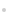ЎҫХӘТӘЎҝОӘБЛЙоИлБЛҪвФЛУӘЙМөДНшВзёІёЗіМ¶ИЈ¬МбЙэНшВзЧКФҙН¶·ЕР§ВКЈ¬НЁ№эMean-ShiftЛг·Ё¶Ф»щХҫөДMRКэҫЭЧцКЧҙОҫЫАа·ЦОцЈ¬ФӨІвіцҫЦІҝЧоУЕөД»щХҫёІёЗЦРРДөгЈ¬ФЩУГDBSCANЛг·ЁФӨІвіцИ«ҫЦЧоУЕөД»щХҫёІёЗЦРРДөгЎЈФЪҙЛ»щҙЎЙП·ЦОцИэҙуФЛУӘЙМ»щХҫРЎЗшФЪөШАнО»ЦГЙПөДІҝКрГЬјҜіМ¶ИЈ¬ҙУ¶ш»сөГГҝёцФЛУӘЙМөДНшВзИИөгЗшУт·ЦІјЈ¬ОӘНшВз№ж»®әНЦЗ»ЫНшУЕМṩȫ·ҪО»өД·ЦОц·Ҫ·ЁЎЈ
Ўҫ№ШјьҙКЎҝMR Mean-Shift DBSCAN ҫЫАаЛг·Ё
doi:10.3969/j.issn.1006-1010.2017.22.001 ЦРНј·ЦАаәЕЈәTP312 ОДПЧұкЦҫВлЈәA ОДХВұаәЕЈә1006-1010(2017)22-0001-04
ТэУГёсКҪЈәМЖЦТБЦ,РнКўәк,М·ЦҫФ¶. »щУЪҙуКэҫЭ¶ФФЛУӘЙМ»щХҫёІёЗЦРРДөгөДФӨІвј°¶ФұИ·ЦОц[J]. ТЖ¶ҜНЁРЕ, 2017,41(22): 1-4.
1 ТэСФ
ЛжЧЕҙуКэҫЭКұҙъөДСёГН·ўХ№Ј¬ИЛГЗ¶ФLBSЈЁLocation Based ServicesЈ¬»щУЪО»ЦГ·юОсЈ©өДРиЗуТІҝмЛЩФціӨЈ¬ОЮПЯ¶ЁО»јјКхЦрІҪөГөҪЦШКУЈ¬О»ЦГ·юОсТСҫӯіЙОӘТ»ЦЦИИГЕөДјјКхЎЈёЁЦъGPSЈЁAGPSЈ©¶ЁО»јјКхҪбәПБЛGPS¶ЁО»әН·дОС»щХҫ¶ЁО»өДУЕКЖЈ¬ҪиЦъ·дОСНшВзөДКэҫЭҙ«Кд№ҰДЬЈ¬ҝЙТФҝмЛЩҫ«ЧјөШ¶ЁО»Ј¬ФЪТЖ¶ҜЙиұёУИЖдКЗКЦ»ъЦХ¶ЛЦРұ»№г·әК№УГ[1]ЎЈФЛУӘЙМНЁ№эёьРВ4GНшВзЦчЙиұёНш№ЬЈ¬јҙРВФцёЁЦъGPSәНТмНшјмІв№ҰДЬЈ¬КөПЦБЛ»щХҫMRЈЁMeasurement ReportЈ¬ІвБҝұЁёжЈ©КэҫЭ°жұҫЙэј¶ЎЈФЪРВөДКэҫЭФҙЦРІ»ҪцДЬ№»»сИЎөҪҫ«И·өДGPSөШАнРЕПўЈ¬Н¬КұТмНшјмІв№ҰДЬТІҝЙТФХл¶ФЖдЛыФЛУӘЙМНшВзёІёЗЗҝ¶ИҪшРРЦЬЖЪІвБҝЈ¬ҙУ¶шҪвҫцБЛөұЗ°MRУҰУГ№эіМЦР¶ЁО»ҫ«¶ИІ»ЧгәНЦ»ДЬЖА№АұҫНшВзёІёЗЗйҝцөДҫЦПЮ[2]ЎЈНЁ№эұҫҙОСРҫҝЈ¬ҝЙТФУРР§НШХ№MRөД·ЦОцДЬБҰЈ¬Хл¶ФИэНшЈЁЦР№ъТЖ¶ҜЎўЦР№ъөзРЕЎўЦР№ъБӘНЁЈ©өДёІёЗЗйҝцҪшРР¶ФұИ·ЦОцЎЈ
