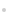0 З°СФ
ЛжЧЕТЖ¶Ҝ»ҘБӘНшКұҙъөДөҪАҙЈ¬ФЪТЖ¶ҜНЁРЕКРіЎЙПЈ¬ДЪІҝ¶шСФЈ¬ёчјТФЛУӘЙМЦ®јдөДІъЖ·УЕКЖПа¶ФУРПЮЈ»НвІҝ¶шСФЈ¬ФЛУӘЙМГжБЩ»ҘБӘНшЖуТөөДіе»чЈ¬¶ФөҘёцУГ»§јЫЦөөДҝӘ·ўК№өГҫәХщёьјУјӨБТЎЈФЪҙжБҝУГ»§К®·ЦУРПЮөДЗйҝцПВЈ¬¶ФУЪФЛУӘЙМ¶шСФЈ¬О¬»ӨёЯјЫЦөАПҝН»§өДН¶ИлұИҝӘ·ўРВУГ»§өДН¶ИлёьДЬУРР§ҪЪКЎЖуТөіЙұҫҝӘЦ§ЎЈөзРЕҝН»§АлНш·ЦОцПа№ШСРҫҝТСҫӯҝӘХ№БЛәЬ¶аДкЈ¬ҙУФзЖЪАыУГКэҫЭҝвҪшРРOLAP·ЦОцЈ¬өҪК№УГКэҫЭНЪҫтЛг·ЁҪшРРУГ»§АлНшФӨІвЎЈХл¶ФАлНшЗгПтөДУГ»§КөК©ҝН»§НмБфЈ¬Х№ҝӘО¬ПөУл№Ш»іЈ¬ТФАыУЪөзРЕЖуТөҝН»§өДұЈіЦЈ¬¶ФФцЗҝөзРЕЖуТөөДЧЫәПҫәХщБҰҫЯУРЦШТӘТвТеЈЫ5-6ЈЭЎЈұҫОДҪйЙЬБЛК№УГҪьДкАҙ»ъЖчС§П°ЦРөДБчРРЛг·ЁАҙ·ЦОцЗұФЪАлНшУГ»§өД·Ҫ·ЁЈ¬әНФзЖЪСРҫҝК№УГөДВЯјӯ»Ш№йЎўҫцІЯКчЈЫ2ЈЭЎўSVMөИ·Ҫ·ЁПаұИЈ¬XGBOOSTККУГУЪ¶ю·ЦАаОКМвЈ¬ІўҫЯУРәЬәГ·ә»ҜДЬБҰЎЈ
1 КэҫЭНЪҫтБчіМ
ІЙУГ»ъЖчС§П°өД·Ҫ·ЁҪшРРКэҫЭНЪҫтЈ¬Т»°гБчіМИзНј1ЛщКҫЎЈ

ЖдЦРіМРтҝӘ·ўәӯёЗЛг·ЁСЎФсЎўЛг·ЁКөПЦәНДЈРНКдіцЎЈУЙУЪДҝЗ°әЬ¶аЛг·ЁТСҫӯКөПЦБЛ№ҰДЬДЈҝй»ҜЈ¬ТтҙЛЈ¬ХвІҝ·ЦЛг·ЁҝЙТФНЁ№эЦұҪУөчУГПЦіЙAPIЈЫ3ЈЭ»тХЯ°ІЧ°№ҰДЬДЈҝйАҙКөПЦЎЈ
2 УГ»§АлНшФӨІвОКМв
ФЪФӨІвАлНшҝН»§өД·ЦОцЦРЈ¬НЁіЈУРјёёц№ШјьІҪЦиЈәОКМв¶ЁТеЎўЛг·ЁСЎФсЎўКэҫЭЧјұёЎўҪб№ыЖА№АЎў·ҙАЎРЮХэЎЈ
