用、通信、娱乐、商业以及教育等[2]。然而,随着数据量的爆炸性增长和用户需求的多样化,传统的电子信息交互系统面临着诸多挑战[3]。人工智能技术的引入为解决这些问题提供了新的可能性。因此,文章旨在探讨如何利用人工智能技术优化电子信息交互系统的设计,以适应现代信息社会的需求。文章提出一个4层的系统架构设计,包括数据层、处理层、应用层以及交互层,并对每一层的功能和设计要点进行了详细阐述。同时,进行系统测试实验,通过对比不同时间节点的性能数据,证明优化设计的有效性。
1 基于人工智能技术的电子信息交互系统框架设计
电子信息交互系统是当今社会中不可或缺的一部分,而基于人工智能技术的优化设计可以显著提升其性能和用户体验[4]。基于人工智能技术的电子信息交互系统框架设计如图1 所示。
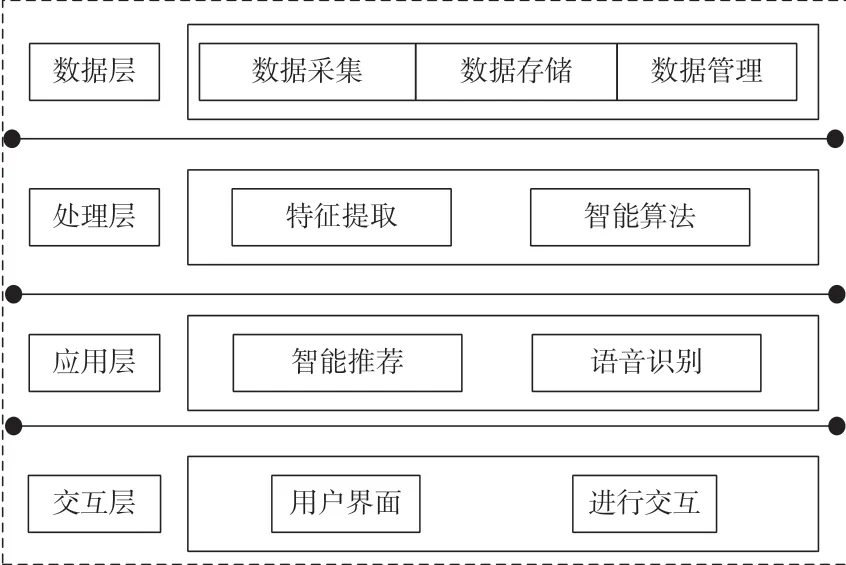
图1 基于人工智能技术的电子信息交互系统框架设计
数据层是系统的基础,负责数据的采集、存储和管理,主要用于确保信息量充足且有序,为系统提供必要的数据支持。数据层的设计和实现直接影响信息的可访问性和后续处理的效率。处理层主要负责对数据进行分析和处理,包括特征提取、智能算法实现等。其主要负责将原始数据转化为有用的信息,支持决策制定和功能实现。处理层的效率和准确性对系统性能至关重要。应用层包含系统的核心功能和服务,其将处理层的结果应用到具体的业务逻辑中。这一层的用处在于将信息转化为用户可以直接利用的服务或功能,如智能推荐、语音识别等。交互层是用户与系统之间的接口,包括用户界面设计和交互流程,能够提供直观、友好的用户界面,确保用户能够轻松地与系统进行交互,提升用户体验。
总的来说,这些层级共同构成了电子信息交互系统的总架构,各层次之间相互协作,确保系统能够高效、稳定地运行,同时提供良好的用户体验。在设计时,需要充分考虑每个层级的特点和需求,以及各层级之间的相互关系,以实现最佳的系统性能和用户体验。
2 系统各模块设计
2.1 数据层
在基于人工智能技术的电子信息交互系统中,数据层设计是至关重要的,负责收集、存储以及管理所有形式的数据,为系统提供必要的数据支持[5]。首先,系统需要确定数据源,包括用户输入、传感器数据、外部数据库等。其次,根据需求设计数据采集策略,实时采集并批量导入数据。采集的数据通常需要经过预处理后才能用于后续的分析。预处理步骤包括数据清洗(去除噪声、纠正错误)、数据转换(将数据转换为适合分析的格式)、数据归一化(将数据缩放到同一范围)等,Z-score 归一化的计算公式为
式中:X'为归一化后的值;X为原始数据点的值;μ为原始数据集的平均值;σ为原始数据集的标准差。Z-score 归一化是一种将数据转换为标准正态分布的方法,其中数据的平均值为0,标准差为1。这种方法在数据预处理中常用于将不同量级或分布的数据转换为统一的尺度,以便在机器学习和数据分析中使用。处理完之后,系统将数据存储在MySQL 数据库中。该数据库支持复杂的查询和事务处理,适合需要执行多表连接、筛选和排序等操作的场景,便于系统制定数据管理策略,包括数据的更新、备份、恢复及安全等。
2.2 处理层
在基于人工智能技术的电子信息交互系统中,处理层设计是关键部分,负责对数据进行分析和处理,以提取有用的信息和知识。系统会根据具体问题和数据类型,选择合适的特征提取方法,包括统计特征、文本特征、图像特征等。特征提取的目的是将原始数据转换为更适合机器学习模型的形式,当特征数量较大时,需要进行数据降维,以提高计算效率,降低过拟合的风险。主成分分析(Principal Component Analysis,PCA)通过求解数据协方差矩阵的特征值和特征向量,选择最大的几个特征值对应的特征向量构成投影矩阵。根据问题类型选择神经网络深度学习模型,在训练过程中,需要优化模型参数以最小化预测误差。交叉熵损失L的计算公式为
式中:yi表示真实标签的概率分布,是一个独热编码(one-hot encoding)的向量,其中正确类别的位置为1,其他位置为0;表示模型预测的概率分布,是经过sigmoid 或softmax 函数转换后的输出,用于表示模型对每个类别的预测概率。交叉熵损失函数是机器学习和深度学习中常用的损失函数之一,用于衡量实际输出与预期输出之间的差异。通过最小化交叉熵损失,可以使模型的预测概率分布尽可能接近真实的概率分布。在分类问题中,交叉熵损失函数通常与sigmoid或softmax 激活函数一起使用,以输出一个概率分布,并通过优化过程调整模型参数,使概率分布尽可能地接近真实分布。之后,使用验证数据集对模型进行评估,以确定模型的性能,根据评估结果对模型进行调整和优化。