ұҫОДНЁ№э¶ФёЁЦъGPSКэҫЭөДНЪҫт·ЦОцЈ¬ФӨІвіцФЛУӘЙМөД»щХҫёІёЗЦРРДөгЈ¬ҝЙТФКөПЦФЛУӘЙМЦ®јдөДНшВзҝЙіЦРш»Ҝ¶ФұИЈ¬ОӘҪвҫцҙ«НіИэНш¶ФұИІвКФСщұҫІ»ідЧгЎў¶ФұИІ»И«ГжөДОКМвМṩһЦЦУРР§Ҫвҫц·Ҫ°ёЎЈ
2 ФЛУӘЙМ»щХҫёІёЗЦРРДөгФӨІв
ТФ»щХҫІЙјҜөҪөДЦХ¶ЛІвБҝұЁёжЧчОӘКэҫЭФҙЈ¬ІўҪ«КэҫЭФҙ°ҙЖөөгәНPCIЈЁPhysical Cell IdentifierЈ¬ОпАнРЎЗшұкК¶Ј©ҪшРР·ЦЧйЈ¬¶Ф·ЦЧйәуөДГҝЧйКэҫЭУГMean-ShiftЈЁЖ«ТЖҫщЦөПтБҝЛг·ЁЈ©Лг·ЁЧцКЧҙОГЬ¶ИҫЫАа[3-4]Ј¬ХТөҪҫЦІҝЧоУЕөД»щХҫёІёЗЦРРДөгЎЈҪбәПЧЁТөөДТөОсұіҫ°ЦӘК¶Ј¬¶ФҫЦІҝ»щХҫёІёЗЦРРДөгУГDBSCANЛг·ЁЧц¶юҙОҫЫАаЈ¬ХТөҪИ«ҫЦЧоУЕөД»щХҫёІёЗЦРРДөг[5-8]ЎЈЧоәуУГұҫНшөДЦчёІёЗРЎЗшАҙСйЦӨЛщФӨІвіцАҙөД»щХҫёІёЗЦРРДөгөДХэИ·РФЎЈҫЯМеБчіМИзНј1ЛщКҫЈә
Нј1 ФЛУӘЙМ»щХҫёІёЗЦРРДөгФӨІвБчіМ
2.1 КэҫЭФҙМбИЎј°ЗеПҙ
ұҫДЈРНІЙУГЦР№ъөзРЕИ«КЎMRөДёЁЦъGPSПа№ШКэҫЭЈ¬ЦчТӘ°ьАЁЈәёчФЛУӘЙМөДЖөөгЎўPCIЎўУГ»§ёцИЛЙПұЁөД°Щ¶ИҫӯОі¶ИЎўөШКРЎўЦР№ъөзРЕЦч·юОсРЎЗш°Щ¶ИҫӯОі¶ИөИКфРФЈ¬Іў¶ФГҝМхјЗВјЦРөДТміЈКэҫЭЎўОЮР§КэҫЭҪшРРБЛЗеПҙЎЈОӘјхЙЩБЪЗшөИёЙИЕТтЛШУ°ПмДЈРНөДЧјИ·¶ИЈ¬ұҫДЈРНЦ»МбИЎБЛКТНвЗТПаҫаЦч·юОсРЎЗш1 kmТФДЪөДMRјЗВјЎЈ
2.2 Mean-ShiftЛг·ЁҫЫАа№эіМ