ОКМв¶ЁТеЈәФЪөзРЕЖуТөКөјКТөОсЦРЈ¬¶ФҝН»§АлНшАнҪвЧоЙоИлөДКЗёГБмУтөДЧЁјТЈ¬ТтҙЛ¶ФҝН»§БчК§өДЦШТӘТтЛШөДЕР¶ЁҫЯУРЦёөјТвТеЎЈПа№ШАнҪвУҰ°ьАЁЈ¬¶ЁТеКІГҙКЗАлНшЈ¬АлНшУГ»§АаРНУРДДР©ЈЁёЯјЫЦөУГ»§»№КЗЖХНЁУГ»§Ј©Ј¬АлНшУРДДР©РОКҪЈЁКЗЦч¶ҜБчК§Ј¬АэИзУЙУЪҝН»§І»ВъТвөұЗ°·юОс»тҫәХщ¶ФКЦМṩБЛёьУЕЦК·юОс¶шЦч¶ҜНЈЦ№өұЗ°·юОсЈ¬ҪшРРЧӘНшЎўНЛНшЈ¬»№КЗұ»¶ҜБчК§Ј¬АэИзС§ЙъҝН»§ұПТөТмөШ№ӨЧчЈ¬»тҝН»§Ц°ТөЙэЗЁТмөШөч¶ҜөДФӯТтЈ©Ј¬АлНш·ЦОцНЁіЈёь№ШЧўёЯјЫЦөУГ»§өДЦч¶ҜБчК§Ј¬ЛыГЗКЗөзРЕЖуТөАыИуөДЦШТӘАҙФҙЎЈ
Лг·ЁСЎФсЈәИ·¶ЁәГОКМвТФә󣬶ФАлНшУГ»§өД·ЦОцКЗёщҫЭЧјұёК№УГөДЛг·ЁАҙҪшРРҪЁДЈөДЈ¬РиТӘИ·¶ЁФӯКјКэҫЭјҜөДАҙФҙЈ¬ТФј°К№УГЗұФЪАлНшУГ»§өДДДР©Па№ШКфРФЎЈН¬КұЈ¬ФӯКјКэҫЭјҜНЁіЈТІұ»Ір·ЦОӘ2ёцІҝ·ЦЈ¬Т»Іҝ·ЦКЗСөБ·јҜЈ¬УГЧч№№ФмЛг·ЁДЈРНЈ¬БнТ»Іҝ·ЦКЗІвКФјҜЈ¬УГУЪЖА№А·ЦАаЛг·ЁНЁ№эС§П°ЙъіЙөДДЈРНКЗ·сәПАнЎЈБҪХЯөДІр·ЦНЁіЈКЗ°ҙХХ1ЎГ1өДұИАэЈ¬ТІҝЙТФёщҫЭТөОс·ЦОцЧЁјТөДЕР¶ПҪшРРұИАэөДөчХыЎЈ
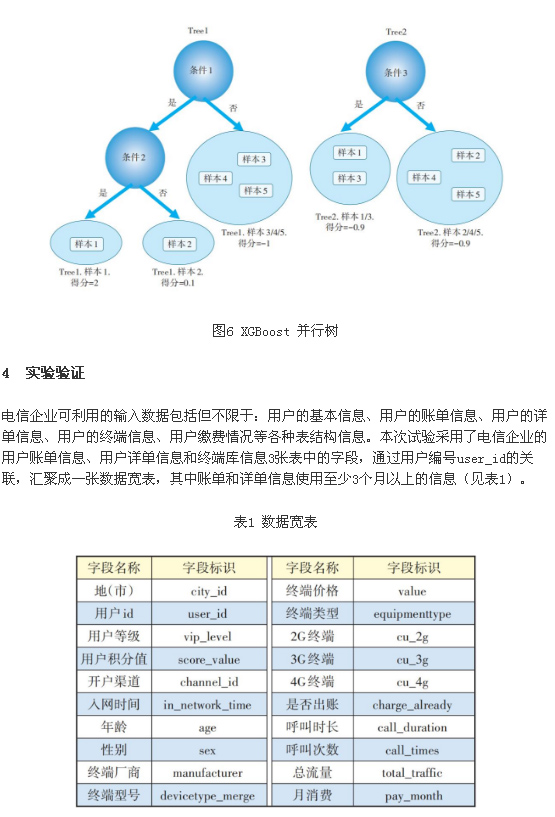
КэҫЭКдИлЈәҫЭНіјЖЈ¬өзРЕЖуТөЖҪҫщГҝФВУР97.5%өДФЪНшҝН»§Ј¬ТФј°2.5%өДАлНшҝН»§Ј¬ТтҙЛФӯКјКэҫЭјҜҙжФЪСПЦШөДұИАэІ»ЖҪәвЎЈБнНвЈ¬өзРЕЖуТөТ»ёцөШЈЁКРЈ©өДУГ»§КэҫЭҫНҙпөҪјёК®НтЙхЦБЙП°ЩНтЈ¬Из№ы¶ФЛщУРКэҫЭҪшРРСөБ·Ј¬КұјдЙПәЬДСВъЧгТӘЗуЎЈІўЗТЈ¬ФӯКјКэҫЭјҜУЙУЪАҙФҙУЪөзРЕЖуТөөДІ»Н¬БмУтәНІҝГЕЈ¬Рн¶аұИҪПЦШТӘөДКфРФЦөҙжФЪИұК§әНҙнОуЈ¬ҪөөНБЛ¶ФЗұФЪУГ»§АлНшөДФӨІвҫ«¶ИЎЈН¬КұЈ¬ТӘҪшРРУГ»§АлНшФӨІвЈ¬РиТӘҪ«ДЬКХјҜөҪөДУГ»§Па№ШКфРФЧйЦҜіЙТ»ХЕұнЈ¬іЖОӘКэҫЭҫЫјҜЈ¬РВЙъіЙөДұніЖОӘКэҫЭҝнұнЈ¬АэИзҪ«УГ»§»щұҫРЕПўЎўіЦУРЦХ¶ЛРЕПўәНФВПы·СРЕПўХыәПОӘТ»ХЕҝнұнЎЈ
