ұіҫ°
ЙзҪ»ГҪМеЖҪМЁКЗ·ЦПнУРИӨөДНјПсөДіЈУГ·ҪКҪЎЈКіОпНјПсЈ¬УИЖдКЗУлІ»Н¬өДГАКіәНОД»ҜПа№ШөДНјПсЈ¬КЗТ»ёцЛЖәхҫӯіЈБчРРөД»°МвЎЈInstagram өИЙзҪ»ГҪМеЖҪМЁУөУРҙуБҝКфУЪІ»Н¬АаұрөДНјПсЎЈОТГЗ¶јҝЙДЬК№УГ№ИёиНјЖ¬»т Instagram ЙПөДЛСЛчСЎПоАҙдҜААҝҙЖрАҙәЬГАО¶өДө°ёвНјЖ¬АҙС°ХТБйёРЎЈө«КЗОӘБЛИГХвР©НјЖ¬ҝЙТФНЁ№эЛСЛч»сөГЈ¬ОТГЗРиТӘОӘГҝХЕНјЖ¬ЙиЦГТ»Р©Па№ШөДұкЗ©ЎЈ
ХвК№өГЛСЛч№ШјьЧЦІўҪ«ЖдУлұкЗ©ЖҘЕдіЙОӘҝЙДЬЎЈУЙУЪКЦ¶ҜұкјЗГҝХЕНјПсј«ҫЯМфХҪРФЈ¬ТтҙЛ№«ЛҫК№УГ ML ЈЁ»ъЖчС§П°Ј©әН DL ЈЁЙо¶ИС§П°Ј©јјКхОӘНјПсЙъіЙХэИ·өДұкЗ©ЎЈХвҝЙТФК№УГ»щУЪТ»Р©ұкјЗКэҫЭК¶ұрәНұкјЗНјПсөДНјПс·ЦАаЖчАҙКөПЦЎЈ
ФЪұҫОДЦРЈ¬ИГОТГЗК№УГ fastai №№ҪЁТ»ёцНјПс·ЦАаЖчЈ¬ІўК№УГТ»ёцГыОӘЎ° fastaiЎұөДҝвАҙК¶ұрТ»Р©КіОпНјПсЎЈ
Fastai јтҪй
Fastai КЗТ»ёцҝӘФҙЙо¶ИС§П°ҝвЈ¬ЛьОӘҙУТөХЯМṩёЯј¶ЧйјюЈ¬ҝЙТФҝмЛЩЗбЛЙөШФЪҙ«НіЙо¶ИС§П°БмУтІъЙъЧоПИҪшөДҪб№ыЎЈЛьК№СРҫҝИЛФұҝЙТФ»мәПәНЧйәПөНј¶ЧйјюТФҙҙҪЁРВјјКхЎЈЛьЦјФЪФЪІ»У°ПмҝЙУГРФЎўБй»оРФ»тРФДЬөДЗйҝцПВКөПЦХвБҪёцДҝұкЎЈ
УЙУЪ fastai КЗУГ Python ұаРҙөДЈ¬ІўЗТ»щУЪ PyTorchЈ¬ТтҙЛРиТӘ Python ЦӘК¶ІЕДЬАнҪвұҫОДЎЈОТГЗҪ«ФЪ Google Colab ЦРФЛРРҙЛҙъВлЎЈіэБЛ fastaiЈ¬ОТГЗҪ«К№УГНјРОҙҰАнөҘФӘ ЈЁGPUЈ© ТФҫЎҝЙДЬҝмөШ»сөГҪб№ыЎЈ
К№УГ Fastai №№ҪЁНјПс·ЦАаЖч
ИГОТГЗҙУ°ІЧ° fastai ҝвҝӘКјЈә
ЈЎpip install ЈӯUqq fastai