Mean-ShiftЛг·ЁКЗТ»ёцөьҙъөД№эіМЎЈ¶ФУЪdО¬ҝХјдөДNёцСщұҫөгЈ¬КЧПИЛж»ъСЎФсТ»ёцөгЈ¬ІўТФХвёцөгОӘФІРДЎўТФRОӘ°лҫ¶ЧцТ»ёцdО¬өДёЯО¬ЗтЈ¬ВдФЪХвёцЗтДЪөДЛщУРСщұҫөгәНФІРД¶ј»бІъЙъТ»ёцПтБҝЈ¬ГҝёцПтБҝ¶јТФФІРДОӘЖрөгЎўТФЗтДЪөДСщұҫөгОӘЦХөгЈ¬јЖЛгіцЗтДЪЛщУРПтБҝөДәНЈ¬ЧоЦХөГіцMean-ShiftПтБҝЎЈФЩТФMean-ShiftПтБҝөДЦХөгОӘФІРДЦШёҙЙПКцІҪЦиЎЈУЙН¬ЖрөгПтБҝЗуәН·ЁФтҝЙЦӘЈ¬Mean-shiftПтБҝЧоЦХҪ«КХБІөҪёЕВКГЬ¶ИЧоҙуөДЗшУт[9]ЎЈMean-ShiftПтБҝөД»щұҫРОКҪИзПВЈә

(1)
ЖдЦРЈ¬xОӘҝХјдЦРИОТвТ»өгЈ»DұнКҫФЪNёцСщұҫөгxiЦРУРDёцөгВдФЪSDЗшУтЦРЎЈ
Mean-ShiftЛг·ЁөДОұҙъВлЛјПлИзПВЈә
ЈЁ1Ј©Лж»ъСЎФсТ»өгОӘЦРРДөгЈ¬№М¶ЁТ»ёцҙ°ҝЪЈ¬јЖЛгіцMean-ShiftПтБҝЈ»
ЈЁ2Ј©ЕР¶ПКЗ·сҙпөҪКХБІЈ¬ИфКХБІФтЦХЦ№Ј¬·сФтЦҙРРөЪЈЁ3Ј©ІҪЈ»
ЈЁ3Ј©ТФMean-ShiftПтБҝөДЦХөгОӘРВөДЦРРДЈ¬ЦШёҙЙПКцІҪЦи[10]ЎЈ
УЙУЪ»сИЎөҪөДУГ»§ёЁЦъGPSКэҫЭіКПЦіцОЮ№жВЙ·ЦІјЈ¬ТтҙЛІЙУГ»щУЪёЕВКГЬ¶ИөДMean-ShiftЛг·ЁҪшРРҫЫАа·ЦОцЎЈёГЛг·ЁәцВФБЛКэҫЭФҙЦРөДТміЈЦөЈ¬ГҝҙОЦ»¶Фҙ°ҝЪДЪҫЦІҝКэҫЭҪшРРјЖЛгЈ¬јЖЛгНкіЙәуФЩТЖ¶Ҝҙ°ҝЪЎЈ
ұҫДЈРНКЧПИТФЦР№ъөзРЕөДКэҫЭЧцСөБ·јҜЈ¬ТФЖөөгәНPCIЧчОӘ·ЦЧйМхјюЈ¬·Цұр°СҫЯУРПаН¬ЖөөгәНPCIөДёцИЛЙПұЁ°Щ¶ИҫӯОі¶ИҪшРРҫЫАаЎЈҫӯ№э¶аҙОДЈРНСөБ·ІўҪбәПТөОсКөјКЈ¬ұҫДЈРНЧоЦХЙиЦГөДMean-Shiftҙ°ҝнПөКэОӘ0.02Ј¬ҫЫАаөГөҪ¶аёцН¬Т»ЖөөгәНPCIПВ¶аёц»щХҫёІёЗЦРРДҫӯОі¶ИЎЈФӨІвЦР№ъөзРЕКТНвөД»щХҫёІёЗЦРРДөгУР159 284ёцЈ¬Ҫ«ФӨІвіцАҙөДёІёЗЦРРДөгҫӯОі¶ИУлЦР№ъөзРЕMRКэҫЭұҫЙнМṩөДРЎЗш°Щ¶ИҫӯОі¶ИФЪ°Щ¶ИөШНјЙПЧчҫаАл¶ФұИЎЈҪб№ыұнГчЈ¬¶ФУЪ№гЦЭКРЗшНіјЖіц»щХҫёІёЗЦРРДөгУР80.3%ВдФЪЦчёІёЗРЎЗш¶ФУҰ·ҪПтҪЗёҪҪь150 mТФДЪЈ¬ө«ФЪН¬Т»ЖөөгәНPCIПВУРІҝ·ЦФӨІвөД»щХҫёІёЗЦРРДөгПаҫаҪПҪьЎЈҪбәПЧЁТөөДТөОсЦӘК¶Ј¬ФЛУГЗшУтҫЫАаЛг·ЁDBSCANҪшРР¶юҙОҫЫАаЈ¬Ҫ«КфУЪН¬ЖөөгН¬PCIЗТПаҫаҪПҪьөД»щХҫёІёЗЦРРДөгҫЫОӘТ»ёцРВЦРРДөгЎЈ