Р§№ыЖА№АЈәЛг·ЁКдіцөДДЈРНУГУЪІвКФСщұҫјҜКұЈ¬»мПэҫШХуФј¶ЁЈәTPЈЁTrue PositiveЈ©ЦёХжКөОӘ1Ј¬ФӨІвТІОӘ1Ј»FNЈЁFalse NegativeЈ©ЦёХжКөОӘ0Ј¬ФӨІвОӘ1Ј»FPЈЁFalse PositiveЈ©ЦёХжКөОӘ1Ј¬ФӨІвОӘ0Ј»TNЈЁTrue NegativeЈ©ЦёХжКөОӘ0Ј¬ФӨІвТІОӘ0Ј¬ФтДЈРНР§№ыҝЙНЁ№эТФПВёчПоЦёұк·ҙУіЈЫ4ЈЭЎЈ
ЧјИ·ВК P = TP/ЈЁTP+FPЈ© ЈЁ1Ј©
ХЩ»ШВК R = TP/ЈЁTP+FNЈ© ЈЁ2Ј©
F1-score = 2ЎБPЎБR/ЈЁP+RЈ© ЈЁ3Ј©
3ёцЦёұкУГУЪЧЫәПЖА№АДЈРНР§№ыУЕБУЎЈ
ДЈРНКдіцЈәНЁ№эЦёұкөДЧЫәПЖА¶ЁЈ¬И·¶ЁК№УГ»тұЈБфәОЦЦ»ъЖчС§П°Лг·ЁЈ¬ұЈҙжСөБ·ДЈРНТФ№©өчУГЎЈ
3 »ъЖчС§П°Лг·Ё
»ъЖчС§П°ҙУОЮРтөДКэҫЭЦРНЪҫтУРУГөДРЕПўЈ¬ПБТеөДЦёјЖЛг»ъЎ°С§П°Лг·ЁЎұөДТ»ГЕС§ОКЎЈ№ШјьКхУп°ьАЁЈәМШХчЈЁТІіЖОӘКфРФЈ©ЎўұкК¶ЈЁұкЗ©Ј©ЎўИООсЈЁ·ЦАа»тҫЫАаЎў»Ш№йЈ©ЎўСөБ·СщұҫјҜЎўІвКФСщұҫјҜөИЎЈҝӘ·ў»ъЖчС§П°УҰУГіМРтөД»щұҫІҪЦиНЁіЈ°ьАЁЈЫ1ЈЭЈәКХјҜКэҫЭЎўұкЧј»ҜКдИлКэҫЭЎў·ЦОцКдИлКэҫЭЎўСөБ·ДЈРНЎўІвКФСйЦӨЎўКөјКУҰУГЎЈ»ъЖчС§П°өДДҝөДҫНКЗёш¶ЁКдИлxЈ¬өГөҪФӨІвЦөЈ¬ІўПЈНыФӨІвЦөУлХжКөЦөyЦ®јдөДОуІоҫЎҝЙДЬөДРЎЎЈПВГжҪйЙЬ»ъЖчС§П°өД4ёцҫӯөдНЪҫтЛг·ЁЎЈ
3.1 ВЯјӯ»Ш№й
Па¶ФУЪПЯРФ»Ш№йҙҰАнТтұдБҝКЗБ¬РшұдБҝЈ¬ВЯјӯ»Ш№йДЬёьәГөШККУГУЪТтұдБҝКЗ·ЦАаұдБҝөД»Ш№йОКМвЈ¬іЈјыөДҫНКЗ¶ю·ЦАаОКМвЎЈВЯјӯ»Ш№йөДТтұдБҝәНЧФұдБҝЦ®јдНЁіЈІЙУГSigmoidәҜКэАҙГиКцЈә
ЈЁ4Ј©
ЛьКЗТ»ёцSРОөДЗъПЯЈЁјыНј3Ј©ЎЈ

3.3 Ц§іЦПтБҝ»ъЈЁSVMЈ©·ЦАаЛг·ЁУләЛәҜКэ