Из№ыДгК№УГөДКЗ AnacondaЈ¬ЗлФЛРРТФПВГьБоЈә
conda install Јӯc fastchan fastai anaconda
ИГОТГЗөјИл·ЦАаИООсЛщРиөД°ьЎЈёГҝв·ЦОӘДЈҝйЈ¬ЖдЦРЧоіЈјыөДКЗұнёсЎўОДұҫәНКУҫхЎЈТтОӘОТГЗКЦН·өДИООс°ьАЁКУҫхЈ¬ЛщТФОТГЗҙУvisionҝвЦРөјИлОТГЗРиТӘөДЛщУР№ҰДЬЎЈ
from fastaiЈ®visionЈ®all import ЈӘ
НЁ№э fastai ҝвҝЙТФ»сөГРн¶аС§КхКэҫЭјҜЎЈЖдЦРЦ®Т»КЗ FOODЈ¬ЛьКЗ URL ПВөДURLsЈ® FOOD
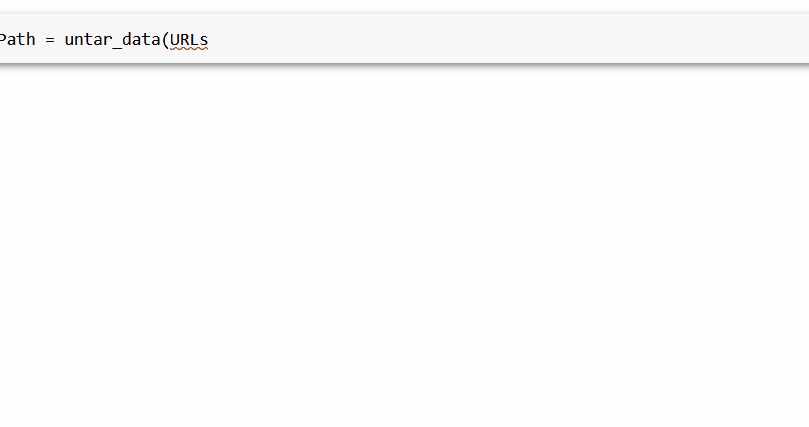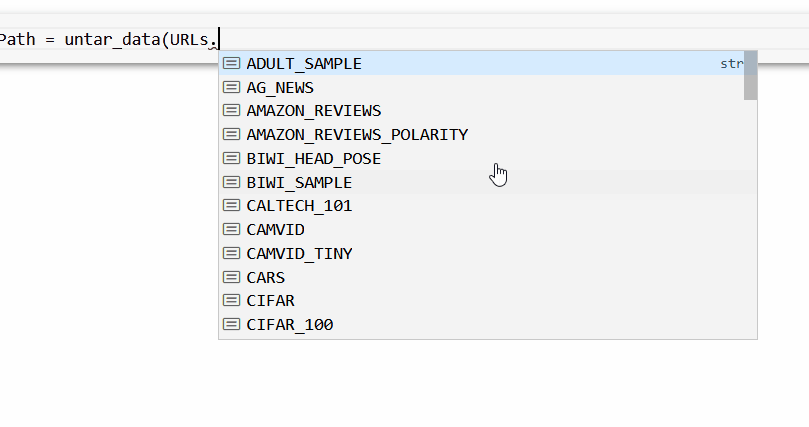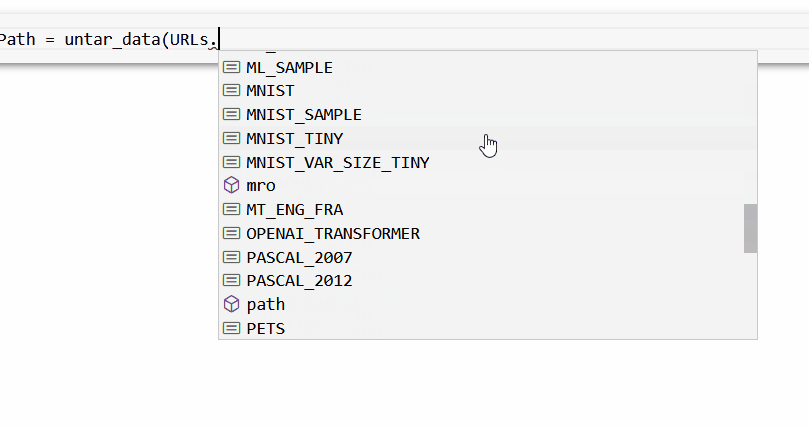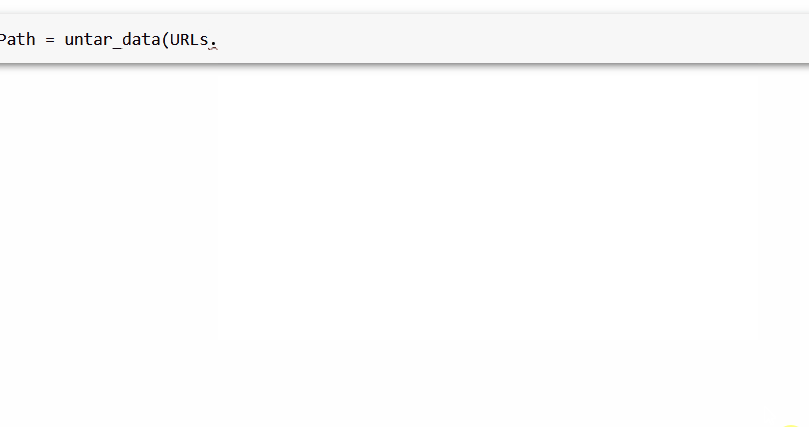
өЪТ»ІҪКЗ»сИЎІўМбИЎОТГЗРиТӘөДКэҫЭЎЈОТГЗҪ«К№УГ untarЈЯdata әҜКэЈ¬Ль»бЧФ¶ҜПВФШКэҫЭјҜІўҪвС№ЛьЎЈ
foodPath ЈҪ untarЈЯdataЈЁURLsЈ®FOODЈ©
ёГКэҫЭјҜ°ьә¬ 101Ј¬000 ХЕНјПсЈ¬·ЦОӘ 101 ёцКіОпАаұрЈ¬ГҝёцАаұрУР 250 ёцІвКФНјПсәН 750 ёцСөБ·НјПсЎЈСөБ·ЦРөДНјПсГ»УРұ»ЗеАнЎЈЛщУРНјПсөДҙуРЎ¶јөчХыОӘГҝұЯЧоҙу 512 ПсЛШЎЈ
ПВТ»ёцГьБоҪ«ёжЛЯОТГЗұШРлҙҰАн¶аЙЩНјПсЎЈ
lenЈЁgetЈЯimageЈЯfilesЈЁfoodPathЈ©Ј©
ҙЛНвЈ¬К№УГТФПВГьБоЈ¬ОТГЗҪ«ҙтУЎ Food КэҫЭјҜөДФӘДҝВјөДДЪИЭЎЈ
printЈЁosЈ®listdirЈЁfoodPathЈ©Ј©