2.3 应用层
在基于人工智能技术的电子信息交互系统中,应用层设计是负责将处理层的输出转换为用户可用的服务或功能,具体设计如图2 所示。
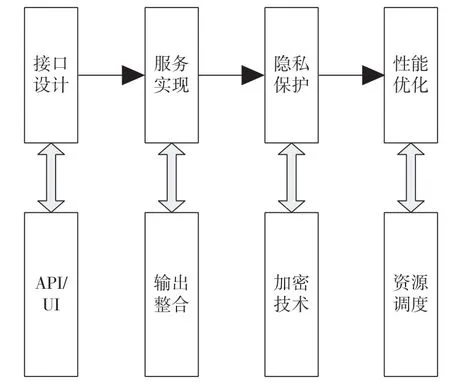
图2 应用层的运行流程
首先,系统优化设计需要明确系统应提供的功能和服务,包括数据查询、智能推荐、自动决策等。其次,根据功能需求,设计系统的用户界面(User Interface,UI)和应用程序接口(Application Programming Interface,API)。UI 设计关注用户体验,API 设计则关注与其他系统或服务的交互。再次,将处理层的输出整合到具体的服务中,可能涉及数据的进一步处理、功能的实现等。为确保系统的数据传输和存储安全,通过高级加密标准(Advanced Encryption Standard,AES)技术保护用户的隐私信息。根据系统的响应时间和资源利用率等指标,对服务进行性能优化。最后,对系统进行全面的测试,包括功能测试、性能测试、安全测试等,然后将系统部署到生产环境。
2.4 交互层
交互层设计是电子信息交互系统框架中的一个关键组成部分,负责用户与系统之间的信息交换。UI设计需要确定UI 的风格和布局,以提供直观、易用的用户体验。设计UI 元素,如按钮、表单、图标等,以实现用户与系统的交互;选择适当的颜色、字体和图像,以提高视觉吸引力和可读性;研究用户需求和行为,以优化UI 的布局和流程;设计交互流程,如导航路径、任务执行顺序等,以提高用户满意度;进行用户测试,以评估和改进用户体验;设计数据展示方式,如图表、列表、仪表板等,以直观地展示系统信息;实现响应式设计,以确保UI 在不同设备和屏幕尺寸上的兼容性;选用超文本传输协议(Hyper Text Transfer Protocol,HTTP)或超文本传输安全协议(Hyper Text Transfer Protocol over Secure Socket Layer,HTTPS),以实现客户端与服务器之间的数据传输;实施数据加密和认证机制,以保护数据的安全性和完整性。
3 测试实验
3.1 实验准备
为测试基于人工智能技术的电子信息交互系统的性能,将构建一个模拟的测试环境。在硬件配置中,服务器型号选择Dell PowerEdge R740,中央处理器型号为Intel Xeon E3-1230 v2,有1 155 个针脚,客户端设备为Lenovo ThinkPad T490,操作系统为Windows 10 Professional 64-bit。软件配置中,操作系统选择Ubuntu Server 20.04 LTS,数据库管理系统为MySQL 8.0.22,人工智能框架采用TensorFlow 2.4.1,服务器软件为Nginx 1.18.0, Gunicorn 20.1.5,客户端软件采用JMeter 5.4.1,用于模拟用户请求。
3.2 实验结果
实验安装并配置所有必要的软件和依赖项,在服务器上部署电子信息交互系统。使用JMeter 设置一个性能测试计划,模拟不同数量的并发用户发送请求。选择5 个不同的运行时间节点,分别为峰值时段(如9:00)、非峰值时段(如15:00)、晚间时段(如21:00)、深夜时段(如第二天1:00)以及周末时段(如第二天10:00)。在每个时间节点运行JMeter测试计划,记录响应速度、处理能力以及传输速率,具体内容如表1 所示。

表1 不同时间节点数据情况
从表1可以看出,在不同时间节点,尽管响应速度、处理能力及传输速率有所波动,但整体保持在较高水平,表明系统在不同运行时间节点均具有较好的稳定性和性能。
4 结 论
文章提出了基于人工智能技术的电子信息交互系统优化设计方案,通过实验验证了其在提升系统性能和稳定性方面的显著效果。优化后的系统不仅能够快速响应用户需求,还能高效处理大量数据,同时保持良好的传输速率。这些改进对于满足现代社会对电子信息交互系统的高标准要求具有重要意义。未来的工作将进一步探索人工智能技术在电子信息交互系统中的新应用,开发更加智能的数据分析工具。此外,随着物联网和边缘计算技术的发展,如何在这些新兴技术框架下整合人工智能,以进一步提高系统的实时性和智能化水平,也是未来研究的重要方向。