2.3 DBSCAN¶юҙОҫЫАа№эіМ
DBSCANКЗТ»ЦЦ»щУЪёЯГЬ¶ИБ¬НЁЗшУтөДҫЫАаЛг·ЁЈ¬ДЬ№»Ҫ«ҫЯУРЧг№»ёЯГЬ¶ИөДЗшУт»®·ЦОӘҙШЎЈёГЛг·ЁРиТӘБҪёцәЛРДөДІОКэЈәТ»ёцІОКэКЗ°лҫ¶Ј¬ұнКҫТФёш¶ЁөгPОӘЦРРДөДФІРОБЪУтөД·¶О§Ј»БнТ»ёцІОКэКЗТФөгPОӘЦРРДөДБЪУтДЪЧоЙЩөгөДКэБҝ[11]ЎЈ
»щУЪұҫДЈРНРиЗуәНЧЁТөөДТөОсЦӘК¶Ј¬ДЈРНЙиЦГөД°лҫ¶ОӘ200 mЈ¬БЪУтДЪЧоЙЩөгКэБҝЙиЦГОӘ1Ј¬ҙУ¶шҝЙТФҪ«ҫЯУРПаН¬ЖөөгәНPCIЗТҫаАлҪПҪьөД»щХҫёІёЗЦРРДөгҫЫАаіЙТ»ёцРВөДЦРРДөгЎЈҪ«»щХҫёІёЗЦРРДөгҫӯОі¶ИУлЦР№ъөзРЕMRКэҫЭМṩөДРЎЗшҫӯОі¶ИЧчҫаАләЛ¶ФЈ¬ёГДЈРНФӨІвіцЦР№ъөзРЕКТНв№ІУР155 244ёц»щХҫёІёЗЦРРДөгЎЈ¶ФУЪ№гЦЭКРЗшНіјЖіц»щХҫёІёЗЦРРДөгУР83.6%ВдФЪЦчёІёЗРЎЗш¶ФУҰ·ҪПтҪЗёҪҪь150 mТФДЪЈ¬·ыәПКөјКТөОс№жФтЎЈ
DBSCANЛг·ЁөДОұҙъВлЛјПлИзПВЈә
ЈЁ1Ј©СЎИЎБЪУт°лҫ¶ОӘ200 mЈ¬БЪУтДЪЧоЙЩөгКэОӘ1Ј»
ЈЁ2Ј©Лж»ъСЎИЎТ»өгОӘЦРРДөгЈ¬јЖЛгПаН¬ЖөөгәНPCIПВөДЦчёІёЗРЎЗшЦРРДөгөДҫаАлЈ¬ИфВъЧгМхјюЈ¬ФтјУИлёГБЪУтЈ¬ІўТФРВјУИлөДөгОӘЦРРДЕР¶ПЖдУаөгКЗ·сВъЧгМхјюЈ¬ЦұөҪұйАъНкЛщУРөгЈ¬јЖЛгіцёГБЪУтРВөДЦРРДөгЈ¬Іў°СКфУЪёГБЪУтөДөгҙУФӯКэҫЭЦРЙҫіэЈ»
ЈЁ3Ј©ҙУКЈУаөДөгЦРЛж»ъСЎИЎТ»өгОӘРВөДЦРРДЈ¬ЦШёҙөЪЈЁ2Ј©ІҪЦұөҪФӯКэҫЭЦРЛщУРөг¶јұ»ЦШРВ№йАаНкұПОӘЦ№ЎЈ
3 ФЛУӘЙМ»щХҫёІёЗЦРРДөг¶ФұИ·ЦОц
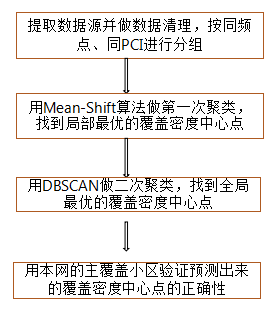