SVMКЗ»ъЖчС§П°ЦРөДУРја¶ҪПЯРФ·ЦАаЛг·ЁЈ¬ЧоіхХэКҪ·ўұнУЪ1995ДкЎЈSVMУҰУГФЪОДұҫ·ЦАаУИЖдКЗХл¶Ф¶ю·ЦАаИООсПФКҫіцЧҝФҪөДРФДЬЈ¬ТтҙЛөГөҪБЛ№г·әөДСРҫҝәНУҰУГЈ¬әуЖЪФЪ¶а·ЦАаИООсТІҪшРРБЛЧЁГЕНЖ№гЎЈSVMНЁ№эПтёЯО¬¶ИҝХјдУіЙдАҙҪвҫц¶аО¬ПЯРФІ»ҝЙ·ЦОКМвЈ¬К№СщұҫПЯРФҝЙ·ЦЎЈИзНј5ЛщКҫЈ¬ҝЙҪ«Т»О¬І»ҝЙ·ЦОКМвЧӘ»ҜОӘ¶юО¬ҝЙ·ЦОКМвЈЫ7ЈЭЎЈәЛәҜКэСЎФсКЗSVMЦРРФДЬІоұрөДЧоҙуФӯТтЎЈәЛәҜКэСЎФсІ»әПККЈ¬ТвО¶ЧЕСщұҫұ»УіЙдөҪБЛІ»әПККөДМШХчҝХјдЈ¬әЬҝЙДЬөјЦВРФДЬІ»јСЎЈ
3.4 XGBoost
XGBoostЈЁeXtreme Gradient BoostingЈ©ІЙУГБЛ»Ш№йКчәНјҜіЙBoosting 2ЦЦјјКхЎЈФЪКэҫЭҪЁДЈЦРЈ¬өұОТГЗУРКэёцБ¬РшЦөМШХчКұЈ¬ҫӯіЈІЙУГBoosting·ЦАаЖчҪ«іЙ°ЩЙПЗ§ёц·ЦАаЧјИ·ВКҪПөНөДКчДЈРНЧйәПЖрАҙЈ¬РОіЙТ»ёцЧјИ·ВКәЬёЯөДФӨІвДЈРНЎЈXGBҝЙТФАнҪвОӘ¶аёцКчөДІўРРФӨІвЈ¬ІўҪ«ФӨІв·ЦЦөПајУУГУЪАаұрЕР¶ПЎЈХвёцКчДЈРНҫӯ№эІ»¶ПөШөьҙъЈ¬ФЪГҝҙОөьҙъҫНЙъіЙТ»ҝГРВөДКчЈ¬ҙУ¶шК№ФӨІвЦөІ»¶ПұЖҪьХжКөЦөЈЁјҙҪшТ»ІҪЧоРЎ»ҜДҝұкәҜКэЈ©ЎЈ
XGBoostөДІўРРКчИзНј6ЛщКҫЈ¬ТФСщұҫ1ОӘАэЈ¬ФӨІвөГ·ЦОӘЈәTree1.Сщұҫ1.өГ·ЦЈЁ2Ј©+ Tree2.Сщұҫ1.өГ·ЦЈЁ0.9Ј©=2.9Ј¬ПаұИУЪСщұҫ2өД-0.8Ј¬Сщұҫ3өД-0.1Ј¬Сщұҫ4Ўў5өД-1.9Ј¬ҫЯУРёьҙуөДФӨІвёЕВКЎЈЧўТвөҪЈ¬УЙУЪXGBoostіцЦЪөДР§ВКУлҪПёЯөДФӨІвЧјИ·¶ИФЪ»ъЖчС§П°БмУтТэЖрБЛ№г·ә№ШЧўЎЈ
ОӘБЛФцјУДЈРНөДУРР§РФЈ¬ҝЙТФНЁ№эөҘёцЛг·ЁөДІвКФТФј°ИЪәП¶аёцЛг·ЁөДІвКФЈ¬АэИзҝЙТФФЪКөјщУҰУГКұЈ¬өЪ1ҙОІЙУГВЯјӯ»Ш№йЛг·ЁҪЁДЈәНФӨІвЈ¬өЪ2ҙОІЙУГҫцІЯКчЛг·ЁЈ¬өЪ3ҙОІЙУГXGBoostЛг·ЁЈ¬өЪ4ҙОІЙУГҪ«ВЯјӯ»Ш№йәНXGBoostЛг·ЁөДҪб№ыәПІўөДФӨІв·Ҫ·ЁЎЈІЙУГXGBoostЛг·ЁҪЁДЈөДКөСйОұҙъВлИзПВЎЈ