metaОДјюјР°ьә¬°ЛёцОДјюЈ¬ЖдЦРЛДёцКЗОДұҫОДјюЈәtrainЈ®txtЎўtestЈ®txtЎўclassesЈ®txtәНlabelsЈ®txtЎЈtrainЈ®txt әН testЈ®txt ОДјю·Цұр°ьә¬СөБ·јҜәНІвКФјҜөДНјПсБРұнЎЈclassesЈ®txt ОДјю°ьә¬ЛщУРКіЖ·АаұрәНұкЗ©өДБРұнЎЈtxt МṩБЛЛщУРКіЖ·НјПсұкЗ©өДБРұнЎЈёГДҝВј»№°ьә¬Т»ёцҙшУРФӨСөБ·ДЈРНөД Ј®h5 ОДјюәНТ»ёц°ьә¬ 101Ј¬000 ХЕ JPG ёсКҪНјПсөДНјПсОДјюјРЎЈЧоәуЈ¬СөБ·јҜәНІвКФјҜТФ JSON ёсКҪМṩЎЈ
ТӘІйҝҙЛщУРНјПсАаұрЈ¬ОТГЗҪ«ФЛРРТФПВГьБоЈә
imageЈЯdirЈЯpath ЈҪ foodPathЈҜЈ§imagesЈ§
imageЈЯcategories ЈҪ osЈ®listdirЈЁimageЈЯdirЈЯpathЈ©
printЈЁimageЈЯcategoriesЈ©
И»әуЈ¬ОТГЗҪ«ЦҙРРТФПВГьБоТФІйҝҙ 101Ј¬000 ХЕНјПсјҜәПЦРөДКҫАэНјПсЎЈ
img ЈҪ PILImageЈ®createЈЁЈ§ЈҜrootЈҜЈ®fastaiЈҜdataЈҜfoodЈӯ101ЈҜimagesЈҜfrozenЈЯyogurtЈҜ1942235Ј®jpgЈ§Ј©
imgЈ®showЈЁЈ©Ј»

ОТГЗҪ«К№УГ pandas әҜКэ¶БИЎ JSON ёсКҪөДСөБ·әНІвКФОДјюЎЈJSON КЗТ»ЦЦТФИЛАаҝЙ¶БөДРОКҪҙжҙўРЕПўөДКэҫЭёсКҪЎЈ
ТФПВҙъВлҙУДҝВјЦР¶БИЎ trainЈ®json ОДјюІўҪ«Ҫб№ыұЈҙжФЪ dfЈЯtrain КэҫЭЦЎЦРЎЈ
dfЈЯtrainЈҪpdЈ®readЈЯjsonЈЁЈ§ЈҜrootЈҜЈ®fastaiЈҜdataЈҜfoodЈӯ101ЈҜtrainЈ®jsonЈ§Ј©
И»әуҝЙТФК№УГ headЈЁЈ© әҜКэҙтУЎКэҫЭЦЎөДұкМвЈ¬ИзПВЛщКҫЎЈ
dfЈЯtrainЈ®headЈЁЈ©

Н¬СщЈ¬НЁ№эК№УГ pandas әҜКэЈ¬ОТГЗҪ«¶БИЎ testЈ®json ОДјюІўҪ«ЖдҙжҙўФЪ dfЈЯtest КэҫЭЦЎЦРЎЈ
dfЈЯtestЈҪpdЈ®readЈЯjsonЈЁЈ§ЈҜrootЈҜЈ®fastaiЈҜdataЈҜfoodЈӯ101ЈҜtestЈ®jsonЈ§Ј©
dfЈЯtestЈ®headЈЁЈ©
ОТГЗХэФЪҙҙҪЁИэёцҙшУРОТГЗСЎФсөДКіОпГыіЖөДұкЗ©Аҙ¶ФКіОпНјПсҪшРР·ЦАаЎЈ