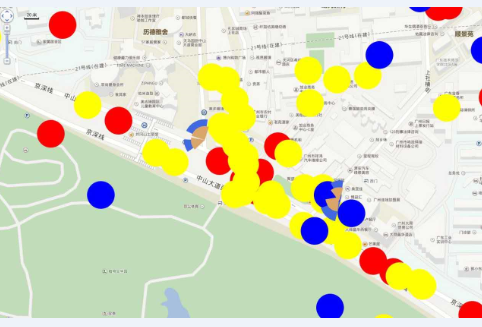
НЁ№эЙПКцДЈРНЈ¬ІЙУГПаН¬өД·Ҫ·ЁҝЙТФФӨІвіцТмНш»щХҫёІёЗЦРРДөгөДО»ЦГј°ЖдКэБҝЈ¬ФӨІвіцФЛУӘЙМAКТНвУР231 948ёц»щХҫёІёЗЦРРДөгЎўФЛУӘЙМBКТНвУР92 668ёц»щХҫёІёЗЦРРДөгЎЈҪ«ИэјТФЛУӘЙМөД»щХҫёІёЗЦРРДөгФӨІвҪб№ыПФКҫФЪ°Щ¶ИөШНјЙПЈ¬ТФ№гЦЭБҪёцЗшУтўсЎўўтОӘАэЈ¬ҫЯМеИзНј2әННј3ЛщКҫЈә
Нј2 ЗшУтўсФЛУӘЙМ»щХҫёІёЗЦРРДөг¶ФұИ

Нј3 ЗшУтўтФЛУӘЙМ»щХҫёІёЗЦРРДөг¶ФұИ
ЖдЦРЈ¬ЙИРОұнКҫФЛУӘЙМХжКөөДЦчёІёЗРЎЗшЛщФЪөДО»ЦГЈ»ФІРОұнКҫУГДЈРНФӨІвіцАҙөД»щХҫёІёЗЦРРДөгЛщФЪөДО»ЦГЈ»»ЖЙ«ұнКҫФЛУӘЙМAЎўА¶Й«ұнКҫФЛУӘЙМBЎўәмЙ«ұнКҫФЛУӘЙМCЎЈ
ҙУНј2әННј3ҝЙТФҝҙіцЈ¬ФӨІвөГөҪөД»щХҫёІёЗЦРРДөгёъХжКөөДРЎЗшПаҫаҪПҪьЈ¬ДЬ№»Цұ№ЫөШГи»жіцИэјТФЛУӘЙМөДёІёЗЗшУтј°ёІёЗГЬ¶ИЎЈНЁ№эХвЦЦЦұ№ЫөДұИҪПЈ¬І»ҪцҝЙТФХЖОХТмНшөДҙуЦВНшВз·ЦІјЈ¬¶шЗТТІТЧУЪБЛҪвДДР©ЗшУтКЗұҫНшГӨЗшЎўДДР©ЗшУтРиТӘјУЗҝёІёЗЈ¬ОӘНшВзҪЁЙи№ж»®әНЦЗ»ЫНшУЕМṩЗҝУРБҰөДЦ§іЕЎЈ
4 ҪбКшУп
ұҫОДНЁ№э¶ФMRКэҫЭөДНЪҫт·ЦОцЈ¬ФӨІвіцФЛУӘЙМөД»щХҫёІёЗЦРРДөгЈ¬ҝЙТФИ«ГжХЖОХФЛУӘЙМЦчёІёЗРЎЗшөДҙуЦВ·ЦІјәНёІёЗГЬ¶ИЈ¬ОӘИ«ГжЖА№АНшВзёІёЗіМ¶ИМṩУРБҰЦ§іЕЈ¬ТІОӘХЖОХТмНшөДНшВз№ж»®әН·ўХ№№жДЈМṩАнВЫТАҫЭЎЈәуРшҪ«¶ФИ«јҜНЕөДMRКэҫЭЧцПаН¬өДНЪҫт·ЦОцЈ¬ОӘИ«јҜНЕөДНшВз№ж»®ЎўЦЗ»ЫНшУЕЎўУЕ»ҜІјҫЦМṩȫ·ҪО»ЦЗДЬ»Ҝ·ЦОц·Ҫ·ЁЈ¬ҪшТ»ІҪМбЙэНшВзЧКФҙН¶·ЕР§ВКЎЈ
ІОҝјОДПЧЈә
[1] Чуі¬,№ўЗмЕф,БхРс·е. »щУЪҙуКэҫЭөДөзРЕТөОс·ўХ№ІЯВФСРҫҝ[J]. УКөзЙијЖјјКх, 2013(10): 1-4.