өЪ1ІҪЈә
#өјИлxgboostДЈҝйЈә
import xgboost as xgb
өЪ2ІҪЈә
#¶БИЎСөБ·КфРФЈ¬ОӘҪЁДЈЧјұёКдИлКэҫЭЈәУГ»§АлНшФӨІвКЗТ»ёцөдРНөДУРја¶Ҫ·ЦАаОКМвЎЈТтҙЛРиТӘ¶БИлСөБ·МШХчЈ¬ТФј°ДҝұкұкК¶Јә
feature_file_name = "train.feat"
target_file_name = "train.target"
feature_file = openЈЁfeature_file_nameЈ¬'rt'Ј©
target_file = openЈЁtarget_file_nameЈ¬'rt'Ј©
#ЧјұёҫШХуРНСөБ·КэҫЭЈә
#¶БРҙСщұҫМШХчЈ¬ЙъіЙСөБ·ҫШХуtraining_matrixәНДҝұкБРұнtarget_listЎЈ
өЪ3ІҪЈә
#ЙъіЙСөБ·ДЈРНЈ¬ФЪІвКФјҜЙПСйЦӨІўөчІОЎЈ
param = {'booster'Јә'gbtree'Ј¬'objective'Јә'binaryЈәlogistic'Ј¬'eval_metric'Јә'auc'Ј¬'max_depth'Јә5Ј¬'min_child_weight'Јә1Ј¬'subsample'Јә0.9Ј¬'lambda'Јә10Ј¬'gamma'Јә0.0Ј¬'eta'Јә0.3Ј¬'silent'Јә1 }
num_round = 100
dtrain=xgb.DMatrixЈЁtraining_matrixЈ¬label=target_listЈ©
bst = xgb.trainЈЁparamЈ¬dtrainЈ¬num_roundЈ©
bst.save_modelЈЁ'model.xgb'Ј©
өЪ4ІҪЈә
#К№УГј°УҰУГЎЈҪ«ЙъіЙөДxgbДЈРНУГУЪРиТӘЙъіЙұкЗ©өДСщұҫјҜЎЈ
#јУФШСщұҫКфРФКэҫЭ
#јУФШСөБ·ДЈРНКэҫЭ
bst = xgb.BoosterЈЁ{'nthread'Јә4}Ј©
bst.load_modelЈЁ"model.xgb"Ј©
#ФӨІв
dtest = xgb.DMatrixЈЁtrainingMatrixЈ©
y_pred = bst.predictЈЁdtestЈ©
result_list = ЈЁy_pred ЎЭ 0.5Ј© ЎБ 1
#Ҫб№ыРҙИлОДјю
result_file = openЈЁresult_file_nameЈ¬'wt'Ј©