labelA ЈҪ Ј§cheesecakeЈ§
labelB ЈҪ Ј§donutsЈ§
labelCЈҪ Ј§pannaЈЯcottaЈ§
ПЦФЪОТГЗҪ«ҙҙҪЁТ»ёц for Сӯ»·Ј¬ЛьҪ«ұйАъОТГЗПВФШөДЛщУРНјПсЎЈФЪҙЛСӯ»·өД°пЦъПВЈ¬ОТГЗҪ«ЙҫіэГ»УРұкЗ© AЎўB »т C өДНјПсЎЈҙЛНвЈ¬ОТГЗК№УГТФПВәҜКэЦШГьГыҫЯУРёчЧФұкЗ©өДНјПсЎЈ
for img in getЈЯimageЈЯfilesЈЁfoodPathЈ©Јә
if labelA in strЈЁimgЈ©Јә
imgЈ®renameЈЁfЈўЈыimgЈ®parentЈэЈҜЈыlabelAЈэЈӯЈыimgЈ®nameЈэЈўЈ©
elif labelB in strЈЁimgЈ©Јә
imgЈ®renameЈЁfЈўЈыimgЈ®parentЈэЈҜЈыlabelBЈэЈӯЈыimgЈ®nameЈэЈўЈ©
elif labelC in strЈЁimgЈ©Јә
imgЈ®renameЈЁfЈўЈыimgЈ®parentЈэЈҜЈыlabelCЈэЈӯЈыimgЈ®nameЈэЈўЈ©
elseЈә osЈ®removeЈЁimgЈ©
ИГОТГЗК№УГТФПВГьБојмІйФЛРРСӯ»·әу»сөГөДНјПсКэБҝЈә
lenЈЁgetЈЯimageЈЯfilesЈЁfoodPathЈ©Ј©
ИГОТГЗФЪИэёцСЎФсөДКіОпЦРіўКФТ»ёцКҫАэұкЗ©Ј¬ҝҙҝҙЦШГьГыКЗ·сХэИ·ЎЈ
def GetLabelЈЁfileNameЈ©Јә
return fileNameЈ®splitЈЁЈ§ЈӯЈ§Ј©ЈЫ0ЈЭ
GetLabelЈЁЈўcheesecakeЈӯ1092082Ј®jpgЈўЈ©
ТФПВҙъВлЙъіЙТ»ёц DataLoaders ¶ФПуЈ¬ёГ¶ФПуұнКҫСөБ·әНСйЦӨКэҫЭөД»мәПЎЈ
dls ЈҪ ImageDataLoadersЈ®fromЈЯnameЈЯfuncЈЁ
foodPathЈ¬ getЈЯimageЈЯfilesЈЁfoodPathЈ©Ј¬ validЈЯpctЈҪ0Ј®2Ј¬ seedЈҪ42Ј¬
labelЈЯfuncЈҪGetLabelЈ¬ itemЈЯtfmsЈҪResizeЈЁ224Ј©Ј©
dlsЈ®trainЈ®showЈЯbatchЈЁЈ©