[2] №Л·ј,БхРс·е,Чуі¬. ҙуКэҫЭұіҫ°ПВФЛУӘЙМТЖ¶Ҝ»ҘБӘНш·ўХ№ІЯВФСРҫҝ[J]. УКөзЙијЖјјКх, 2012(8): 21-24.
[3] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[J]. Knowlegdge Discovety Data Mining, 1996: 226-231.
[4] ЕнДюбФ,СоҪЬ,БхЦҫ,өИ. Mean-ShiftёъЧЩЛг·ЁЦРәЛәҜКэҙ°ҝнөДЧФ¶ҜСЎИЎ[J]. ИнјюС§ұЁ, 2005,16(9): 1542-1550.
[5] әОЦРКӨ,БхЧЪМп,ЧҜСаұх. »щУЪКэҫЭ·ЦЗшөДІўРРDBSCANЛг·Ё[J]. РЎРНОўРНјЖЛг»ъПөНі, 2006,27(1): 114-116.
[6] РЬЦТСф,ЛпЛј,ХЕУс·ј,өИ. Т»ЦЦ»щУЪ»®·ЦөДІ»Н¬ІОКэЦөөДDBSCANЛг·Ё[J]. јЖЛг»ъ№ӨіМУлЙијЖ, 2005(9): 2319-2321.
[7] ИЩЗпЙъ,СХҫэұл,№щ№ъЗҝ. »щУЪDBSCANҫЫАаЛг·ЁөДСРҫҝУлКөПЦ[J]. јЖЛг»ъУҰУГ, 2004,24(4): 45-46.
[8] Нх№рЦҘ. »щУЪГЬ¶ИҫЫАа·ЦОцөДПа№ШЛг·ЁСРҫҝ[J]. өзДФЦӘК¶УлјјКх, 2013(30): 6714-6716.
[9] D Comaniciu, P Meer. Mean shift: a robust approach toward feature space analysis[J]. Journal of Image and Signal Processing, 2002,24(5): 603-619.
[10] RT Collins. Mean-shift blob tracking through scale space[J]. Computer Vision and Pattern Recognition, 2003: 234.
[11] ә«АыоИ,З®С©ЦТ,ВЮҫё,өИ. »щУЪЗшУт»®·ЦөДDBSCAN¶аГЬ¶ИҫЫАаЛг·Ё[J/OL]. [2017-06-14]. http://www.arocmag.com/article/02-2018-06-047.html.Ўп
ЧчХЯјтҪй
МЖЦТБЦЈә№ӨіМКҰЈ¬Л¶КҝұПТөУЪ»ӘДПАн№ӨҙуС§Ј¬ПЦИОЦ°УЪЦР№ъөзРЕ№Й·ЭУРПЮ№«Лҫ№г¶«СРҫҝФәЈ¬ҙУКВҙуКэҫЭНЪҫтЎўЛг·ЁДЈРНөИ№ӨЧчЎЈ
РнКўәкЈә№ӨіМКҰЈ¬С§КҝұПТөУЪЦШЗмУКөзС§ФәЈ¬ПЦИОЦ°УЪЦР№ъөзРЕ№Й·ЭУРПЮ№«Лҫ№г¶«СРҫҝФәЈ¬ҙУКВәЛРДНшСРҫҝј°Ц§іЕ№ӨЧчЎЈ
М·ЦҫФ¶Јә№ӨіМКҰЈ¬С§КҝұПТөУЪ»ӘДПАн№ӨҙуС§Ј¬ПЦИОЦ°УЪЦР№ъөзРЕ№Й·ЭУРПЮ№«Лҫ№г¶«СРҫҝФәЈ¬ҙУКВҙуКэҫЭКэҫЭҝвЎўКэҫЭЖҪМЁ№ЬАнЎўФЖјЖЛгөИјјКхСРҫҝј°Ц§іЕ№ӨЧчЎЈ