for index in rangeЈЁlenЈЁy_predЈ©Ј©Јә
result_file.writeЈЁ'%s/t%d/n'%ЈЁuid_listЈЫindexЈЭЈ¬result_listЈЫindexЈЭЈ©Ј©
result_file.closeЈЁЈ©
өЪ5ІҪЈә
#Из№ыІЙУГ¶аЛг·ЁИЪәПЈ¬АэИзіэXGBoostЦ®НвН¬КұІЙУГВЯјӯ»Ш№йөДЕРҫцёЕВКЈ¬ҝЙҪ«XGBoostКдіцЕРҫцёЕВКәНВЯјӯ»Ш№йКдіцЕРҫцёЕВКИЎҫщЦөЈ¬ЧчОӘЧоЦХЕРҫцТАҫЭЎЈ
bst = xgb.BoosterЈЁ{'nthread'Јә4}Ј©
bst.load_modelЈЁ"model.xgb"Ј©
pred_leaves = bst.predictЈЁxgb.DMatrixЈЁtest_matrixЈ©Ј¬pred_leaf=TrueЈ©
tree_node_enc = OneHotEncoderЈЁЈ©
lr_model = LogisticRegressionЈЁЈ©
ЎӯЎӯ
transformed_feature = tree_node_enc.transformЈЁpred_leavesЈ©.toarrayЈЁЈ©
y_pred = lr_model.predict_probaЈЁtransformed_featureЈ©ЈЫЈәЈ¬1ЈЭ
result_list = ЈЁy_pred ЎЭ 0.5Ј© ЎБ 1
5 ЧЬҪб
К№УГ»ъЖчС§П°АҙФӨІвУГ»§АлНшЈ¬КЗҙуКэҫЭПа№ШјјКхФЪөзРЕЖуТөөДТ»ёцөдРНУҰУГЈЫ8-11ЈЭЎЈ»ъЖчС§П°ФЪПЦҙъөДУҰУГТСҫӯПаөұ№г·әЈ¬УГ»§ҝЙТФІ»ұШФЩҝӘ·ўЧоФӯКјөДЛг·ЁҙъВлЈ¬¶шКЗЦұҪУ°ІЧ°ЎўөчУГПЦіЙөДДЈҝй»тХЯAPIЎЈөзРЕЖуТөөДКэҫЭЧКІъКЗұҰ№уөДҝуІШЈ¬НЁ№эКэҫЭНЪҫтЈ¬ОЮВЫКЗУГУЪМбЙэЖуТөДЪІҝФЛУӘР§ВКЈ¬»№КЗәННвІҝәПЧчҪшРРРРТөУҰУГЦ§іЕЈ¬¶јҪ«КЗТ»ұК·ЗіЈҝЙ№ЫөДІЖё»ЎЈ
ІОҝјОДПЧЈә
ЈЫ1ЈЭ HARRINGTON P.»ъЖчС§П°КөХҪЈЫMЈЭ.АоИсЈ¬АоЕфЈ¬ЗъСЗ¶«Ј¬өИЈ¬Тл.ұұҫ©ЈәИЛГсУКөзіц°жЙзЈ¬2013
ЈЫ2ЈЭ Нхҝӯ. КэҫЭНЪҫтФЪТЖ¶ҜАлНшУГ»§·ЦОцДЈРНЦРөДСРҫҝУлУҰУГЈЫDЈЭ. ЦЈЦЭЈәЦЈЦЭҙуС§Ј¬2014.