ФЪХвЦЦЗйҝцПВЈ¬ОТГЗҪ«Јә
ЎӨ К№УГВ·ҫ¶СЎПоЦё¶ЁПВФШәНМбИЎКэҫЭөДО»ЦГЎЈ
ЎӨ К№УГ getЈЯimageЈЯ files әҜКэҙУЦё¶ЁО»ЦГКХјҜЛщУРОДјюГыЎЈ
ЎӨ ¶ФКэҫЭјҜК№УГ 80ЁC20 Ір·ЦЎЈ
ЎӨ К№УГ GetLabel әҜКэҙУОДјюГыЦРМбИЎұкЗ©ЎЈ
ЎӨ Ҫ«ЛщУРНјПсөчХыОӘПаН¬ҙуРЎЈ¬јҙ 224 ПсЛШЎЈ
ЎӨ К№УГ showЈЯbatch әҜКэЙъіЙТ»ёцКдіцҙ°ҝЪЈ¬ПФКҫҙшУРЦё¶ЁұкЗ©өДСөБ·НјПсНшёсЎЈ
КЗКұәтҪ«ДЈРН·ЕЦГөҪО»БЛЎЈК№УГ ResNet34 јЬ№№Ј¬ОТГЗҪ«НЁ№эЧЁЧўУЪіЖОӘ visionЈЯlearner ЈЁЈ© өДөҘёцәҜКэөчУГАҙ№№ҪЁҫн»эЙсҫӯНшВзЎЈ
visionЈЯlearner әҜКэЈЁТІіЖОӘ cnnЈЯlearnerЈ©УРАыУЪСөБ·јЖЛг»ъКУҫхДЈРНЎЈЛь°ьАЁДгөДФӯКјНјПсКэҫЭјҜЎўФӨСөБ·ДЈРН resnet34 әНТ»ёц¶ИБҝҙнОуВКЈ¬Льҫц¶ЁБЛФЪСйЦӨКэҫЭЦРҙнОуК¶ұрөДНјПсөДұИАэЎЈresnet34 ЦРөД 34 ЦёөДКЗХвЦЦјЬ№№АаРНЦРөДІгКэЈЁЖдЛыСЎПоУР 18Ўў50Ўў101 әН 152Ј©ЎЈК№УГёь¶аІгөДДЈРНРиТӘёьіӨөДСөБ·КұјдІўЗТёьИЭТЧ№э¶ИДвәПЎЈ
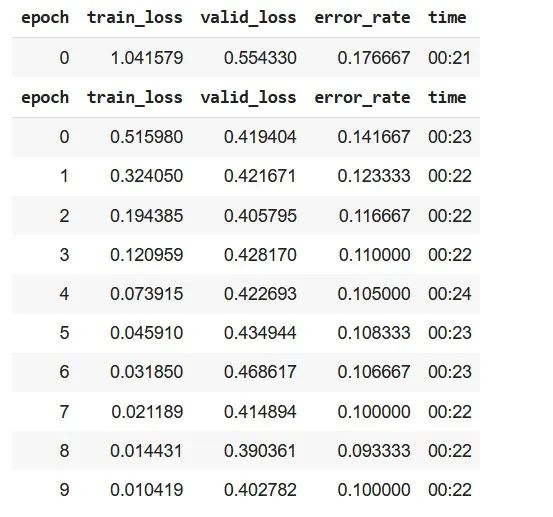
Fastai МṩБЛТ»ёцЎ°fineЈЯtuneЎұәҜКэЈ¬УГУЪөчХыФӨСөБ·ДЈРНЈ¬ТФК№УГОТГЗСЎФсөДКэҫЭҪвҫцОТГЗөДМШ¶ЁОКМвЎЈОӘБЛСөБ·ДЈРНЈ¬ОТГЗҪ« epoch КэЙиЦГОӘ 10ЎЈ
learn ЈҪ visionЈЯlearnerЈЁdlsЈ¬ resnet34Ј¬ metricsЈҪerrorЈЯrateЈ¬ pretrainedЈҪTrueЈ©
learnЈ®fineЈЯtuneЈЁepochsЈҪ10Ј©
ТІҝЙТФНЁ№эҪ«ЦёұкМж»»ОӘЎ°accuracyЎұАҙјмІйПаН¬ДЈРНөДЧјИ·РФЎЈ
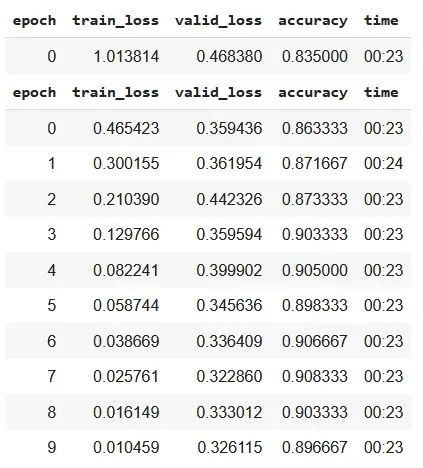