ЈЫ3ЈЭ іВҝөЈ¬ПтУВЈ¬Учі¬.ҙуКэҫЭКұҙъ»ъЖчС§П°өДРВЗчКЖЈЫJЈЭ.өзРЕҝЖС§Ј¬2012Ј¬28ЈЁ12Ј©Јә88-95.
ЈЫ4ЈЭ ЦЬЦҫ»ӘЈ¬Нхзе. »ъЖчС§П°ј°ЖдУҰУГЈЫMЈЭ. ұұҫ©ЈәЗе»ӘҙуС§іц°жЙзЈ¬2009.
ЈЫ5ЈЭ HASSOUNA MЈ¬TARHINI AЈ¬ELYAS TЈ¬et al. Customer Churn in Mobile Markets A Comparison of TechniquesЈЫJЈЭ. International Business ResearchЈ¬2015Ј¬8ЈЁ6Ј©Јә224-237.
ЈЫ6ЈЭ SINGH IЈ¬SINGH S. Framework for Targeting High Value Customers and Potential Churn Customers in Telecom using Big Data AnalyticsЈЫJЈЭ. International Journal of Education & Management EngineeringЈ¬2017Ј¬7ЈЁ1Ј©Јә36-45.
ЈЫ7ЈЭ DONG RЈ¬SU FЈ¬YANG SЈ¬et al. Customer Churn Analysis for Telecom Operators Based on SVMЈЫCЈЭ// International Conference On Signal And Information ProcessingЈ¬Networking And Computers. SpringerЈ¬SingaporeЈ¬2017Јә327-333.
ЈЫ8ЈЭ ХЕжәжҜ. өзРЕЙз»бНшВзАлНшУГ»§ФӨІвј°·ЦОцЈЫDЈЭ. ұұҫ©Јәұұҫ©УКөзҙуС§Ј¬2017.
ЈЫ9ЈЭ іВкК. »щУЪЧйәПФӨІвөДөзРЕҝН»§БчК§ФӨІв·ЦОцЈЫDЈЭ.іӨЙіЈәәюДПҙуС§Ј¬2011.
ЈЫ10ЈЭ СоПю·еЈ¬СПҪЁ·еЈ¬БхПюЙэЈ¬өИ.Йо¶ИЛж»ъЙӯБЦФЪАлНшФӨІвЦРөДУҰУГЈЫJЈЭ.јЖЛг»ъҝЖС§Ј¬2016Ј¬43ЈЁ6Ј©Јә208-213.
ЈЫ11ЈЭ ХФ»ЫЈ¬БхУұ»ЫЈ¬ҙЮУр·ЙЈ¬өИ.»ъЖчС§П°ФЪФЛУӘЙМУГ»§БчК§ФӨҫҜЦРөДФЛУГЈЫJЈЭ.РЕПўНЁРЕјјКхЈ¬2018Ј¬12ЈЁ1Ј©Јә14-21.