ҙУЙПГжөДҪб№ыЈ¬ОТГЗҝЙТФЛөЈ¬јҙК№Ц»УР 10 ёц epochЈ¬ФӨСөБ·өД ResNet34 ДЈРНФЪ¶аұкЗ©·ЦАаИООсЦРұнПЦіц Јҫ 85ЈҘ өДБјәГЧјИ·ВКЎЈИз№ыОТГЗФцјУ epoch өДКэБҝЈ¬ДЈРНөДЧјИ·РФҝЙДЬ»бМбёЯЎЈ
ПЦФЪЈ¬ИГОТГЗІвКФТ»Р©КҫАэНјПсАҙјмІйОТГЗөДДЈРНөДРФДЬЎЈ
КҫАэНјЖ¬ ЈЈ1

КҫАэНјЖ¬ ЈЈ2

КҫАэНјЖ¬ ЈЈ3

ҙУЙПГжөДҪб№ыЈ¬ОТГЗҝЙТФЛөОТГЗөДДЈРНДЬ№»ХэИ·К¶ұрСщұҫНјПсЎЈ
СөБ·ДЈРНәуЈ¬ОТГЗҝЙТФҪ«ЖдІҝКрОӘ Web УҰУГіМРт№©ЖдЛыИЛК№УГЎЈҫЎ№Ь fastai ЦчТӘУГУЪДЈРНСөБ·Ј¬ө«ДгҝЙТФК№УГЎ°learnЈ®exportЎұәҜКэҝмЛЩөјіц PyTorch ДЈРНТФУГУЪЙъІъЎЈ
ҪбВЫ
ФЪұҫҪМіМЦРЈ¬ОТГЗС§П°БЛИзәОК№УГ»щУЪ PyTorch өД fastai №№ҪЁКіОпНјПс·ЦАаЖчЎЈҝЙТФК№УГ Heroku »т Netlify өИ·юОсІҝКрҙЛДЈРНЈ¬ТФК№ҙЛДЈРНҝЙУГЧч Web УҰУГіМРтЎЈ
ТФПВКЗұҫОДөДТ»Р©ЦчТӘДЪИЭЈә
ОТГЗҝЙТФК№УГ fastai ТФЧоЙЩөДҙъВлҪЁБўЙо¶ИС§П°ДЈРНЎЈТтҙЛЈ¬fastai К№өГК№УГ PyTorch ҪшРРЙо¶ИС§П°ИООсұдөГёьјУИЭТЧЎЈ
КіЖ··ЦАа¶ФУЪјЖЛг»ъКУҫхУҰУГАҙЛөКЗТ»ПоҫЯУРМфХҪРФөДИООсЈ¬ТтОӘёщҫЭЧ°КОәН№©УҰ·ҪКҪөДІ»Н¬Ј¬Н¬Т»ЦЦКіЖ·ФЪІ»Н¬өШ·ҪҝҙЖрАҙҝЙДЬ»бУРәЬҙуІоТмЎЈҫЎ№ЬИзҙЛЈ¬НЁ№эАыУГЗЁТЖС§П°өДБҰБҝЈ¬ОТГЗҝЙТФК№УГФӨСөБ·ДЈРНАҙК¶ұрКіЖ·Іў¶ФЖдҪшРРХэИ··ЦАаЎЈ
ОТГЗОӘҙЛ·ЦАаЖчК№УГБЛФӨСөБ·ДЈРН ResNet34ЎЈө«КЗЈ¬ДгҝЙТФК№УГЖдЛыФӨСөБ·ДЈРНЈ¬Из VGGЎўInceptionЎўDenseNet өИЈ¬Аҙ№№ҪЁДгЧФјәөДДЈРНЎЈ